距离度量以及python实现(二)
接上一篇:http://www.cnblogs.com/denny402/p/7027954.html
7. 夹角余弦(Cosine)
也可以叫余弦相似度。 几何中夹角余弦可用来衡量两个向量方向的差异,机器学习中借用这一概念来衡量样本向量之间的差异。
(1)在二维空间中向量A(x1,y1)与向量B(x2,y2)的夹角余弦公式:
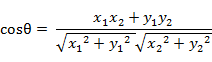
(2) 两个n维样本点a(x11,x12,…,x1n)和b(x21,x22,…,x2n)的夹角余弦
类似的,对于两个n维样本点a(x11,x12,…,x1n)和b(x21,x22,…,x2n),可以使用类似于夹角余弦的概念来衡量它们间的相似程度。
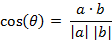
即:
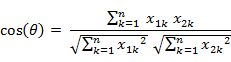
余弦取值范围为[-1,1]。求得两个向量的夹角,并得出夹角对应的余弦值,此余弦值就可以用来表征这两个向量的相似性。夹角越小,趋近于0度,余弦值越接近于1,它们的方向更加吻合,则越相似。当两个向量的方向完全相反夹角余弦取最小值-1。当余弦值为0时,两向量正交,夹角为90度。因此可以看出,余弦相似度与向量的幅值无关,只与向量的方向相关。
import numpy as np
x=np.random.random(10)
y=np.random.random(10) #方法一:根据公式求解
d1=np.dot(x,y)/(np.linalg.norm(x)*np.linalg.norm(y)) #方法二:根据scipy库求解
from scipy.spatial.distance import pdist
X=np.vstack([x,y])
d2=1-pdist(X,'cosine')
两个向量完全相等时,余弦值为1,如下的代码计算出来的d=1。
d=1-pdist([x,x],'cosine')
8. 皮尔逊相关系数(Pearson correlation)
(1) 皮尔逊相关系数的定义
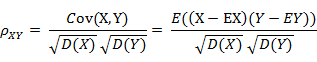
前面提到的余弦相似度只与向量方向有关,但它会受到向量的平移影响,在夹角余弦公式中如果将 x 平移到 x+1, 余弦值就会改变。怎样才能实现平移不变性?这就要用到皮尔逊相关系数(Pearson correlation),有时候也直接叫相关系数。
如果将夹角余弦公式写成:
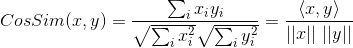
表示向量x和向量y之间的夹角余弦,则皮尔逊相关系数则可表示为:
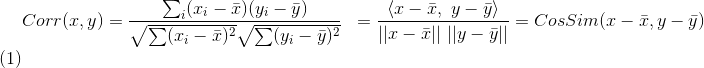
皮尔逊相关系数具有平移不变性和尺度不变性,计算出了两个向量(维度)的相关性。
在python中的实现:
import numpy as np
x=np.random.random(10)
y=np.random.random(10) #方法一:根据公式求解
x_=x-np.mean(x)
y_=y-np.mean(y)
d1=np.dot(x_,y_)/(np.linalg.norm(x_)*np.linalg.norm(y_)) #方法二:根据numpy库求解
X=np.vstack([x,y])
d2=np.corrcoef(X)[0][1]
相关系数是衡量随机变量X与Y相关程度的一种方法,相关系数的取值范围是[-1,1]。相关系数的绝对值越大,则表明X与Y相关度越高。当X与Y线性相关时,相关系数取值为1(正线性相关)或-1(负线性相关)。
9. 汉明距离(Hamming distance)
(1)汉明距离的定义
两个等长字符串s1与s2之间的汉明距离定义为将其中一个变为另外一个所需要作的最小替换次数。例如字符串“1111”与“1001”之间的汉明距离为2。
应用:信息编码(为了增强容错性,应使得编码间的最小汉明距离尽可能大)。
在python中的实现:
import numpy as np
from scipy.spatial.distance import pdist
x=np.random.random(10)>0.5
y=np.random.random(10)>0.5 x=np.asarray(x,np.int32)
y=np.asarray(y,np.int32) #方法一:根据公式求解
d1=np.mean(x!=y) #方法二:根据scipy库求解
X=np.vstack([x,y])
d2=pdist(X,'hamming')
10. 杰卡德相似系数(Jaccard similarity coefficient)
(1) 杰卡德相似系数
两个集合A和B的交集元素在A,B的并集中所占的比例,称为两个集合的杰卡德相似系数,用符号J(A,B)表示。
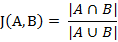
杰卡德相似系数是衡量两个集合的相似度一种指标。
(2) 杰卡德距离
与杰卡德相似系数相反的概念是杰卡德距离(Jaccard distance)。杰卡德距离可用如下公式表示:
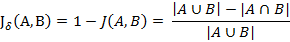
杰卡德距离用两个集合中不同元素占所有元素的比例来衡量两个集合的区分度。
(3) 杰卡德相似系数与杰卡德距离的应用
可将杰卡德相似系数用在衡量样本的相似度上。
样本A与样本B是两个n维向量,而且所有维度的取值都是0或1。例如:A(0111)和B(1011)。我们将样本看成是一个集合,1表示集合包含该元素,0表示集合不包含该元素。
在python中的实现:
import numpy as np
from scipy.spatial.distance import pdist
x=np.random.random(10)>0.5
y=np.random.random(10)>0.5 x=np.asarray(x,np.int32)
y=np.asarray(y,np.int32) #方法一:根据公式求解
up=np.double(np.bitwise_and((x != y),np.bitwise_or(x != 0, y != 0)).sum())
down=np.double(np.bitwise_or(x != 0, y != 0).sum())
d1=(up/down) #方法二:根据scipy库求解
X=np.vstack([x,y])
d2=pdist(X,'jaccard')
11. 布雷柯蒂斯距离(Bray Curtis Distance)
Bray Curtis距离主要用于生态学和环境科学,计算坐标之间的距离。该距离取值在[0,1]之间。它也可以用来计算样本之间的差异。
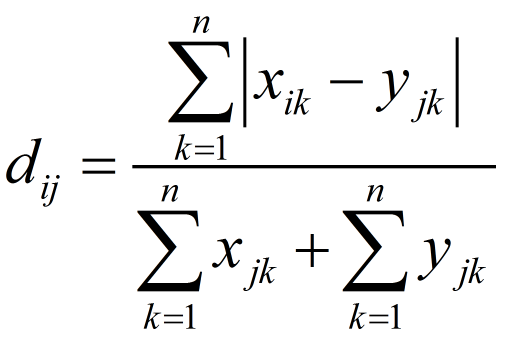
样本数据:
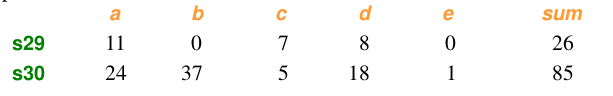
计算:
在python中的实现:
import numpy as np
from scipy.spatial.distance import pdist
x=np.array([11,0,7,8,0])
y=np.array([24,37,5,18,1]) #方法一:根据公式求解
up=np.sum(np.abs(y-x))
down=np.sum(x)+np.sum(y)
d1=(up/down) #方法二:根据scipy库求解
X=np.vstack([x,y])
d2=pdist(X,'braycurtis')
距离度量以及python实现(二)的更多相关文章
- 概率分布之间的距离度量以及python实现(四)
1.f 散度(f-divergence) KL-divergence 的坏处在于它是无界的.事实上KL-divergence 属于更广泛的 f-divergence 中的一种. 如果P和Q被定义成空间 ...
- 距离度量以及python实现(一)
1. 欧氏距离(Euclidean Distance) 欧氏距离是最易于理解的一种距离计算方法,源自欧氏空间中两点间的距离公式. (1)二维平面上两点a(x1,y1)与b(x2,y2)间 ...
- 概率分布之间的距离度量以及python实现(三)
概率分布之间的距离,顾名思义,度量两组样本分布之间的距离 . 1.卡方检验 统计学上的χ2统计量,由于它最初是由英国统计学家Karl Pearson在1900年首次提出的,因此也称之为Pearson ...
- 概率分布之间的距离度量以及python实现
1. 欧氏距离(Euclidean Distance) 欧氏距离是最易于理解的一种距离计算方法,源自欧氏空间中两点间的距离公式.(1)二维平面上两点a(x1,y1)与b(x2,y2)间的欧 ...
- ML 07、机器学习中的距离度量
机器学习算法 原理.实现与实践 —— 距离的度量 声明:本篇文章内容大部分转载于July于CSDN的文章:从K近邻算法.距离度量谈到KD树.SIFT+BBF算法,对内容格式与公式进行了重新整理.同时, ...
- 机器学习方法、距离度量、K_Means
特征向量 1.特征向量:以人为例,每个元素可能就对应这人的某些方面,这就是特征,例如:身高.年龄.性别.国际....2.特征工程:目的就是将现有数据中可作为信号的特征与那些仅是噪声的特征区分开来:当数 ...
- <转>从K近邻算法、距离度量谈到KD树、SIFT+BBF算法
转自 http://blog.csdn.net/likika2012/article/details/39619687 前两日,在微博上说:“到今天为止,我至少亏欠了3篇文章待写:1.KD树:2.神经 ...
- 从K近邻算法、距离度量谈到KD树、SIFT+BBF算法
转载自:http://blog.csdn.net/v_july_v/article/details/8203674/ 从K近邻算法.距离度量谈到KD树.SIFT+BBF算法 前言 前两日,在微博上说: ...
- 使用 Python 生成二维码
在“一带一路”国际合作高峰论坛举行期间, 20 国青年投票选出中国的“新四大发明”:高铁.扫码支付.共享单车和网购.其中扫码支付指手机通过扫描二维码跳转到支付页面,再进行付款.这种新的支付方式,造就二 ...
随机推荐
- 使用Navicat for MySQL把本地数据库上传到服务器
服务器系统基本都是基于linux的,这个数据库上传的方式适用于linux的各种版本,比如Ubuntu和Centos(尽管这两个版本各种大坑小坑,但至少在数据库传输上保持了一致性) 当然本地数据库上传到 ...
- [ASP.NET MVC] Controlle中的Aciton方法数据接收方式
POST数据接收方式包括: 1.request.Form:(逐个获取表单提交的数据); FormCollection: [HttpPost]public async Task<string> ...
- Vue.js与Jquery的比较 谁与争锋 js风暴
普遍认为jQuery是适合web初学者的起步工具.许多人甚至在学习jQuery之前,他们已经学习了一些轻量JavaScript知识.为什么?部分是因为jQuery的流行,但主要是源于经验开发人员的一个 ...
- 提高Maven下载jar包的速度
1.提高Maven下载jar包的速度 打开项目所配置的maven包下conf目录下的settings.xml 找到 <mirrors>标签添加一下内容: 1 <!-- 阿里云仓库 ...
- 12.Django思维导图
- Robot framework(RF) 用户关键字
3.6 用户关键字 在Robot Framework 中关键字的创建分两种:系统关键字和用户关键字. 系统关键字是需要通过脚本开发相应的类和方法,从而实现某一逻辑功能. 用户关键字是根据业务的需求利 ...
- Hibernate Session总结
现在我们可以在 IDEA 下新建一个 Hibernate 项目,接着上次内容这次主要总结一下 Hibernate 的 Session,及其核心方法. Session 概述 Session 接口是 Hi ...
- Java Persistence/ManyToMany
A ManyToMany relationship in Java is where the source object has an attribute that stores a collecti ...
- 我们的java基础到底有多差 一个视频引发的感想
以此文来警示自己. 大三要结束了. 我从大一下学期开始接触java,两年半了,期间有很努力的自学,也参与了一下项目,满以为自己的java基础应该不错,但今天在网上看了一个视频才发现自己学的是多么的&q ...
- Spring Security Oauth2 permitAll()方法小记
黄鼠狼在养鸡场山崖边立了块碑,写道:"不勇敢地飞下去,你怎么知道自己原来是一只搏击长空的鹰?!" 从此以后 黄鼠狼每天都能在崖底吃到那些摔死的鸡! 前言 上周五有网友问道,在使用s ...