[CVPR 2017] Semantic Autoencoder for Zero-Shot Learning论文笔记
Semantic Autoencoder for Zero-Shot Learning,Elyor Kodirov Tao Xiang Shaogang Gong,Queen Mary University of London, UK,{e.kodirov, t.xiang, s.gong}@qmul.ac.uk
亮点
- 通过对耦学习提升零次学习系统的性能(类似CycleGan)
- 结构非常简洁,且可直接求解,速度非常快
- 有效应用到其他相关任务(监督聚类)上,证明了范化性能
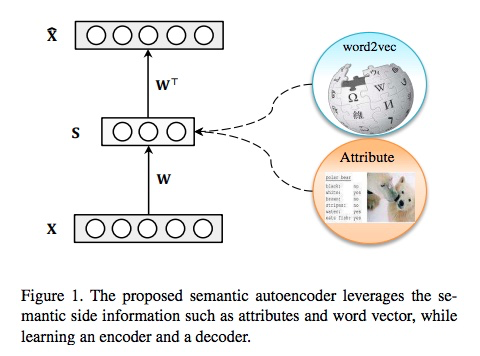
方法
Linear autoencoder

Model Formulation

which is a well-known Sylvester equation which can be solved efficiently by the Bartels-Stewart algorithm (matlab sylvester).
零次学习:基于以上算法有两种测试的方法:
- 将一个未知的类别特征样本xi通过W映射到语义空间(属性)si,通过比较语义空间的距离找到离它最近的类别(无训练样本),即为它的标签
- 将所有无训练数据类别的语义特征S通过WT映射到特征空间X,通过比较一个未知类别的样本xi和映射到特征空间的类别中心X的距离,找到离它最近的类别,即为它的标签
- 以上两种算法得到结果的准确度基本相同。
监督聚类:在这个问题中,语义空间即为类别标签空间(one-hot class label)。所有测试数据被影射到训练类别标签空间,然后使用k-means聚合
与已有模型的关系:零度学习已有模型一般学习一个满足以下条件的影射:
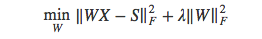
或者,在[54]中将属性影射到特征空间,学习目标变为,
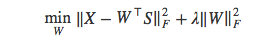
文中的算法结合了这两者,而且由于W*=WT,在对耦学习中W不可能太大(否则,x乘以两个范数很大的的矩阵无法恢复原来的初始值),正则化项可以被忽略。
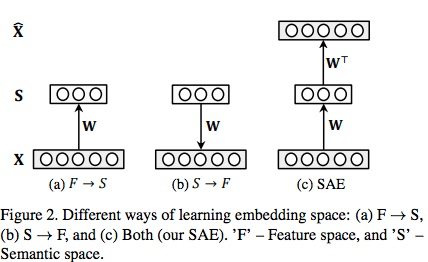
实验
零次学习
数据集:Semantic word vector representation is used for large-scale datasets (ImNet-1 and ImNet-2). We train a skip-gram text model on a corpus of 4.6M Wikipedia documents to obtain the word2vec2 [38, 37] word vectors.
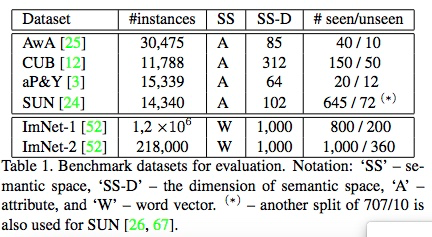
特征:除 ImNet-1用AlexNet提取外,其他均使用了GoogleNet
结果:
- Our SAE model achieves the best results on all 6 datasets.
- On the smallscale datasets, the gap between our model’s results to the strongest competitor ranges from 3.5% to 6.5%.
- On the large-scale datasets, the gaps are even bigger: On the largest ImNet-2, our model improves over the state-of-the-art SS-Voc [22] by 8.8%.
- Both the encoder and decoder projection functions in our SAE model (SAE (W) and SAE (WT) respectively) can be used for effective ZSL.
- The encoder projection function seems to be slightly better overall.
- Measures how well a zero-shot learning method can trade-off between recognising data from seen classes and that of unseen classes
- Holding out 20% of the data samples from the seen classes and mixing them with the samples from the unseen classes.
- On AwA, our model is slightly worse than the SynCstruct [13].
- However, on the more challenging CUB dataset, our method significantly outperforms the competitors.
聚类
数据集: A synthetic dataset and Oxford Flowers-17 (848 images)
结果:
- On computational cost, our model (93s) is more expensive than MLCA (39%) but much better than all others (hours~days).
- Achieves the best clustering accuracy
p.p1 { margin: 0.0px 0.0px 0.0px 0.0px; font: 14.0px "Helvetica Neue"; color: #042eee }
p.p2 { margin: 0.0px 0.0px 0.0px 0.0px; font: 16.0px "Helvetica Neue"; color: #323333 }
p.p3 { margin: 0.0px 0.0px 0.0px 0.0px; font: 14.0px "Helvetica Neue"; color: #323333 }
p.p4 { margin: 0.0px 0.0px 0.0px 0.0px; font: 14.0px "Helvetica Neue"; color: #323333; min-height: 16.0px }
p.p5 { margin: 0.0px 0.0px 0.0px 0.0px; font: 17.0px STIXGeneral; color: #323333 }
p.p6 { margin: 0.0px 0.0px 0.0px 0.0px; font: 12.0px STIXGeneral; color: #323333 }
p.p7 { margin: 0.0px 0.0px 0.0px 0.0px; font: 9.0px STIXGeneral; color: #323333 }
p.p8 { margin: 0.0px 0.0px 0.0px 0.0px; text-align: center; font: 17.0px STIXGeneral; color: #323333 }
p.p9 { margin: 0.0px 0.0px 0.0px 0.0px; text-align: center; font: 17.0px "Helvetica Neue"; color: #323333; min-height: 20.0px }
p.p10 { margin: 0.0px 0.0px 0.0px 0.0px; text-align: center; font: 19.0px STIXSizeOneSym; color: #323333 }
p.p11 { margin: 0.0px 0.0px 0.0px 0.0px; font: 14.0px "Helvetica Neue"; color: #323333; min-height: 17.0px }
li.li3 { margin: 0.0px 0.0px 0.0px 0.0px; font: 14.0px "Helvetica Neue"; color: #323333 }
span.s1 { text-decoration: underline }
span.s2 { }
span.s3 { font: 19.0px STIXSizeOneSym }
ul.ul1 { list-style-type: disc }
ul.ul2 { list-style-type: circle }
[CVPR 2017] Semantic Autoencoder for Zero-Shot Learning论文笔记的更多相关文章
- Spectral Norm Regularization for Improving the Generalizability of Deep Learning论文笔记
Spectral Norm Regularization for Improving the Generalizability of Deep Learning论文笔记 2018年12月03日 00: ...
- Deep Learning论文笔记之(四)CNN卷积神经网络推导和实现(转)
Deep Learning论文笔记之(四)CNN卷积神经网络推导和实现 zouxy09@qq.com http://blog.csdn.net/zouxy09 自己平时看了一些论文, ...
- Deep Learning论文笔记之(八)Deep Learning最新综述
Deep Learning论文笔记之(八)Deep Learning最新综述 zouxy09@qq.com http://blog.csdn.net/zouxy09 自己平时看了一些论文,但老感觉看完 ...
- Deep Learning论文笔记之(六)Multi-Stage多级架构分析
Deep Learning论文笔记之(六)Multi-Stage多级架构分析 zouxy09@qq.com http://blog.csdn.net/zouxy09 自己平时看了一些 ...
- Deep Learning论文笔记之(一)K-means特征学习
Deep Learning论文笔记之(一)K-means特征学习 zouxy09@qq.com http://blog.csdn.net/zouxy09 自己平时看了一些论文,但老感 ...
- Deep Learning论文笔记之(三)单层非监督学习网络分析
Deep Learning论文笔记之(三)单层非监督学习网络分析 zouxy09@qq.com http://blog.csdn.net/zouxy09 自己平时看了一些论文,但老感 ...
- PredNet --- Deep Predictive coding networks for video prediction and unsupervised learning --- 论文笔记
PredNet --- Deep Predictive coding networks for video prediction and unsupervised learning ICLR 20 ...
- Correlation Filter in Visual Tracking系列二:Fast Visual Tracking via Dense Spatio-Temporal Context Learning 论文笔记
原文再续,书接一上回.话说上一次我们讲到了Correlation Filter类 tracker的老祖宗MOSSE,那么接下来就让我们看看如何对其进一步地优化改良.这次要谈的论文是我们国内Zhang ...
- Deep Learning论文笔记之(四)CNN卷积神经网络推导和实现
https://blog.csdn.net/zouxy09/article/details/9993371 自己平时看了一些论文,但老感觉看完过后就会慢慢的淡忘,某一天重新拾起来的时候又好像没有看过一 ...
随机推荐
- 10_Android中通过HttpUrlConnection访问网络,Handler和多线程使用,读取网络html代码并显示在界面上,ScrollView组件的使用
编写如下项目: 2 编写Android清单文件 <?xml version="1.0" encoding="utf-8"?> <mani ...
- 《java入门第一季》之Arrays类前传(排序问题)
一:冒泡排序 /* * 数组排序之冒泡排序: * 相邻元素两两比较,大的往后放,第一次完毕,最大值出现在了最大索引处 * * 引申: * 利用冒泡排序法,可以获取一个数组的最大值(先冒泡排序,取最后一 ...
- 【云计算 Hadoop】Hadoop 版本 生态圈 MapReduce模型
忘的差不多了, 先补概念, 然后开始搭建集群实战 ... . 一 Hadoop版本 和 生态圈 1. Hadoop版本 (1) Apache Hadoop版本介绍 Apache的开源项目开发流程 : ...
- MT6575 充电流程
1,目前充电主要包括Power Off Charging(关机充电) .IPO Charging(休眠充电)和 OS Charging(开机充电) 三个部分 2,Power Off Charging ...
- LeetCode之“数组”:Rotate Array
题目链接 题目要求: Rotate an array of n elements to the right by k steps. For example, with n = 7 and k = 3, ...
- 单片机驱动AT24C02存储芯片
AT24C02是一个2K位串行CMOS E2PROM, 内部含有256个8位字节,CATALYST公司的先进CMOS技术实质上减少了器件的功耗.AT24C02有一个8字节页写缓冲器.该器件通过IIC总 ...
- 基于condition 实现的线程安全的优先队列(python实现)
可以把Condiftion理解为一把高级的琐,它提供了比Lock, RLock更高级的功能,允许我们能够控制复杂的线程同步问题.threadiong.Condition在内部维护一个琐对象(默认是RL ...
- MOOS学习笔记——多线程
/* * A simple example showing how to use a comms client */ #include "MOOS/libMOOS/Comms/MOOSAsy ...
- VueJs(5)---V-bind指令
V-bind指令 一.概述 v-bind 主要用于属性绑定,比方你的class属性,style属性,value属性,href属性等等,只要是属性,就可以用v-bind指令进行绑定. 示例: < ...
- 代理网络中安装tomcat的注意事项
搭建J2EE开发环境的时候,tomcat怎么都没办法访问主页面.主要的问题就是Network Error (tcp_error) 百度了半天也没搞明白,最后没办法,打算重装tomcat,便对照完整的安 ...