利用 Scrapy 爬取知乎用户信息
思路:通过获取知乎某个大V的关注列表和被关注列表,查看该大V和其关注用户和被关注用户的详细信息,然后通过层层递归调用,实现获取关注用户和被关注用户的关注列表和被关注列表,最终实现获取大量用户信息。
一、新建一个scrapy项目
scrapy startproject zhihuuser
移动到新建目录下:
cd zhihuuser
新建spider项目:
scrapy genspider zhihu zhihu.com
二、这里以爬取知乎大V轮子哥的用户信息来实现爬取知乎大量用户信息。
a) 定义 spdier.py 文件(定义爬取网址,爬取规则等):
# -*- coding: utf-8 -*-
import json from scrapy import Spider, Request from zhihuuser.items import UserItem class ZhihuSpider(Spider):
name = 'zhihu'
allowed_domains = ['zhihu.com']
start_urls = ['http://zhihu.com/']
#自定义爬取网址
start_user = 'excited-vczh'
user_url = 'https://www.zhihu.com/api/v4/members/{user}?include={include}'
user_query = 'allow_message,is_followed,is_following,is_org,is_blocking,employments,answer_count,follower_count,articles_count,gender,badge[?(type=best_answerer)].topics'
follows_url = 'https://www.zhihu.com/api/v4/members/{user}/followees?include={include}&offset={offset}&limit={limit}'
follows_query = 'data[*].answer_count,articles_count,gender,follower_count,is_followed,is_following,badge[?(type=best_answerer)].topics' followers_url = 'https://www.zhihu.com/api/v4/members/{user}/followees?include={include}&offset={offset}&limit={limit}'
followers_query = 'data[*].answer_count,articles_count,gender,follower_count,is_followed,is_following,badge[?(type=best_answerer)].topics'
#定义请求爬取用户信息、关注用户和被关注用户的函数
def start_requests(self):
yield Request(self.user_url.format(user=self.start_user, include=self.user_query), callback=self.parseUser)
yield Request(self.follows_url.format(user=self.start_user, include=self.follows_query, offset=0, limit=20), callback=self.parseFollows)
yield Request(self.followers_url.format(user=self.start_user, include=self.followers_query, offset=0, limit=20), callback=self.parseFollowers) #请求爬取用户详细信息
def parseUser(self, response):
result = json.loads(response.text)
item = UserItem() for field in item.fields:
if field in result.keys():
item[field] = result.get(field)
yield item
#定义回调函数,爬取关注用户与被关注用户的详细信息,实现层层迭代
yield Request(self.follows_url.format(user=result.get('url_token'), include=self.follows_query, offset=0, limit=20), callback=self.parseFollows)
yield Request(self.followers_url.format(user=result.get('url_token'), include=self.followers_query, offset=0, limit=20), callback=self.parseFollowers) #爬取关注者列表
def parseFollows(self, response):
results = json.loads(response.text) if 'data' in results.keys():
for result in results.get('data'):
yield Request(self.user_url.format(user=result.get('url_token'), include=self.user_query), callback=self.parseUser) if 'paging' in results.keys() and results.get('paging').get('is_end') == False:
next_page = results.get('paging').get('next')
yield Request(next_page, callback=self.parseFollows) #爬取被关注者列表
def parseFollowers(self, response):
results = json.loads(response.text) if 'data' in results.keys():
for result in results.get('data'):
yield Request(self.user_url.format(user=result.get('url_token'), include=self.user_query), callback=self.parseUser) if 'paging' in results.keys() and results.get('paging').get('is_end') == False:
next_page = results.get('paging').get('next')
yield Request(next_page, callback=self.parseFollowers)
b) 定义 items.py 文件(定义爬取数据的信息,使其规整等):
# -*- coding: utf-8 -*- # Define here the models for your scraped items
#
# See documentation in:
# https://doc.scrapy.org/en/latest/topics/items.html from scrapy import Field, Item class UserItem(Item):
# define the fields for your item here like:
# name = scrapy.Field()
allow_message = Field()
answer_count = Field()
articles_count = Field()
avatar_url = Field()
avatar_url_template = Field()
badge = Field()
employments = Field()
follower_count = Field()
gender = Field()
headline = Field()
id = Field()
name = Field()
type = Field()
url = Field()
url_token = Field()
user_type = Field()
c) 定义 pipelines.py 文件(存储数据到MongoDB):
# -*- coding: utf-8 -*- # Define your item pipelines here
#
# Don't forget to add your pipeline to the ITEM_PIPELINES setting
# See: https://doc.scrapy.org/en/latest/topics/item-pipeline.html
import pymongo #存储到MongoDB
class MongoPipeline(object): collection_name = 'users' def __init__(self, mongo_uri, mongo_db):
self.mongo_uri = mongo_uri
self.mongo_db = mongo_db @classmethod
def from_crawler(cls, crawler):
return cls(
mongo_uri=crawler.settings.get('MONGO_URI'),
mongo_db=crawler.settings.get('MONGO_DATABASE')
) def open_spider(self, spider):
self.client = pymongo.MongoClient(self.mongo_uri)
self.db = self.client[self.mongo_db] def close_spider(self, spider):
self.client.close() def process_item(self, item, spider):
self.db[self.collection_name].update({'url_token': item['url_token']}, dict(item), True) #执行去重操作
return item
d) 定义settings.py 文件(开启MongoDB、定义请求头、不遵循 robotstxt 规则):
# -*- coding: utf-8 -*-
BOT_NAME = 'zhihuuser' SPIDER_MODULES = ['zhihuuser.spiders'] # Obey robots.txt rules
ROBOTSTXT_OBEY = False #是否遵守robotstxt规则,限制爬取内容。 # Override the default request headers(加载请求头):
DEFAULT_REQUEST_HEADERS = {
'Accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8',
'Accept-Language': 'en',
'User-agent': 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_11_6) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/64.0.3282.140 Safari/537.36',
'authorization': 'oauth c3cef7c66a1843f8b3a9e6a1e3160e20'
} # Configure item pipelines
# See https://doc.scrapy.org/en/latest/topics/item-pipeline.html
ITEM_PIPELINES = {
'zhihuuser.pipelines.MongoPipeline': 300,
} MONGO_URI = 'localhost'
MONGO_DATABASE = 'zhihu'
三、开启爬取:
scrapy crawl zhihu
部分爬取过程中的信息
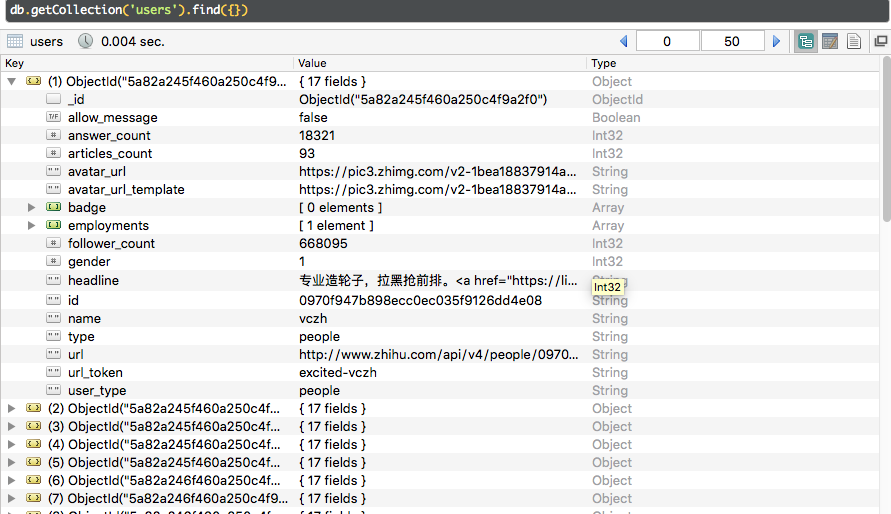
存储到MongoDB的部分信息:
利用 Scrapy 爬取知乎用户信息的更多相关文章
- 爬虫实战--利用Scrapy爬取知乎用户信息
思路: 主要逻辑图:
- 爬虫(十六):scrapy爬取知乎用户信息
一:爬取思路 首先我们应该找到一个账号,这个账号被关注的人和关注的人都相对比较多的,就是下图中金字塔顶端的人,然后通过爬取这个账号的信息后,再爬取他关注的人和被关注的人的账号信息,然后爬取被关注人的账 ...
- 基于webmagic的爬虫小应用--爬取知乎用户信息
听到“爬虫”,是不是第一时间想到Python/php ? 多少想玩爬虫的Java学习者就因为语言不通而止步.Java是真的不能做爬虫吗? 当然不是. 只不过python的3行代码能解决的问题,而Jav ...
- 使用python scrapy爬取知乎提问信息
前文介绍了python的scrapy爬虫框架和登录知乎的方法. 这里介绍如何爬取知乎的问题信息,并保存到mysql数据库中. 首先,看一下我要爬取哪些内容: 如下图所示,我要爬取一个问题的6个信息: ...
- Srapy 爬取知乎用户信息
今天用scrapy框架爬取一下所有知乎用户的信息.道理很简单,找一个知乎大V(就是粉丝和关注量都很多的那种),找到他的粉丝和他关注的人的信息,然后分别再找这些人的粉丝和关注的人的信息,层层递进,这样下 ...
- 利用Selenium爬取淘宝商品信息
一. Selenium和PhantomJS介绍 Selenium是一个用于Web应用程序测试的工具,Selenium直接运行在浏览器中,就像真正的用户在操作一样.由于这个性质,Selenium也是一 ...
- python scrapy爬取知乎问题和收藏夹下所有答案的内容和图片
上文介绍了爬取知乎问题信息的整个过程,这里介绍下爬取问题下所有答案的内容和图片,大致过程相同,部分核心代码不同. 爬取一个问题的所有内容流程大致如下: 一个问题url 请求url,获取问题下的答案个数 ...
- 利用Scrapy爬取所有知乎用户详细信息并存至MongoDB
欢迎大家关注腾讯云技术社区-博客园官方主页,我们将持续在博客园为大家推荐技术精品文章哦~ 作者 :崔庆才 本节分享一下爬取知乎用户所有用户信息的 Scrapy 爬虫实战. 本节目标 本节要实现的内容有 ...
- scrapy 爬取知乎问题、答案 ,并异步写入数据库(mysql)
python版本 python2.7 爬取知乎流程: 一 .分析 在访问知乎首页的时候(https://www.zhihu.com),在没有登录的情况下,会进行重定向到(https://www. ...
随机推荐
- linux dd使用记录
dd if=/dev/sda of=/dev/sdb bs=10M Linux下显示dd命令的进度: dd if=/dev/zero of=/tmp/zero.img bs=10M count=100 ...
- [BZOJ 2064]分裂
2064: 分裂 Time Limit: 10 Sec Memory Limit: 64 MBSubmit: 572 Solved: 352[Submit][Status][Discuss] De ...
- linux分析、诊断及调优必备的“杀器”之二
先说明下,之所以同类内容分成多篇文章,不是为了凑篇数,而是为了便于自己和大家阅读,下面继续: 7.sar The sar command is used to collect, report, and ...
- Web前端性能分析
Web前端性能通常上代表着一个完全意义上的用户响应时间,包含从开始解析HTML文件到最后渲染完成开始的整个过程,但不包括在输入url之后与服务器的交互阶段.下面是整个过程的各个步骤: 开始解析html ...
- STM32F4系列单片机上使用CUBE配置MBEDTLS实现pem格式公钥导入
|版权声明:本文为博主原创文章,未经博主允许不得转载. 最近尝试在STM32F4下用MBEDTLS实现了公钥导入(我使用的是ECC加密),整个过程使用起来比较简单. 首先,STM32F4系列CUBE里 ...
- pythoncharm 中解决启动server时出现 “django.core.exceptions.ImproperlyConfigured: Requested setting DEBUG, but settings are not configured”的错误
背景介绍 最近,尝试着用pythoncharm 这个All-star IDE来搞一搞Django,于是乎,下载专业版,PJ等等一系列操作之后,终于得偿所愿.可以开工了. 错误 在园子里找了一篇初学者的 ...
- Spring mvc中junit测试遇到com.mysql.jdbc.exceptions.jdbc4.MySQLSyntaxErrorException错误怎么解决
今天遇到图片中的错误,纠结了一下,弄清楚了怎么从控制台中读取错误信息,并修改错误. com.mysql.jdbc.exceptions.jdbc4.MySQLSyntaxErrorException: ...
- Netty事件监听和处理(下)
上一篇 介绍了事件监听.责任链模型.socket接口和IO模型.线程模型等基本概念,以及Netty的整体结构,这篇就来说下Netty三大核心模块之一:事件监听和处理. 前面提到,Netty是一个NIO ...
- zuul入门(3)开发zuul的过滤器
1.编写Zuul过滤器(Java&Groovy) 理解过滤器类型和请求生命周期后,我们来编写一个Zuul过滤器.编写Zuul的过滤器非常简单,我们只需继承抽象类ZuulFilter,然后实现几 ...
- 实现GridControl行动态改变行字体和背景色
需求:开发时遇到一个问题, 需要根据GridControl行数据不同,实现不同的效果 在gridView的RowCellStyle的事件中实现,需要的效果 private void gridView1 ...