用肘方法确定 kmeans 聚类中簇的最佳数量
说明:
KMeans 聚类中的超参数是 K,需要我们指定。K 值一方面可以结合具体业务来确定,另一方面可以通过肘方法来估计。K 参数的最优解是以成本函数最小化为目标,成本函数为各个类畸变程度之和,每个类的畸变程度等于该类重心与其内部成员位置距离的平方和但是平均畸变程度会随着K的增大先减小后增大,所以可以求出最小的平均畸变程度。
1、示例
# 导入相关模块
from sklearn.datasets import make_blobs
from sklearn.cluster import KMeans
import matplotlib.pyplot as plt # 创建仿真聚类数据集
X, y = make_blobs(n_samples=150,
n_features=2,
centers=3,
cluster_std=0.5,
shuffle=True,
random_state=0) distortions = []
Ks = range(1, 11) # 为不同的超参数拟合模型
for k in Ks:
km = KMeans(n_clusters=k,
init='k-means++',
n_init=10,
max_iter=300,
n_jobs=-1,
random_state=0) km.fit(X)
distortions.append(km.inertia_) # 保存不同超参数对应模型的聚类偏差 plt.rcParams['font.sans-serif'] = 'SimHei'
plt.figure('百里希文', figfacecolor='lightyellow') # 绘制不同超参 K 对应的离差平方和折线图
plt.plot(Ks, distortions,'bo-', mfc='r')
plt.xlabel('簇中心的个数 k')
plt.ylabel('离差平方和')
plt.title('用肘方法确定 kmeans 聚类中簇的最佳数量') plt.show()
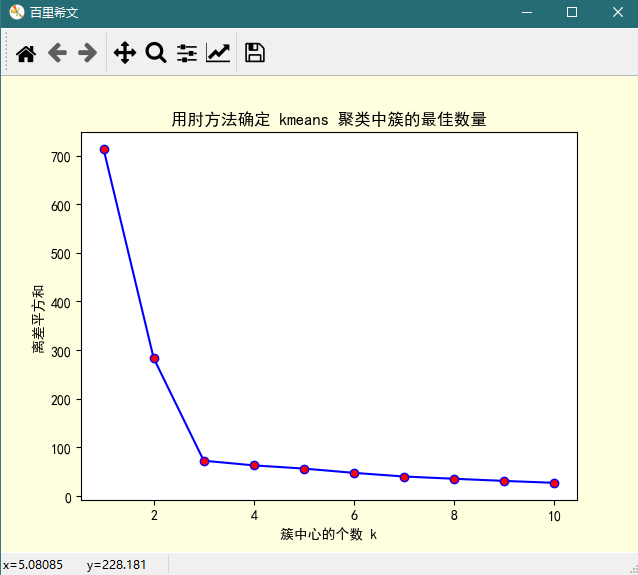
按语:
由上图可知,K 从 1 到 2, 从 2 到 3 的过程中,离差平方和减少的都相当明显,而 K 从 3 到 4,乃至 4 以后,离差平方和减少的都很有限,所以最佳的 K 值应该为 3(与仿真数据集的参数对对应)。由于上图看上去很像一只手肘,理论上最佳的 K 值在肘处取得,故而得名。
2、用平均离差效果似乎更明显
# 导入相关模块
import numpy as np
from sklearn.datasets import make_blobs
from sklearn.cluster import KMeans
from scipy.spatial.distance import cdist
import matplotlib.pyplot as plt # 创建仿真聚类数据集
X, y = make_blobs(n_samples=150,
n_features=2,
centers=3,
cluster_std=0.5,
shuffle=True,
random_state=0) meanDispersions = []
Ks = range(1, 11) # 为不同的超参数拟合模型
for k in Ks:
km = KMeans(n_clusters=k,
init='k-means++',
n_init=10,
max_iter=300,
n_jobs=-1,
random_state=0) km.fit(X)
meanDispersions.append(sum(
np.min(cdist(X, km.cluster_centers_, 'euclidean'), axis=1))/X.shape[0]) # 保存不同超参数对应模型的聚类偏差 plt.rcParams['font.sans-serif'] = 'SimHei'
plt.figure('百里希文', facecolor='lightyellow') # 绘制不同超参 K 对应的离差平方和折线图
plt.plot(Ks, meanDispersions,'bo-', mfc='r')
plt.xlabel('簇中心的个数 k')
plt.ylabel('平均离差')
plt.title('用肘方法确定 kmeans 聚类中簇的最佳数量') plt.show()
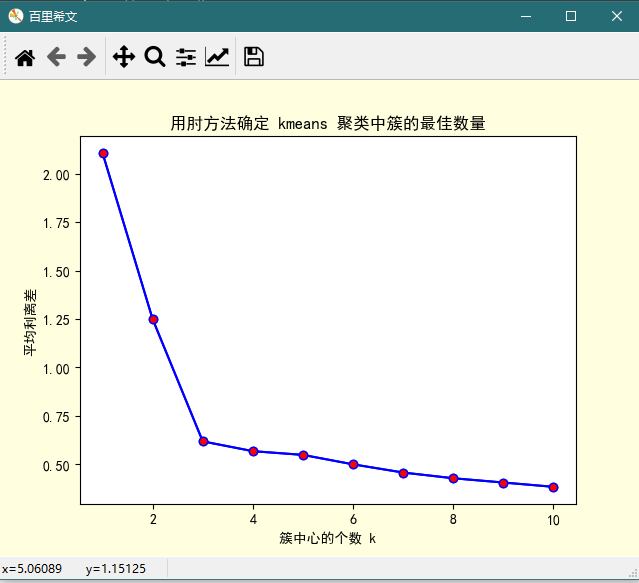
用肘方法确定 kmeans 聚类中簇的最佳数量的更多相关文章
- kmeans聚类中的坑 基于R shiny 可交互的展示
龙君蛋君 2015年5月24日 1.背景介绍 最近公司在用R 建模,老板要求用shiny 展示结果,建模的过程中用到诸如kmean聚类,时间序列分析等方法.由于之前看过一篇讨论kmenas聚类针对某一 ...
- K-Means 聚类
机器学习中的算法主要分为两类,一类是监督学习,监督学习顾名思义就是在学习的过程中有人监督,即对于每一个训练样本,有对应的标记指明它的类型.如识别算法的训练集中猫的图片,在训练之前会人工打上标签,告诉电 ...
- (数据科学学习手札11)K-means聚类法的原理简介&Python与R实现
kmeans法(K均值法)是麦奎因提出的,这种算法的基本思想是将每一个样本分配给最靠近中心(均值)的类中,具体的算法至少包括以下三个步骤: 1.将所有的样品分成k个初始类: 2.通过欧氏距离将某个样品 ...
- Matlab中K-means聚类算法的使用(K-均值聚类)
K-means聚类算法采用的是将N*P的矩阵X划分为K个类,使得类内对象之间的距离最大,而类之间的距离最小. 使用方法:Idx=Kmeans(X,K)[Idx,C]=Kmeans(X,K) [Idx, ...
- k-means+python︱scikit-learn中的KMeans聚类实现( + MiniBatchKMeans)
来源:, init='k-means++', n_init=10, max_iter=300, tol=0.0001, precompute_distances='auto', verbose=0, ...
- 机器学习中K-means聚类算法原理及C语言实现
本人以前主要focus在传统音频的软件开发,接触到的算法主要是音频信号处理相关的,如各种编解码算法和回声消除算法等.最近切到语音识别上,接触到的算法就变成了各种机器学习算法,如GMM等.K-means ...
- Spark MLlib中KMeans聚类算法的解析和应用
聚类算法是机器学习中的一种无监督学习算法,它在数据科学领域应用场景很广泛,比如基于用户购买行为.兴趣等来构建推荐系统. 核心思想可以理解为,在给定的数据集中(数据集中的每个元素有可被观察的n个属性), ...
- 机器学习方法(七):Kmeans聚类K值如何选,以及数据重抽样方法Bootstrapping
欢迎转载,转载请注明:本文出自Bin的专栏blog.csdn.net/xbinworld. 技术交流QQ群:433250724,欢迎对算法.技术感兴趣的同学加入.我的博客写一些自己用得到东西,并分享给 ...
- K-Means 聚类算法
K-Means 概念定义: K-Means 是一种基于距离的排他的聚类划分方法. 上面的 K-Means 描述中包含了几个概念: 聚类(Clustering):K-Means 是一种聚类分析(Clus ...
随机推荐
- node.js与mysql数据库的交互
我们已经建好了数据库也建好了表,现在我们想查询数据库表中的内容,应该怎么做呢? 代码如下: var mysql = require('mysql'); //导入mysql包模块 var connect ...
- Zabbix介绍及安装
Zabbix简介 Zabbix是一款能够监控各种网络参数以及服务器健康性和完整性的软件,是一个企业级的分布式开源监控方案.Zabbix使用灵活的通知机制,允许用户为几乎任何事件配置基于邮件的告警.这样 ...
- Web协议详解与抓包实战:HTTP1协议-HTTP 响应行(3)
一.HTTP 响应行 二.响应码分类:1xx 三.响应码分类: 2xx 1. 201 Created: 有新资源在服务器端被成功创建 2.207 Multi-Status:RFC4918 ,在 WEB ...
- [LeetCode] 454. 4Sum II 四数之和之二
Given four lists A, B, C, D of integer values, compute how many tuples (i, j, k, l) there are such t ...
- java ++前缀
public class Sample { public static void main(String[] args) { , num2 = ; , num4 = ; ++num1; System. ...
- 通过欧拉计划学习Rust编程(第22~25题)
最近想学习Libra数字货币的MOVE语言,发现它是用Rust编写的,所以先补一下Rust的基础知识.学习了一段时间,发现Rust的学习曲线非常陡峭,不过仍有快速入门的办法. 学习任何一项技能最怕没有 ...
- 动手学深度学习6-认识Fashion_MNIST图像数据集
获取数据集 读取小批量样本 小结 本节将使用torchvision包,它是服务于pytorch深度学习框架的,主要用来构建计算机视觉模型. torchvision主要由以下几个部分构成: torchv ...
- Python文件读写机制
Python提供了必要的函数和方法进行默认情况下的文件基本操作 文件打开方式: open(name[,mode[buf]]) name:文件路径 mode:打开方式 buf:缓冲buffering大小 ...
- ping不通服务器的解决方法
参考腾讯云的解决办法: https://cloud.tencent.com/document/product/213/14639#CheckOSSetting 我的服务器是aws的, 解决方法大同小异 ...
- centos下java环境搭建安装
1. 购买服务器(阿里云) 2. 重置密码,重启服务器 3. 创建账号work groupadd work #创建组 mkdir /data # 创建数据文件夹 useradd -d /data/wo ...