深度学习之ResNet网络
介绍
Resnet分类网络是当前应用最为广泛的CNN特征提取网络。
我们的一般印象当中,深度学习愈是深(复杂,参数多)愈是有着更强的表达能力。凭着这一基本准则CNN分类网络自Alexnet的7层发展到了VGG的16乃至19层,后来更有了Googlenet的22层。可后来我们发现深度CNN网络达到一定深度后再一味地增加层数并不能带来进一步地分类性能提高,反而会招致网络收敛变得更慢,test dataset的分类准确率也变得更差。排除数据集过小带来的模型过拟合等问题后,我们发现过深的网络仍然还会使分类准确度下降(相对于较浅些的网络而言)。
简单地增加网络层数会导致梯度消失和梯度爆炸,因此,人们提出了正则化初始化和中间的正则化层(Batch Normalization),但是 又引发了另外一个问题——退化问题,即随着网络层数地增加,训练集上的准确率却饱和甚至下降。这个问题并不是由过拟合(overfit)造成的,因为过拟合表现应该表现为在训练集上变现更好。
residual learning的block是通过使用多个有参层来学习输入输出之间的残差表示,而非像一般CNN网络(如Alexnet/VGG等)那样使用有参层来直接尝试学习输入、输出之间的映射。实验表明使用一般意义上的有参层来直接学习残差比直接学习输入、输出间映射要容易得多(收敛速度更快),也有效得多(可通过使用更多的层来达到更高的分类精度)。
Resnet网络
残差:观测值与估计值之间的差。
在网络中增加直连通道,允许原始输入信息直接传到后面的层中,当前网络不需要学习整个的输出,只学习上一个网络输出的残差,拷贝一个浅层网络的输出加给深层的输出,直接将输入信息绕道传到输出,让深度学习后面的层至少实现恒等快捷连接(identity shortcut connection)的作用,保护信息完整性,整个网络只需要学习输入、输出差别的那部分,简化了学习目标和难度。
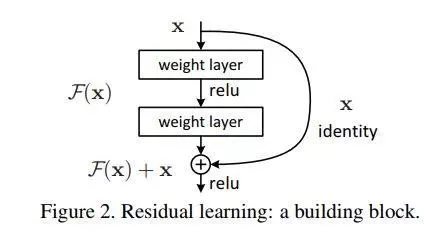
\(F(x)=H(x)-x\).\(x\)是估计值(也就是上一层ResNet输出的特征映射),一般称x为identity Function,它是一个跳跃连接;\(F(x)\)是ResNet Function,\(H(x)\)是深层输出,观测值。当\(x\)代表的特征已经足够成熟,\(F(x)\)会自动趋向于使学习成为0.
residual模块改变了前向和后向信息传递的方式,从而促进了网络的优化,在反向传播过程中梯度的传导多了更简便的路径。会明显减小模块中参数的值从而让网络中的参数对反向传导的损失值有更敏感的响应能力,虽然从根本上没有解决回传损失小的问题,但却让参数减小,相对而言增加了回传损失的效果,也产生了一定的正则化作用。
网络结构
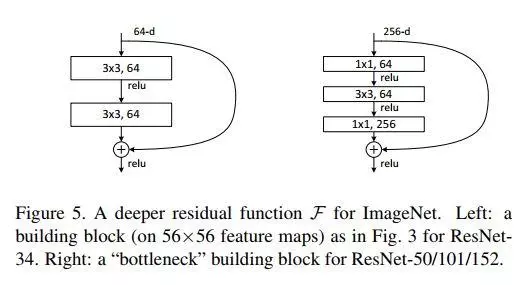
- basic模式:简单地将X相对Y缺失的通道直接补零从而使其能够相对齐的方式,以两个3*3的卷积网络串接在一起作为一个残差块;
- bottleneck模式:通过使用1x1的conv来表示\(W_s\)映射从而使得最终输入与输出的通道达到一致的方式。1*1,3*3,1*1三个卷积网络串接在一起作为一个残差模块。加入1*1的卷积核巧妙地缩减或扩张feature map维度从而使得我们的3x3 conv的filters数目不受外界即上一层输入的影响,自然它的输出也不会影响到下一层module,增加非线性和减小输出的深度以减小计算成本。不过它纯是为了节省计算时间进而缩小整个模型训练所需的时间而设计的,对最终的模型精度并无影响。
代码实现
import torch
import torch.nn as nn
class BasicBlock(nn.Module):
"""Basic Block for resnet 18 and resnet 34
"""
#BasicBlock and BottleNeck block
#have different output size
#we use class attribute expansion
#to distinct
expansion = 1
def __init__(self, in_channels, out_channels, stride=1):
super().__init__()
#residual function
self.residual_function = nn.Sequential(
nn.Conv2d(in_channels, out_channels, kernel_size=3, stride=stride, padding=1, bias=False),
nn.BatchNorm2d(out_channels),
nn.ReLU(inplace=True),
nn.Conv2d(out_channels, out_channels * BasicBlock.expansion, kernel_size=3, padding=1, bias=False),
nn.BatchNorm2d(out_channels * BasicBlock.expansion)
)
#shortcut
self.shortcut = nn.Sequential()
#the shortcut output dimension is not the same with residual function
#use 1*1 convolution to match the dimension
if stride != 1 or in_channels != BasicBlock.expansion * out_channels:
self.shortcut = nn.Sequential(
nn.Conv2d(in_channels, out_channels * BasicBlock.expansion, kernel_size=1, stride=stride, bias=False),
nn.BatchNorm2d(out_channels * BasicBlock.expansion)
)
def forward(self, x):
return nn.ReLU(inplace=True)(self.residual_function(x) + self.shortcut(x))
class BottleNeck(nn.Module):
"""Residual block for resnet over 50 layers
"""
expansion = 4
def __init__(self, in_channels, out_channels, stride=1):
super().__init__()
self.residual_function = nn.Sequential(
nn.Conv2d(in_channels, out_channels, kernel_size=1, bias=False),
nn.BatchNorm2d(out_channels),
nn.ReLU(inplace=True),
nn.Conv2d(out_channels, out_channels, stride=stride, kernel_size=3, padding=1, bias=False),
nn.BatchNorm2d(out_channels),
nn.ReLU(inplace=True),
nn.Conv2d(out_channels, out_channels * BottleNeck.expansion, kernel_size=1, bias=False),
nn.BatchNorm2d(out_channels * BottleNeck.expansion),
)
self.shortcut = nn.Sequential()
if stride != 1 or in_channels != out_channels * BottleNeck.expansion:
self.shortcut = nn.Sequential(
nn.Conv2d(in_channels, out_channels * BottleNeck.expansion, stride=stride, kernel_size=1, bias=False),
nn.BatchNorm2d(out_channels * BottleNeck.expansion)
)
def forward(self, x):
return nn.ReLU(inplace=True)(self.residual_function(x) + self.shortcut(x))
class ResNet(nn.Module):
def __init__(self, block, num_block, num_classes=100):
super().__init__()
self.in_channels = 64
self.conv1 = nn.Sequential(
nn.Conv2d(3, 64, kernel_size=3, padding=1, bias=False),
nn.BatchNorm2d(64),
nn.ReLU(inplace=True))
#we use a different inputsize than the original paper
#so conv2_x's stride is 1
self.conv2_x = self._make_layer(block, 64, num_block[0], 1)
self.conv3_x = self._make_layer(block, 128, num_block[1], 2)
self.conv4_x = self._make_layer(block, 256, num_block[2], 2)
self.conv5_x = self._make_layer(block, 512, num_block[3], 2)
self.avg_pool = nn.AdaptiveAvgPool2d((1, 1))
self.fc = nn.Linear(512 * block.expansion, num_classes)
def _make_layer(self, block, out_channels, num_blocks, stride):
"""make resnet layers(by layer i didnt mean this 'layer' was the
same as a neuron netowork layer, ex. conv layer), one layer may
contain more than one residual block
Args:
block: block type, basic block or bottle neck block
out_channels: output depth channel number of this layer
num_blocks: how many blocks per layer
stride: the stride of the first block of this layer
Return:
return a resnet layer
"""
# we have num_block blocks per layer, the first block
# could be 1 or 2, other blocks would always be 1
strides = [stride] + [1] * (num_blocks - 1)
layers = []
for stride in strides:
layers.append(block(self.in_channels, out_channels, stride))
self.in_channels = out_channels * block.expansion
return nn.Sequential(*layers)
def forward(self, x):
output = self.conv1(x)
output = self.conv2_x(output)
output = self.conv3_x(output)
output = self.conv4_x(output)
output = self.conv5_x(output)
output = self.avg_pool(output)
output = output.view(output.size(0), -1)
output = self.fc(output)
return output
def resnet18():
""" return a ResNet 18 object
"""
return ResNet(BasicBlock, [2, 2, 2, 2])
def resnet34():
""" return a ResNet 34 object
"""
return ResNet(BasicBlock, [3, 4, 6, 3])
def resnet50():
""" return a ResNet 50 object
"""
return ResNet(BottleNeck, [3, 4, 6, 3])
def resnet101():
""" return a ResNet 101 object
"""
return ResNet(BottleNeck, [3, 4, 23, 3])
def resnet152():
""" return a ResNet 152 object
"""
return ResNet(BottleNeck, [3, 8, 36, 3])
引用:
- 论文下载:https://arxiv.org/abs/1512.03385
- https://www.jianshu.com/p/93990a641066
- https://www.jianshu.com/p/23c73b90657f
- https://blog.csdn.net/weixin_43624538/article/details/85049699
深度学习之ResNet网络的更多相关文章
- 深度学习图像分割——U-net网络
写在前面: 一直没有整理的习惯,导致很多东西会有所遗忘,遗漏.借着这个机会,养成一个习惯. 对现有东西做一个整理.记录,对新事物去探索.分享. 因此博客主要内容为我做过的,所学的整理记录以及新的算法. ...
- 调参侠的末日? Auto-Keras 自动搜索深度学习模型的网络架构和超参数
Auto-Keras 是一个开源的自动机器学习库.Auto-Keras 的终极目标是允许所有领域的只需要很少的数据科学或者机器学习背景的专家都可以很容易的使用深度学习.Auto-Keras 提供了一系 ...
- 深度学习|基于LSTM网络的黄金期货价格预测--转载
深度学习|基于LSTM网络的黄金期货价格预测 前些天看到一位大佬的深度学习的推文,内容很适用于实战,争得原作者转载同意后,转发给大家.之后会介绍LSTM的理论知识. 我把code先放在我github上 ...
- 学习笔记-ResNet网络
ResNet网络 ResNet原理和实现 总结 一.ResNet原理和实现 神经网络第一次出现在1998年,当时用5层的全连接网络LetNet实现了手写数字识别,现在这个模型已经是神经网络界的“hel ...
- 深度学习之GRU网络
1.GRU概述 GRU是LSTM网络的一种效果很好的变体,它较LSTM网络的结构更加简单,而且效果也很好,因此也是当前非常流形的一种网络.GRU既然是LSTM的变体,因此也是可以解决RNN网络中的长依 ...
- 深度学习之TCN网络
论文链接:https://arxiv.org/pdf/1803.01271.pdf TCN(Temporal Convolutional Networks) TCN特点: 可实现接收任意长度的输入序列 ...
- 深度学习-生成对抗网络GAN笔记
生成对抗网络(GAN)由2个重要的部分构成: 生成器G(Generator):通过机器生成数据(大部分情况下是图像),目的是“骗过”判别器 判别器D(Discriminator):判断这张图像是真实的 ...
- 深度学习之Seq_seq网络
知识点 """ 机器翻译: 历史: 1.逐字翻译 2.基于统计学的机器翻译 3.循环网络和编码 翻译过程: 输入 -- > encoder -->向量 --& ...
- 训练深度学习网络时候,出现Nan是什么原因,怎么才能避免?——我自己是因为data有nan的坏数据,clear下解决
from:https://www.zhihu.com/question/49346370 Harick 梯度爆炸了吧. 我的解决办法一般以下几条:1.数据归一化(减均值,除方差,或者加入n ...
随机推荐
- Sitecore 9 介绍
Sitecore 9就在这里.这个最新版本更大,更智能,更易于使用 - 并且更好地帮助您实现业务和数字目标. 现在,Sitecore 9对营销人员和非Sitecore开发人员来说更容易使用.它拥有许多 ...
- (转)MySQL中char(36)被认为是GUID导致的BUG及解决方案
有时候在使用Toad或在程序中,偶尔会遇到如下的错误: System.FormatExceptionGUID 应包含带 4 个短划线的 32 位数(xxxxxxxx-xxxx-xxxx-xxxx-xx ...
- 【生活现场】从打牌到map-reduce工作原理解析(转)
原文:http://www.sohu.com/a/287135829_818692 小史是一个非科班的程序员,虽然学的是电子专业,但是通过自己的努力成功通过了面试,现在要开始迎接新生活了. 对小史面试 ...
- 【spring】【spring boot】获取系统根路径,根目录,用于存储临时生成的文件在服务器上
今日份代码: private static final String UPLOAD_TEMP_FILE_NAME = "测试商品数据.xlsx"; /** * 获取临时文件路径 * ...
- 【spring boot】spring boot的自定义banner修改+spring boot启动项目图标修改
1.启动Spring Boot项目后会看到这样的图案,这个图片其实是可以自定义的,打开网站 http://patorjk.com/software/taag/#p=display&h=3&am ...
- 2019-11-29-C#-字典-Dictionary-的-TryGetValue-与先判断-ContainsKey-然后-Get-的性能对比
原文:2019-11-29-C#-字典-Dictionary-的-TryGetValue-与先判断-ContainsKey-然后-Get-的性能对比 title author date CreateT ...
- StackExchange.Redis 封装
博主最近开始玩Redis啊~~ 看了很多Redis的文章,感觉有点云里雾里的,之前看到是ServiceStack.Redis,看了一些大佬封装的Helper类,还是懵懵的QAQ 没办法啊只能硬着**上 ...
- 洛谷 P1002过河卒
洛谷 P1002过河卒 题目描述 棋盘上AA点有一个过河卒,需要走到目标BB点.卒行走的规则:可以向下.或者向右.同时在棋盘上CC点有一个对方的马,该马所在的点和所有跳跃一步可达的点称为对方马的控制点 ...
- java--static与代码块
static与代码块: static class Student{ static String school; // 随着类的加载而执行 可以由类进行调用 static { // 静态代码块 加载类时 ...
- ta和夏天一起来了
目录 ta和夏天一起来了 上半年,过去的就让去过去,遗憾的也别再遗憾. 下半年,拥有的请好好珍惜,想要的请努力去追. ta和夏天一起来了 转眼结束了2019的上半年,在这个月末, 季度末, 周末, ...