Kafka概述(一)
一、消息队列
客户端A给客户端B发送数据,若是直接发的话,客户端A给客户端B需要同步。
例如,
1) A在给B发送数据的时候,B挂掉了,此时的A是没有办法给B发送数据的;
2) A发送10M/s,而B只能5M/s进行接收,直接发送会导致数据丢失。
因而,中间需要一个缓存,A发送的数据不直接发送给B,而是传给消息队列,B再从消息队列中获取数据。
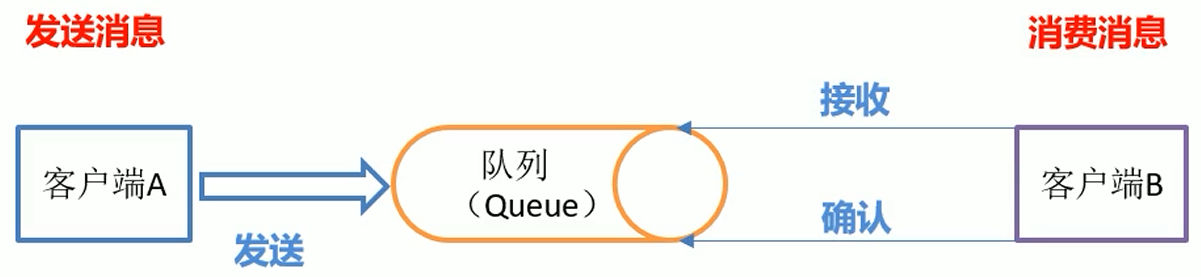
消息队列内部实现原理:
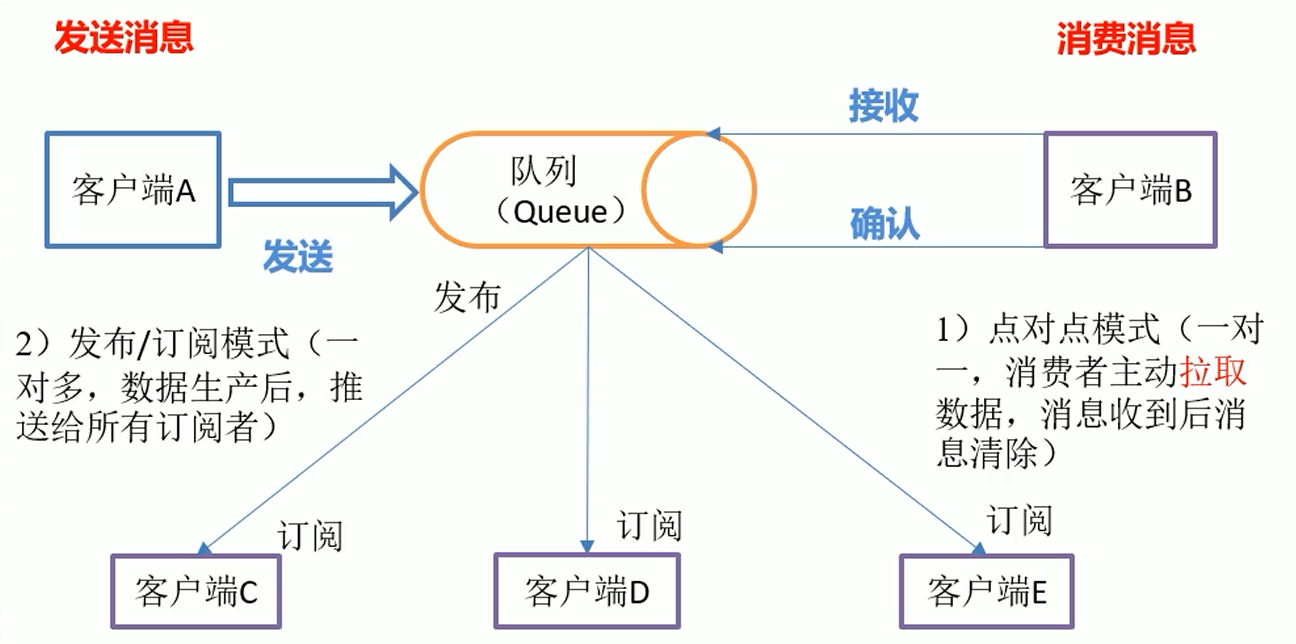
客户端B接收消息有如下两种模式:
(1)点对点模式(一对一,消费者主动拉取数据,消息收到后消息清除)
点对点模型通常是一个基于拉取或者轮询的消息传送模型,这种模型从队列中请求信息,而不是将消息推送到客户端。这个模型的特点是发送到队列的消息被一个且只有一个接收者接收处理,即使有多个消息监听者也是如此。此外,客户端B需要有一个线程实时监控消息队列,有数据再进行接收。
(2)发布/订阅模式(一对多,数据生产后,推送给所有订阅者)
发布订阅模型则是一个基于推送的消息传送模型。发布订阅模型可以有多种不同的订阅者,临时订阅者只在主动监听主题时才接收消息,而持久订阅者则监听主题的所有消息,即使当前订阅者不可用,处于离线状态。缺点:消息队列只能以固定的速度向定于这发送消息,对于不同的接收客户端,可能会因为接收数据的速率而造成资源的浪费。
二、为什么需要消息队列?
1)解耦:
允许你独立的扩展或修改两边的处理过程,只要确保它们遵守同样的接口约束。简单理解,就是A和B不直接相连了。
2)冗余:
消息队列把数据进行持久化直到它们已经被完全处理,通过这一方式规避了数据丢失风险。许多消息队列所采用的"插入-获取-删除"范式中,在把一个消息从队列中删除之前,需要你的处理系统明确的指出该消息已经被处理完毕,从而确保你的数据被安全的保存直到你使用完毕。
也就是说,可以将数据进行备份。
3)扩展性:
因为消息队列解耦了你的处理过程,所以增大消息入队和处理的频率是很容易的,只要另外增加处理过程即可。
4)灵活性 & 峰值处理能力:
在访问量剧增的情况下,应用仍然需要继续发挥作用,但是这样的突发流量并不常见。如果为以能处理这类峰值访问为标准来投入资源随时待命无疑是巨大的浪费。使用消息队列能够使关键组件顶住突发的访问压力,而不会因为突发的超负荷的请求而完全崩溃。
5)可恢复性:
系统的一部分组件失效时,不会影响到整个系统。消息队列降低了进程间的耦合度,所以即使一个处理消息的进程挂掉,加入队列中的消息仍然可以在系统恢复后被处理。
6)顺序保证:
在大多使用场景下,数据处理的顺序都很重要。大部分消息队列本来就是排序的,并且能保证数据会按照特定的顺序来处理。(Kafka保证一个Partition内的消息的有序性)
队列先进先出的特性,保证数据的顺序性。
7)缓冲:
有助于控制和优化数据流经过系统的速度,解决生产消息和消费消息的处理速度不一致的情况。
8)异步通信:
很多时候,用户不想也不需要立即处理消息。消息队列提供了异步处理机制,允许用户把一个消息放入队列,但并不立即处理它。想向队列中放入多少消息就放多少,然后在需要的时候再去处理它们。
三、什么是kafka?
在流式计算中,Kafka一般用来缓存数据,Storm通过消费Kafka的数据进行计算。
1)Apache Kafka是一个开源消息系统,由Scala写成。是由Apache软件基金会开发的一个开源消息系统项目。
2)Kafka最初是由LinkedIn公司开发,并于2011年初开源。2012年10月从Apache Incubator毕业。该项目的目标是为处理实时数据提供一个统一、高通量、低等待的平台。
3)Kafka是一个分布式消息队列。Kafka对消息保存时根据Topic进行归类,发送消息者称为Producer,消息接受者称为Consumer,此外kafka集群有多个kafka实例组成,每个实例(server)称为broker。
4)无论是kafka集群,还是consumer都依赖于zookeeper集群保存一些meta信息,来保证系统可用性。
四、kafka架构

Kafka详细架构图
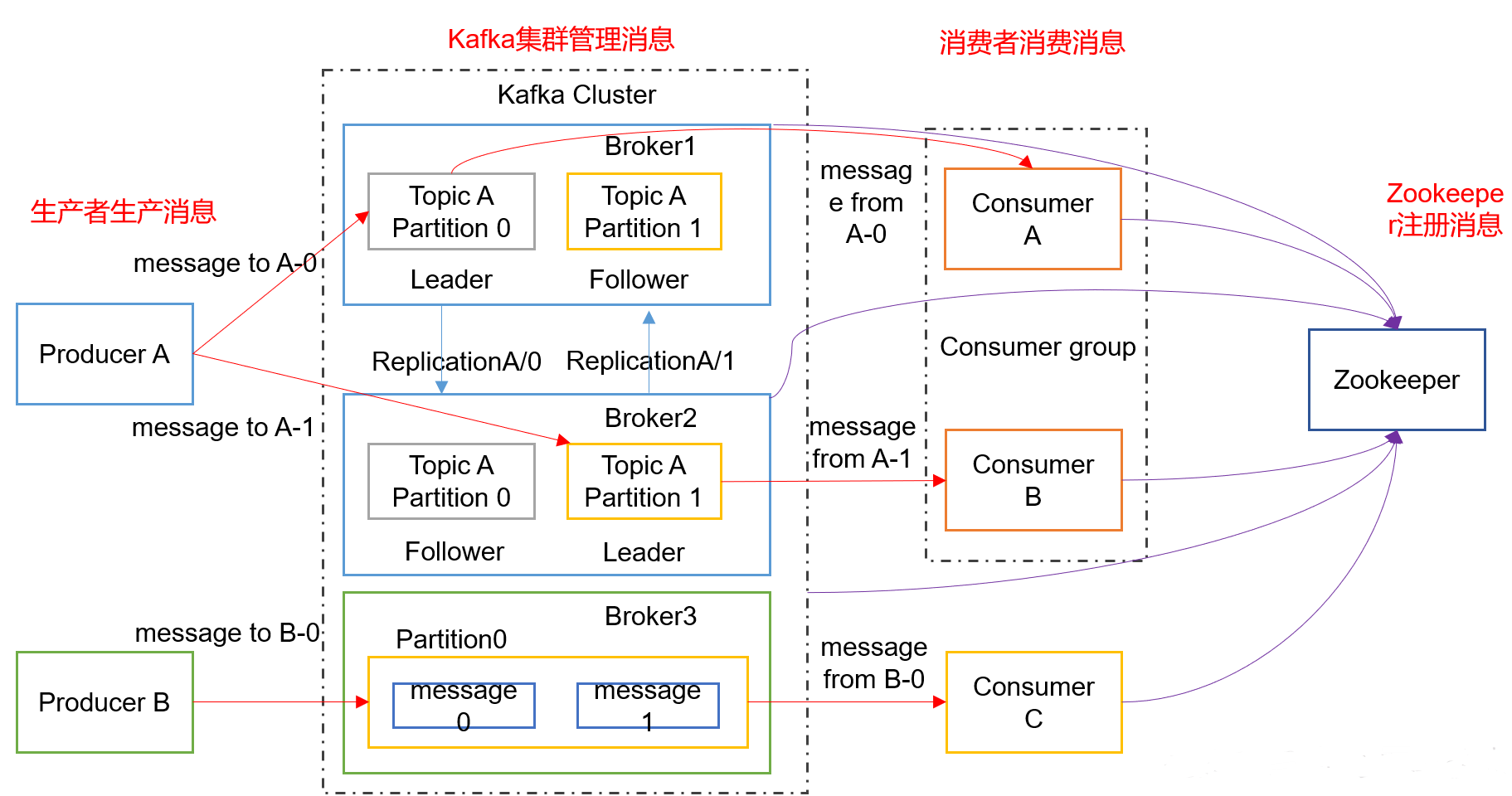
1)Producer :消息生产者,就是向kafka broker发消息的客户端;
2)Consumer :消息消费者,向kafka broker取消息的客户端;
3)Topic :可以理解为一个队列;
4) Consumer Group (CG):这是kafka用来实现一个topic消息的广播(发给所有的consumer)和单播(发给任意一个consumer)的手段。一个topic可以有多个CG。topic的消息会复制(不是真的复制,是概念上的)到所有的CG,但每个partion只会把消息发给该CG中的一个consumer。如果需要实现广播,只要每个consumer有一个独立的CG就可以了。要实现单播只要所有的consumer在同一个CG。用CG还可以将consumer进行自由的分组而不需要多次发送消息到不同的topic;
5)Broker :一台kafka服务器就是一个broker。一个集群由多个broker组成。一个broker可以容纳多个topic;
6)Partition:为了实现扩展性,一个非常大的topic可以分布到多个broker(即服务器)上,一个topic可以分为多个partition,每个partition是一个有序的队列。partition中的每条消息都会被分配一个有序的id(offset)。kafka只保证按一个partition中的顺序将消息发给consumer,不保证一个topic的整体(多个partition间)的顺序;
7)Offset:kafka的存储文件都是按照offset.kafka来命名,用offset做名字的好处是方便查找。例如你想找位于2049的位置,只要找到2048.kafka的文件即可。当然the first offset就是00000000000.kafka。
Kafka概述(一)的更多相关文章
- Kafka概述及安装部署
一.Kafka概述 1.Kafka是一个分布式流媒体平台,它有三个关键功能: (1)发布和订阅记录流,类似于消息队列或企业消息传递系统: (2)以容错的持久方式存储记录流: (3)记录发送时处理流. ...
- kafka概述
kafka概述 Apache Kafka是一个开源 消息 系统,由Scala写成.是由Apache软件基金会开发的一个开源消息系统项目. Kafka最初是由LinkedIn开发,并于2011年初开源. ...
- kafka学习汇总系列(一)kafka概述
一.kafka概述 在流式计算中,kafka是用来缓存数据的,storm通过消费kafka的数据进行计算.kafka的初心是,为处理实时数据提供一个统一.高通量.低等待的平台: 1.kafka是一个分 ...
- Kafka概述与设计原理
kafka是一种高吞吐量的分布式发布订阅消息系统,有如下特性: 1. 通过O(1)的磁盘数据结构提供消息的持久化,这种结构对于即使数以TB的消息存储也能够保持长时间的稳定性能. 2 .高吞吐量:即使是 ...
- Apache Kafka 概述
kafka教程,完全参照w3school: https://www.w3cschool.cn/apache_kafka/apache_kafka-dac11yot.html 以下是入门学习过程中摘录的 ...
- kafka概述与下一代消息队列
常用的消息中间件 消息中间件是当前处理大数据的一个非常重要的组件,用来解决应用解耦.异步通信.流量控制等问题,从而构建一个高效.灵活.消息同步和异步传输处理.存储转发.可伸缩和最终一致性的稳定系统.目 ...
- 1、kafka概述
一.关于消息队列 消息队列是一种应用间的通信方式,消息就是是指在应用之间传送的数据,它也是进程通信的一种重要的方式. 1.消息队列的基本架构 producer:消息生产者. broker:消息处理中心 ...
- Kafka 概述
Kafka 是一个分布式的基于发布/订阅模式的消息队列(Message Queue),主要应用于大数据实时处理领域. Kafka 中,客户端和服务器之间的通信是通过 TCP 协议完成的. 一.传统消息 ...
- Kafka(一)【概述、入门、架构原理】
目录 一.Kafka概述 1.1 定义 二.Kafka快速入门 2.1 安装部署 2.2 配置文件解析 2.3Kafka群起脚本 2.4 topic(增删改查) 2.5 生产和消费者命令行操作 三.K ...
随机推荐
- MySQL集群架构:MHA+MySQL-PROXY+LVS实现MySQL集群架构高可用/高性能-技术流ken
MHA简介 MHA可以自动化实现主服务器故障转移,这样就可以快速将从服务器晋级为主服务器(通常在10-30s),而不影响复制的一致性,不需要花钱买更多的新服务器,不会有性能损耗,容易安装,不必更改现有 ...
- DS控件库 在Combobox中嵌入远程桌面
本示例演示DS开放式下拉列表控件中加入一个RDP远程桌面控件. 先在VS工具箱中添加COM控件Microsoft RDP Client Control,后面的Version版本可以适当高点. 然后将R ...
- &,^,|,的简化计算与理解
(全部和2进制有关 , 凡是2的次方数都是独立数列,都要先分解再计算的,该计算方式仅供手工计算理解,电脑会自动进行换算的) (第二个等号后面为2进制的结果,不够位在前面补0,1为真,0为假) A^ ...
- MySQL 笔记整理(13) --为什么数据表删掉一半,表文件大小不变?
笔记记录自林晓斌(丁奇)老师的<MySQL实战45讲> (本篇内图片均来自丁奇老师的讲解,如有侵权,请联系我删除) 13) --为什么数据表删掉一半,表文件大小不变? 我们还是以MySQL ...
- The openssl extension is required for SSL/TLS protection but is not available
今天使用composer update发现报错:The openssl extension is required for SSL/TLS protection but is not availabl ...
- 备忘录模式 Memento 快照模式 标记Token模式 行为型 设计模式(二十二)
备忘录模式 Memento 沿着脚印,走过你来时的路,回到原点. 苦海翻起爱恨 在世间难逃避命运 相亲竟不可接近 或我应该相信是缘份 一首<一生所爱>触动了多少 ...
- 003. 什么是 正向代理 & 反向代理
正向代理: 客户端的代理: 反向代理: 服务端的代理:
- Hacking Bsides Vancouver 2018 walkthrough
概述: Name: BSides Vancouver: 2018 (Workshop) Date release: 21 Mar 2018 Author: abatchy Series: BSides ...
- Jmeter简单回顾
之前公众号推文一上手就分享如何测接口, 其实忽略了一些概念性的东西, 今天来给大家拾遗补缺, 做个回顾吧. 一. JMeter介绍 jmeter能做什么,来自官网的解释: Ability to loa ...
- js坚持不懈之17:onmousedown、onmouseup 以及 onclick 事件
<!DOCTYPE html> <html> <body> <div onmouseover = "mOver(this)" onmous ...