ELK集群模式部署
架构拓扑图为:
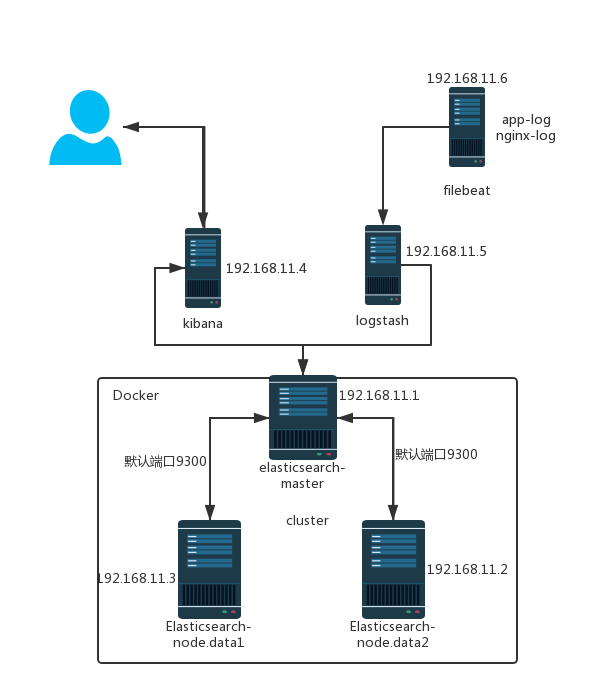
准备工作:
下载资源包:
Elasticsearch: wget https://artifacts.elastic.co/downloads/elasticsearch/elasticsearch-6.2.4.tar.gz # 这一步用docker启动,可以不用下载。
Kibana: wget https://artifacts.elastic.co/downloads/kibana/kibana-6.2.4-linux-x86_64.tar.gz
Logstash:wget https://artifacts.elastic.co/downloads/logstash/logstash-6.2.4.tar.gz
Filebeat:wget https://artifacts.elastic.co/downloads/beats/filebeat/filebeat-6.2.4-linux-x86_64.tar.gz
安装:
根据拓扑图把对应的服务安装在对应的服务器。
tar xvf kibana-6.2.3-linux-x86_64.tar.gz -C /usr/local/
tar xvf logstash-6.2.4.tar.gz -C /usr/local/
tar -xvf filebeat-6.2.4-linux-x86_64.tar.gz -C /usr/local/
部署启动:
Elasticsearch-master(192.168.11.1):
需自行提前安装好docker 和 docker-compose。
vim docker-compose.yml
version: '2'
services:
elasticsearch:
image: docker.elastic.co/elasticsearch/elasticsearch:6.2.3
container_name: elasticsearch
environment:
- cluster.name=es-cluster
- bootstrap.memory_lock=true
- "network.publish_host=192.168.11.1"
- "ES_JAVA_OPTS=-Xms4096m -Xmx4096m"
ulimits:
memlock:
soft: -1
hard: -1
volumes:
- /data/elasticsearch_data:/usr/share/elasticsearch/data
ports:
- "192.168.11.1:9200:9200"
- "192.168.11.1:9300:9300"
mkdir -p /data/elasticsearch_data && chmod 775 /data/elasticsearch_data && docker-compose up -d
Elasticsearch-node2.data(192.168.11.2):
需自行提前安装好docker 和 docker-compose。
vim docker-compose.yml
version: '2'
services:
elasticsearch:
image: docker.elastic.co/elasticsearch/elasticsearch:6.2.3
container_name: elasticsearch
environment:
- cluster.name=es-cluster
- bootstrap.memory_lock=true
- "network.publish_host=192.168.11.2"
- "discovery.zen.ping.unicast.hosts=192.168.11.1"
- "ES_JAVA_OPTS=-Xms4096m -Xmx4096m"
ulimits:
memlock:
soft: -1
hard: -1
volumes:
- /data/elasticsearch_data:/usr/share/elasticsearch/data
ports:
- "192.168.11.2:9200:9200"
- "192.168.11.2:9300:9300"
mkdir -p /data/elasticsearch_data && chmod 775 /data/elasticsearch_data && docker-compose up -d
Elasticsearch-node3.data(192.168.11.3):
需自行提前安装好docker 和 docker-compose。
vim docker-compose.yml
version: '2'
services:
elasticsearch:
image: docker.elastic.co/elasticsearch/elasticsearch:6.2.3
container_name: elasticsearch
environment:
- cluster.name=es-cluster
- bootstrap.memory_lock=true
- "network.publish_host=192.168.11.3"
- "discovery.zen.ping.unicast.hosts=192.168.11.1"
- "ES_JAVA_OPTS=-Xms4096m -Xmx4096m"
ulimits:
memlock:
soft: -1
hard: -1
volumes:
- /data/elasticsearch_data:/usr/share/elasticsearch/data
ports:
- "192.168.11.3:9200:9200"
- "192.168.11.3:9300:9300"
mkdir -p /data/elasticsearch_data && chmod 775 /data/elasticsearch_data && docker-compose up -d
kibana(192.168.11.4):
cd /usr/local/kibana-6.2.3-linux-x86_64
cp ./config/kibana.yml ./config/kibana.yml.bak
echo '' > ./config/kibana.yml
vim ./config/kibana.yml
server.port: 5601
server.host: "192.168.11.4"
elasticsearch.url: "http://192.168.11.1:9200"
启动:./bin/kibana
扩展包(可装可不装):
kibana 报警扩展:
安装 ./bin/kibana-plugin install https://github.com/sirensolutions/sentinl/releases/download/tag-6.2.3-2/sentinl-v6.2.3.zip
重启 kibana
logstash(192.168.11.5)
cd /usr/local/logstash-6.2.4
vim nginx.conf
input {
beats {
port => 5066
host => "192.168.11.5"
codec => "json"
}
}
filter {
mutate {
gsub => ["message", "\\x", "\\\x"]
}
json {
source => "message"
}
}
output {
elasticsearch {
action => "index"
hosts => "192.168.11.1:9200"
index => "nginx-json-%{+YYYY.MM.dd}"
}
}
mkdir -p /data/logstash-data/nginx
启动:./bin/logstash -f ./nginx.conf --path.data=/data/logstash-data/nginx &
扩展
grok调试地址:http://grokdebug.herokuapp.com/
如需调试请修改output成以下,方便debug
output {
stdout {
codec => rubydebug
}
}
filebeat(192.168.11.6)
cd /usr/local/filebeat-6.2.4-linux-x86_64
vim nginx.yml
filebeat.prospectors:
- input_type: log
document_type: jsonlog
paths:
- /var/log/nginx/access.log
output:
logstash:
hosts: ["192.168.11.5:5066"]
启动:./filebeat -c ./nginx.yml &
nginx 日志的输出格式为:
log_format json '{"@timestamp":"$time_iso8601",'
'"remote_addr":"$remote_addr",'
'"request":"$request",'
'"status":$status,'
'"body_bytes":$body_bytes_sent,'
'"user_agent":"$http_user_agent",'
'"resp_time":"$upstream_response_time",'
'"req_time":$request_time,'
'"host":"$host",'
'"@version":"1",'
'"http_x_forwarded_for":"$http_x_forwarded_for",'
'"upstream_addr":"$upstream_addr",'
'"req_body":"$request_body"}';
参考地址:
https://www.elastic.co/guide/index.html
http://docs.docker.com/compose/
https://www.elastic.co/guide/en/logstash/current/index.html
https://www.elastic.co/guide/en/elasticsearch/reference/6.2/docker.html
https://www.elastic.co/guide/en/kibana/current/install.html
ELK集群模式部署的更多相关文章
- Redis集群模式部署
以下以Linux(CentOS)系统为例 1.1 下载和编译 $ wget http://download.redis.io/releases/redis-4.0.7.tar.gz $ tar xzf ...
- Flink集群模式部署及案例执行
一.软件要求 Flink在所有类UNIX的环境[例如linux,mac os x和cygwin]上运行,并期望集群由一个 主节点和一个或多个工作节点组成.在开始设置系统之前,确保在每个节点上都安装了一 ...
- zookeeper集群&伪集群模式部署
1.什么是单机部署 一台服务器上面部署一个单机版本的zookeeper服务,用于提供服务. 2.什么是集群部署? 集群部署就是多台服务器上面各部署单独的一个zookeeper服务,然后组建一个集群 3 ...
- Kafka集群模式部署
环境:kafka 0.8.1.1 基本概念 Kafka维护按类区分的消息,称为主题(topic) 生产者(producer)向kafka的主题发布消息 消费者(consumer)向主题注册,并且接收发 ...
- bigdata_ Kafka集群模式部署
环境:kafka 0.8.1.1 基本概念 Kafka维护按类区分的消息,称为主题(topic) 生产者(producer)向kafka的主题发布消息 消费者(consumer)向主题注册,并且接收发 ...
- Solr系列二:solr-部署详解(solr两种部署模式介绍、独立服务器模式详解、SolrCloud分布式集群模式详解)
一.solr两种部署模式介绍 Standalone Server 独立服务器模式:适用于数据规模不大的场景 SolrCloud 分布式集群模式:适用于数据规模大,高可靠.高可用.高并发的场景 二.独 ...
- Spark Tachyon编译部署(含单机和集群模式安装)
Tachyon编译部署 编译Tachyon 单机部署Tachyon 集群模式部署Tachyon 1.Tachyon编译部署 Tachyon目前的最新发布版为0.7.1,其官方网址为http://tac ...
- redis解决方案之三种集群模式的概念与部署
上篇文章为大家总结了redis命令并讲述了持久化,今天我们来看一下redis的三种集群模式:主从复制,哨兵集群,Cluster集群 本篇文章先介绍redis-cluster集群模式,然后再依次介绍它的 ...
- 56.storm 之 hello world (集群模式)
回顾 在上一小节,我们在PWTopology1 这一个java类中注解掉了集群模式,使用本地模式大概了解一下storm的工作流程.这一节我们注解掉本地模式相关的代码,放开集群模式相关代码,并且将项目打 ...
随机推荐
- linux命令(47):rmdir命令
1.命令格式: rmdir [选项]... 目录... 2.命令功能: 该命令从一个目录中删除一个或多个子目录项,删除某目录时也必须具有对父目录的写权限. 3.命令参数: - p 递归删除目录dirn ...
- Spring Boot with Docker
翻译自:https://spring.io/guides/gs/spring-boot-docker/ Spring Boot with Docker 这篇教程带你一步步构建一个Docker镜像用来运 ...
- 都是干货---真正的了解scrapy框架
去重规则 在爬虫应用中,我们可以在request对象中设置参数dont_filter = True 来阻止去重.而scrapy框架中是默认去重的,那内部是如何去重的. from scrapy.dupe ...
- matlab实用命令
实用命令 打点测时 在需要测量的开始部分标记: tic 在需要测量的结束部分标记: toc 记录程序从tic到toc运行所花费的时间 Image 翻转 fliplr(x) //左右翻转 flipud( ...
- react生命周期函数使用箭头函数,导致mobx-react问题
最近新人加入了项目,遇到了一个很奇怪的问题.mobx observable 属性,onChange的时候就是页面不会刷新. 试来试去,就是不知道什么原因,后来其他同事查到是因为componentWil ...
- SGU 261. Discrete Roots
给定\(p, k, A\),满足\(k, p\)是质数,求 \[x^k \equiv A \mod p\] 不会... upd:3:29 两边取指标,是求 \[k\text{ind}_x\equiv ...
- php jsonp跨域访问
项目中有个上传图片需要实时预览的,但又是两个系统的访问,故想了一下解决方案: 在新系统中上传图片后处理设置session,旧系统跨域访问获取对应session,进行对应模板预览. 上传图片预览按钮对应 ...
- 将excel中的sheet1导入到sqlserver中
原文地址:C#将Excel数据表导入SQL数据库的两种方法作者:windream 方式一: 实现在c#中可高效的将excel数据导入到sqlserver数据库中,很多人通过循环来拼接sql,这样做不但 ...
- Java 中自定义时间格式
DateFormat df = new SimpleDateFormat("yyyy-MM-dd hh:mm:ss"); Date d = new Date(); String s ...
- CodeForces 779E Bitwise Formula
位运算,枚举. 按按分开计算,枚举$?$是$0$还是$1$,分别计算出$sum$,然后就可以知道该位需要填$1$还是$0$了. #include<map> #include<set& ...