【Python3 爬虫】04_urllib.request.urlretrieve
urllib模块提供的urlretrieve()函数,urlretrieve()方法直接将远程的数据下载到本地
urllib语法
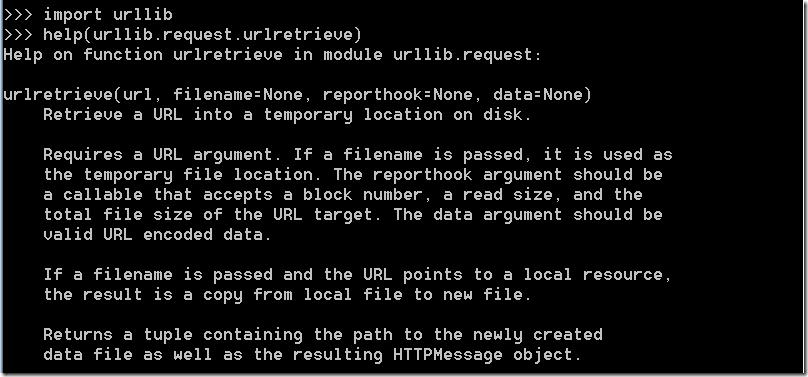
参数url:传入的网址,网址必须得是个字符串
参数filename:指定了保存本地路径(如果参数未指定,urllib会生成一个临时文件保存数据。)
参数reporthook:是一个回调函数,当连接上服务器、以及相应的数据块传输完毕时会触发该回调,我们可以利用这个回调函数来显示当前的下载进度。
参数data:指 post 到服务器的数据,该方法返回一个包含两个元素的(filename, headers)元组,filename 表示保存到本地的路径,header 表示服务器的响应头。
下面整个例子是将hao6v的页面抓取到本地
# -*- coding:UTF-8 -*- from urllib import request """
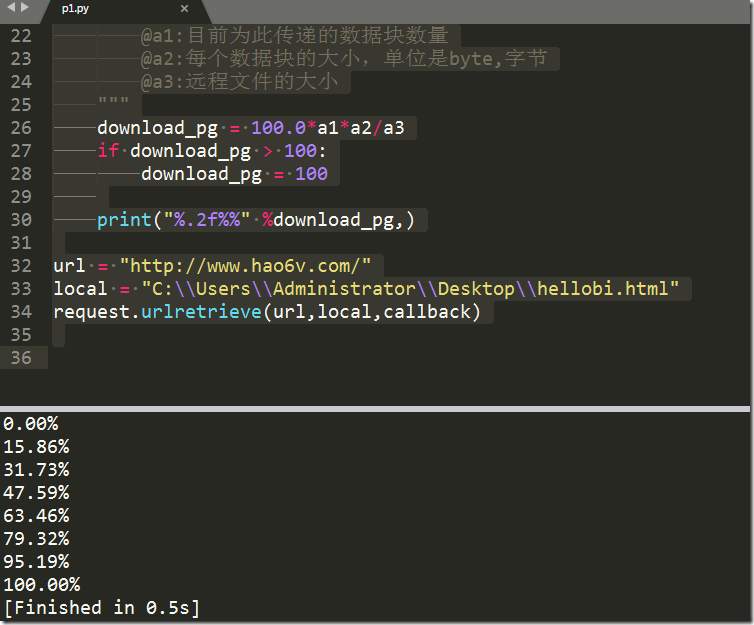
urlretrieve参数说明:
1.传入网址,网址的类型一定是字符串 2.传入的,本地的网页保存路径+文件名 3.一个函数的调用,我们可以随便定义这个函数,但是必须得有3个参数
①到目前为此传递的数据块数量
②是每个数据块的大小,单位是byte,字节
③远程文件的大小
""" def callback(a1,a2,a3): """
@a1:目前为此传递的数据块数量
@a2:每个数据块的大小,单位是byte,字节
@a3:远程文件的大小
"""
download_pg = 100.0*a1*a2/a3
if download_pg > 100:
download_pg = 100 print("%.2f%%" %download_pg,) url = "http://www.hao6v.com/"
local = "C:\\Users\\Administrator\\Desktop\\hellobi.html"
request.urlretrieve(url,local,callback)
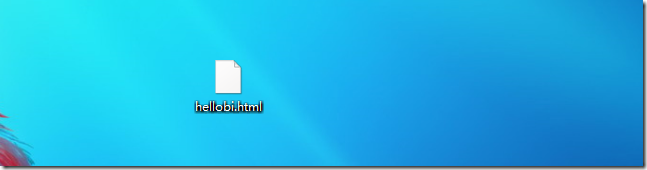
从上图我们可以看出,我们已经把网页成功爬取到本地,在本地桌面可以看到该页面,使用浏览器打开以后跟原页面一模一样(如果有CSS,则页面效果存在差异)
【Python3 爬虫】04_urllib.request.urlretrieve的更多相关文章
- python3.6 urllib.request库实现简单的网络爬虫、下载图片
#更新日志:#0418 爬取页面商品URL#0421 更新 添加爬取下载页面图片功能#0423 更新 添加发送邮件功能# 优化 爬虫异常处理.错误页面及空页面处理# 优化 爬虫关键字黑名单.白名单,提 ...
- python实战——网络爬虫之request
Urllib库是python中的一个功能强大的,用于操做URL,并在做爬虫的时候经常要用到的库,在python2中,分为Urllib和Urllib2两个库,在python3之后就将两个库合并到Urll ...
- python3爬虫.4.下载煎蛋网妹子图
开始我学习爬虫的目标 ----> 煎蛋网 通过设置User-Agent获取网页,发现本该是图片链接的地方被一个js函数代替了 于是全局搜索到该函数 function jandan_load_im ...
- 【Python3 爬虫】14_爬取淘宝上的手机图片
现在我们想要使用爬虫爬取淘宝上的手机图片,那么该如何爬取呢?该做些什么准备工作呢? 首先,我们需要分析网页,先看看网页有哪些规律 打开淘宝网站http://www.taobao.com/ 我们可以看到 ...
- python3爬虫:下载网易云音乐排行榜
#!/usr/bin/python3# -*- encoding:utf-8 -*- # 网易云音乐批量下载 import requestsimport urllib # 榜单歌曲批量下载# r = ...
- Python3 爬虫之 Scrapy 核心功能实现(二)
博客地址:http://www.moonxy.com 基于 Python 3.6.2 的 Scrapy 爬虫框架使用,Scrapy 的搭建过程请参照本人的另一篇博客:Python3 爬虫之 Scrap ...
- python3爬虫系列19之反爬随机 User-Agent 和 ip代理池的使用
站长资讯平台:python3爬虫系列19之随机User-Agent 和ip代理池的使用我们前面几篇讲了爬虫增速多进程,进程池的用法之类的,爬虫速度加快呢,也会带来一些坏事. 1. 前言比如随着我们爬虫 ...
- python3爬虫 爬取动漫视频
起因 因为本人家里有时候网速不行,所以看动漫的时候播放器总是一卡一卡的,看的太难受了.闲暇无聊又F12看看.但是动漫网站却无法打开控制台.这就勾起了我的兴趣.正好反正无事,去寻找下视频源. 但是这里事 ...
- python3 爬虫五大模块之五:信息采集器
Python的爬虫框架主要可以分为以下五个部分: 爬虫调度器:用于各个模块之间的通信,可以理解为爬虫的入口与核心(main函数),爬虫的执行策略在此模块进行定义: URL管理器:负责URL的管理,包括 ...
随机推荐
- AC日记——[SHOI2008]小约翰的游戏John bzoj 1022
1022 思路: nim: 代码: #include <cstdio> #include <cstdlib> #include <iostream> #includ ...
- (七)MySQL数据操作DQL:单表查询1
(1)单表查询 1)环境准备 mysql> CREATE TABLE company.employee5( id int primary key AUTO_INCREMENT not null, ...
- dfs序七个经典问题[转]
dfs序七个经典问题 参考自:<数据结构漫谈>-许昊然 dfs序是树在dfs先序遍历时的序列,将树形结构转化成序列问题处理. dfs有一个很好的性质:一棵子树所在的位置处于一个连续区间中. ...
- 二分图匹配【p2147】课程
Description n个学生去p个课堂,每一个学生都有自己的课堂,并且每个学生只能去一个课堂,题目要求能够安排每一个课堂都有人吗? Input 第一行是测试数据的个数, 每组测试数据的开始分别是p ...
- 12、Django实战第12天:课程机构列表页数据展示
今天完成的是课程机构列表页.... 1.启动服务,进入xadmin后,添加5个城市信息用作测试数据 2.添加课程机构,其中有一项要上传封面图的地方要注意 封面图上传路径是我们在models中设置好的 ...
- Oracle的锁
Oracle数据库中的锁机制 数据库是一个多用户使用的共享资源.当多个用户并发地存取数据时,在数据库中就会产生多个事务同时存取同一数据的情况.若对并发操作不加控制就可能会读取和存储不正确的数据,破坏数 ...
- cojs.tk(所有题目来源) 树状数组专练
1.求和问题 ★ 输入文件:sum.in 输出文件:sum.out 简单对比时间限制:1.2 s 内存限制:128 MB [问题描述] 在一个长度为n的整数数列中取出连续的若干 ...
- 一个简单的WeakList的实现
有的时候,我们会使用到WeakList,它和传统的List不同的是,保存的是对象的弱应用,在WeakList中存储的对象会被GC回收,在一些和UI相关的编程的地方会用到它(弱事件,窗体的通知订阅等). ...
- 如何判断一个请求是不是ajax请求
原文:http://blog.csdn.net/easy_is_good/article/details/53609057 public boolean isAjaxRequest(HttpServl ...
- javascript:使用代理绑定事件
<ul id="box"> <li>1</li> <li>2</li> <li>3</li> & ...