Python爬虫爬取豆瓣电影之数据提取值xpath和lxml模块
工具:Python 3.6.5、PyCharm开发工具、Windows 10 操作系统、谷歌浏览器
目的:爬取豆瓣电影排行榜中电影的title、链接地址、图片、评价人数、评分等
网址:https://movie.douban.com/chart
语法要点:
xpath语法:
谷歌浏览器安装 xpath helper插件:帮助我们从elements中定位数据
1、选择节点(标签)
(1)、/html/head/meta:能够选中html下的所有的meta标签
(2)、//li:当前页面上的所有的li标签
(3)、/html/head//link:head下的所有link标签
2、//:能够从任意节点开始选择
(1)、//li:当前页面上的所有的li标签
(2)、/html/head//link:head下的所有的link标签
3、@符号的用途
(1)、选择具体某个元素://div[@class='feed']/ul/li,选择class='feed'的div下的ul下的li
(2)、a/@href:选择a的href的值
4、获取文本
(1)、/a/text():获取a下的文本
(2)、/a//text():获取a下的所有文本
示例:
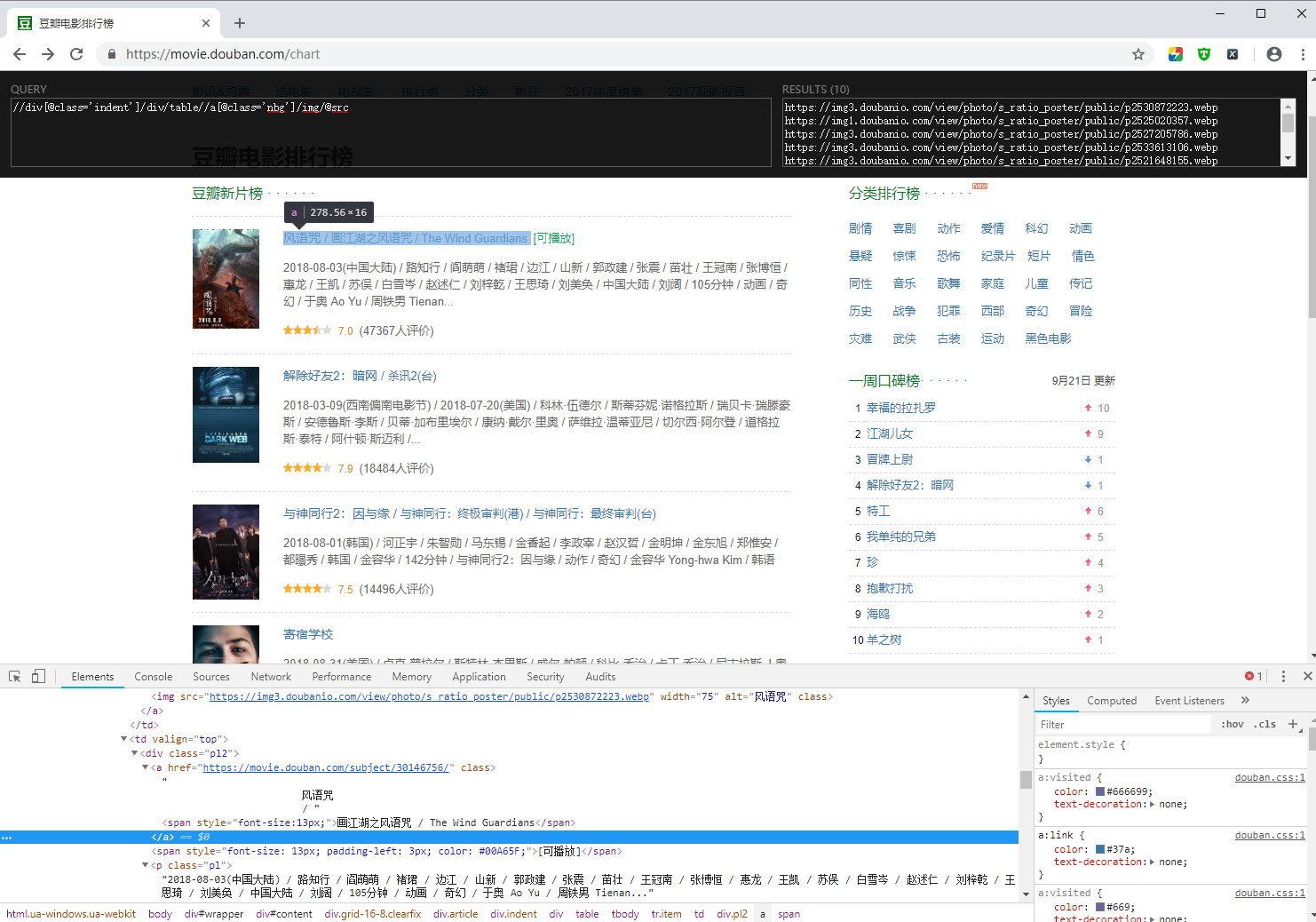
lxml语法:
1、安装:pip install lxml
2、使用
from lxml import etree
element = etree.HTML("html字符串")
element.xpath("")
代码:
from lxml import etree
import requests url = "https://movie.douban.com/chart" headers = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/69.0.3497.81 Safari/537.36"
}
response = requests.get(url,headers=headers)
html_str = response.content.decode() #print(html_str) html = etree.HTML(html_str)
print(html) #1.获取所有的电影的URL地址
#url_list = html.xpath("//div[@class='indent']/div/table//div[@class='pl2']/a/@href")
#print(url_list) #2.所有图片的地址
#img_list = html.xpath("//div[@class='indent']/div/table//a[@class='nbg']/img/@src")
#print(img_list)
ret1 = html.xpath("//div[@class='indent']/div/table")
print(ret1)
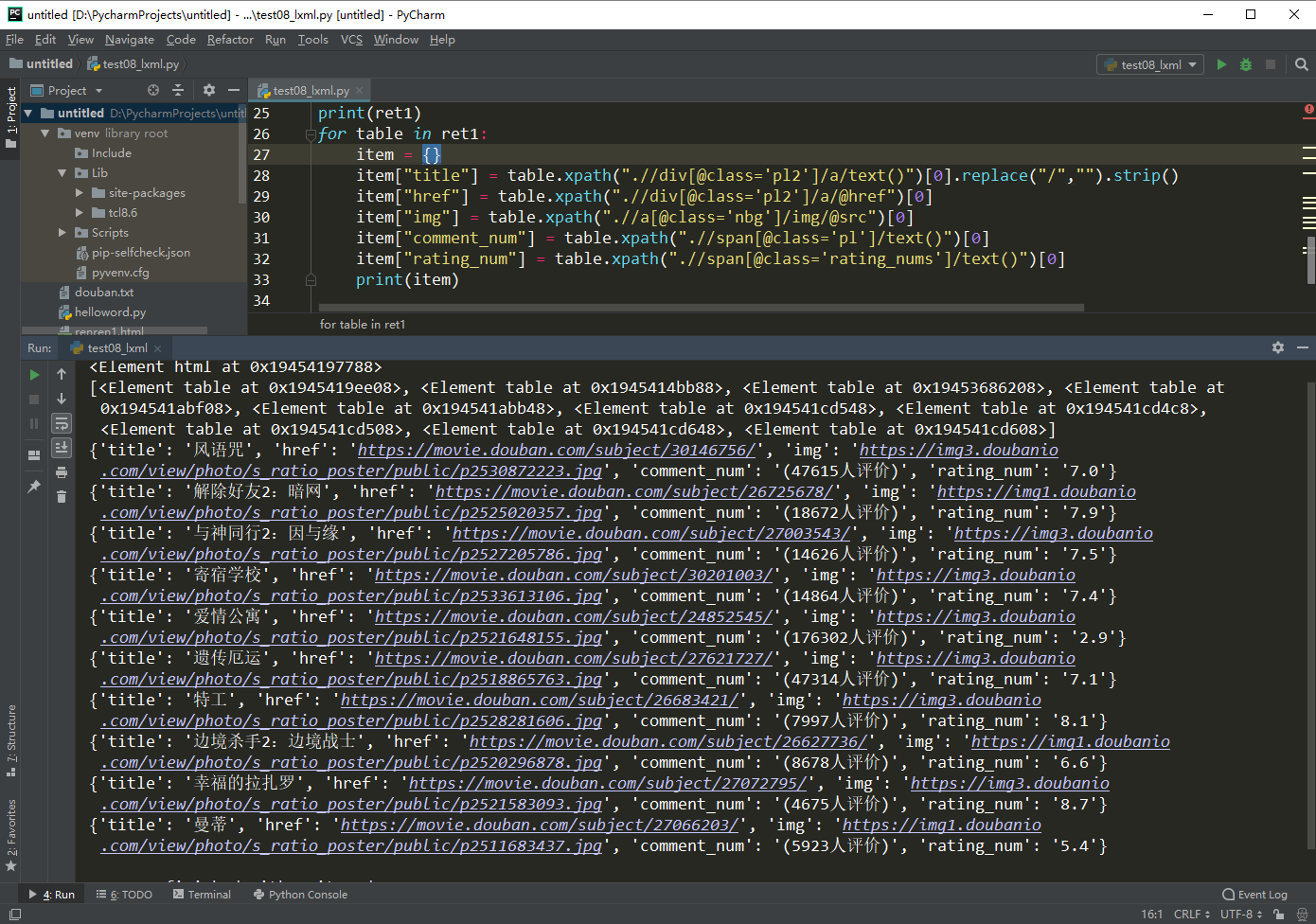
for table in ret1:
item = {}
item["title"] = table.xpath(".//div[@class='pl2']/a/text()")[0].replace("/","").strip()
item["href"] = table.xpath(".//div[@class='pl2']/a/@href")[0]
item["img"] = table.xpath(".//a[@class='nbg']/img/@src")[0]
item["comment_num"] = table.xpath(".//span[@class='pl']/text()")[0]
item["rating_num"] = table.xpath(".//span[@class='rating_nums']/text()")[0]
print(item)
运行效果:
Python爬虫爬取豆瓣电影之数据提取值xpath和lxml模块的更多相关文章
- python 爬虫&爬取豆瓣电影top250
爬取豆瓣电影top250from urllib.request import * #导入所有的request,urllib相当于一个文件夹,用到它里面的方法requestfrom lxml impor ...
- python爬虫-爬取豆瓣电影数据
#!/usr/bin/python# coding=utf-8# 作者 :Y0010026# 创建时间 :2018/12/16 16:27# 文件 :spider_05.py# IDE :PyChar ...
- Python爬虫爬取豆瓣电影名称和链接,分别存入txt,excel和数据库
前提条件是python操作excel和数据库的环境配置是完整的,这个需要在python中安装导入相关依赖包: 实现的具体代码如下: #!/usr/bin/python# -*- coding: utf ...
- Python爬虫-爬取豆瓣电影Top250
#!usr/bin/env python3 # -*- coding:utf-8-*- import requests from bs4 import BeautifulSoup import re ...
- python爬取豆瓣电影信息数据
题外话+ 大家好啊,最近自己在做一个属于自己的博客网站(准备辞职回家养老了,明年再战)在家里 琐事也很多, 加上自己 一回到家就懒了(主要是家里冷啊! 广东十几度,老家几度,躲在被窝瑟瑟发抖,) 由于 ...
- Python小爬虫——抓取豆瓣电影Top250数据
python抓取豆瓣电影Top250数据 1.豆瓣地址:https://movie.douban.com/top250?start=25&filter= 2.主要流程是抓取该网址下的Top25 ...
- 写一个python 爬虫爬取百度电影并存入mysql中
目标是利用python爬取百度搜索的电影 在类型 地区 年代各个标签下 电影的名字 评分 和图片连接 以及 电影连接 首先我们先在mysql中建表 create table liubo4( id in ...
- python爬虫 Scrapy2-- 爬取豆瓣电影TOP250
sklearn实战-乳腺癌细胞数据挖掘(博主亲自录制视频) https://study.163.com/course/introduction.htm?courseId=1005269003& ...
- Python爬虫----抓取豆瓣电影Top250
有了上次利用python爬虫抓取糗事百科的经验,这次自己动手写了个爬虫抓取豆瓣电影Top250的简要信息. 1.观察url 首先观察一下网址的结构 http://movie.douban.com/to ...
随机推荐
- mysql导入大量数据时报MySQL server has gone away错误的解决办法
https://blog.csdn.net/eric520zenobia/article/details/77619469
- 【量产工具修复】U盘插上没反应,格式化提示有写保护
最近在实验室发现师兄留下的U盘,插上电脑后打不开,弹出格式化界面,格式化的时候又提示该u盘“被写保护无法格式化”,于是打算采用量产的方法. 第一步:使用chipgenius监测u盘的芯片制造商和型号 ...
- MySQL学习(三)函数
一.数学函数 绝对值函数ABS():ABS(X) 返回圆周率函数PI() 平方根函数SQRT() 求余函数MOD(X,Y) 获取整数函数CEIL(X),CEILING(X)返回不小于X的最小整数:FL ...
- Flexbox 布局的最简单表单
作者: 阮一峰 日期: 2018年10月18日 弹性布局(Flexbox)逐渐流行,越来越多人使用,因为它写 CSS 布局真是太方便了. 三年前,我写过 Flexbox 的介绍(上,下),但是有些地方 ...
- SQL SERVER 2012断日志
有一个SQL2012库的日志达到了100G左右,平时开发人员根本没有做过事务日志备份,而磁盘空间已经快满了.所以,只能截断它.但是,由于从2K8以后,SQL SERVER好像不再提供 truncate ...
- BZOJ1123:[POI2008]BLO(双连通分量)
Description Byteotia城市有n个 towns m条双向roads. 每条 road 连接 两个不同的 towns ,没有重复的road. 所有towns连通. Input 输入n&l ...
- GPU卡掉卡
这几天用GPU卡跑东西,老是提示opencv的一个问题.但是我换个数据跑就没问题.说明代码是没问题的.发挥我作为女人的特质,从起试试吧.结果从起后找不到GPU卡了.nvidia-smi提示我没有安装最 ...
- 前端DOM知识点
DOM即文档对象模型(Document Object Model,DOM)是一种用于HTML和XML文档的编程接口.它给文档提供了一种结构化的表示方法,可以改变文档的内容和呈现方式.DOM把网页和脚本 ...
- shell脚本中 [-eq] [-ne] [-gt] [-lt] [ge] [le]
-eq //等于 -ne //不等于 -gt //大于 (greater ) -lt //小于 (less) -ge //大于等于 -le //小于等于 在linux 中 命令执行状态:0 为真,其他 ...
- spring入门(六) spring mvc+mybatis
1.引入依赖 <!-- https://mvnrepository.com/artifact/org.mybatis/mybatis --> <dependency> < ...