lucene&solr学习——创建和查询索引(理论)
1.Lucene基础
(1) 简介
Lucene是apache下的一个开放源代码的全文检索引擎工具包。提供完整的查询引擎和索引引擎;部分文本分析引擎。
Lucene的目的是为软件开发人员提供一个简单易用的工具包,以方便在目标系统中实现全文检索的功能。
(2) 应用场景
对于数据量大,数据结构不固定的数据可采用全文检索方式搜索,比如百度,Google等搜索引擎,论坛搜索,电商网站站内搜索等。
2. Lucene实现全文检索的流程
下面这张图足以说明索引的流程

(1) 绿色表示索引过程,对要搜索的原始内容进行内容进行索引构建一个索引库,索引过程包括:确定原始内容即要搜索的内容—>采集文档—>分析文档—>索引文档
(2) 红色表示搜索过程;从索引库红搜索内容,过程为:用户通过搜索界面—>创建查询—>执行搜索,从索引库搜索—>渲染搜索结果
从互联网上,数据库,文件系统中等获取需要搜索的原始信息,这个过程就是信息采集,信息采集的目的是为了对原始内容进行索引。
在Internet上采集信息的软件一般称为爬虫或蜘蛛,也成为网络机器人,爬虫访问互联网上的每一个网页,将获取到的网页内容存储起来。
Lucene不提供信息才加的类库,需要自己编写一个爬虫程序实现信息采集,也可以通过Nutch,jsoup,heritrix等一些开源软件实现信息采集。
3.创建索引
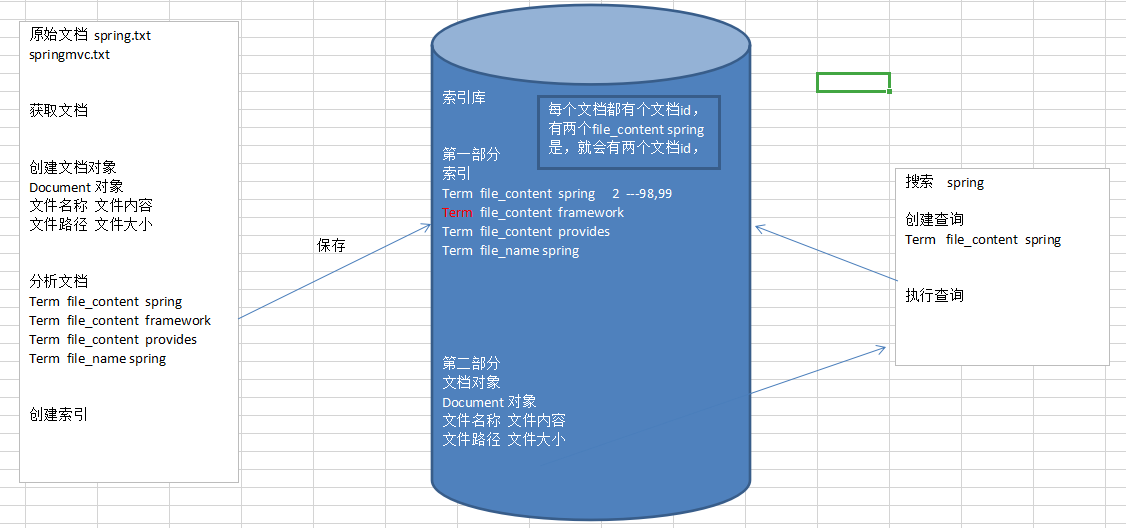
根据上图,创建索引。获得文档暂时就不做了。
(1) 创建文档对象
获取原内容的目的是为了索引,在索引前需要将原始内容创建成文档,文档中包括一个一个的域(Field),域中存储内容。
可以将磁盘上的一个文件当成一个document,Document中包括一些Field(file_name文件名称,file_path文件路径,file_size文件大小,file_content文件内容),如下图

注意:每个Document可以有多个Field,不同的Dcument可以有不同的Field,同一个Document可以有相同的域(Field)
每个文档有唯一的编号,就是文档Id
(2) 分析文档(分词)
将原始内容创建为包含域(Field)的文档(document),需要在对域中的内容进行分析,分析的过程是经对原始文档提取单词,将字母转为小写,去除标点符号,取出停用词等过程生成最终的语汇单元,可以将语汇单元理解为一个个单词。
每个单词叫做一个Term,不同的域中拆分出来的相同的单词是不同的Term。Term中包含两部分一部分是文档的域名,另一部分是单词的内容。相当于Trem<K, V> 例如:文件名中包含apache和文件内容中包含apache是不同的Term。
(3) 创建索引
对所有文档分析得出的语汇单元进行索引,索引的目的是为了搜索,最终要实现只搜索被索引的语汇单元从而找到Document(文档)。
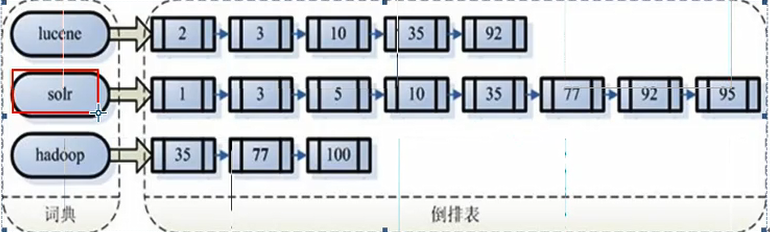
注意:创建索引是对语汇单元索引,通过词语找文档,这种索引的结构叫倒排索引结构。
传统方法是根据文件找到文件的内容,在文件内容中匹配搜索关键字,这种方法是顺序扫面方法,数据量大,搜索慢。
倒排索引结构是根据内容(词语)找文档:

倒排索引结构也叫反向索引结构,包括索引和文档两部分,索引即词汇表。它的规模较小,而文档集合较大。
4.查询索引
(1) 用户查询接口
全文检索系统提供用户搜索的界面供用户提交搜索的关键字,搜索完成展示搜索结果:比如百度搜索框
(2) 创建查询
用户输入查询关键字执行搜索之前需要限购件一个查询对象,查询对象中可以指定查询要搜索的Field文档域,查询关键字等,查询对象会生成具体的查询语法。
例如:语法 “fileName:lucene” 表示要搜索Filed域"fileName"的内容为"lucene"的文档
(3) 执行查询
倒排索引查询,搜索索引过程:根据查询语法在倒排索引词典表中分表找出对应搜索词的索引,从而找到索引所链接的文档链表。
例如:搜索语法为“fileName:lucene”表示搜索出fileName域中包含lucene的文档。
搜索过程就是在索引上查找域为fileName,并且关键之为lucene的Term,并根据term找到文档id列表。
搜索到的文档不止一个,所以是列表形式
(4) 渲染结果
lucene&solr学习——创建和查询索引(理论)的更多相关文章
- lucene&solr学习——创建和查询索引(代码篇)
1. Lucene的下载 Lucene是开发全文检索功能的工具包,从官网下载Lucene4.10.3并解压. 官网:http://lucene.apache.org/ 版本:lucene7.7.0 ( ...
- lucene&solr学习——solr学习(二) Solr管理索引库
1.什么是solrJ solrj是访问Solr服务的java客户端,提供索引和搜索的请求方法,SolrJ通常在嵌入在业务系统中,通过SolrJ的API接口操作Solr服务,如下图: 依赖jar包: 2 ...
- lucene&solr学习——solr学习(一)
1.什么是solr solr是Apache下的一个顶级开源项目,采用Java开发,它是基于Lucene的全文检索服务器.Solr提供了比lucene风味丰富的查询语言,同时实现了可配置,可扩展,并对索 ...
- lucene&solr学习——索引维护
1.索引库的维护 索引库删除 (1) 全删除 第一步:先对文档进行分析 public IndexWriter getIndexWriter() throws Exception { // 第一步:创建 ...
- lucene&solr学习——分词器
下图是语汇单元的生成过程: 从一个Reader字符流开始,创建基于Reader的Tokenizer分词器,经过三个TokenFilter生成语汇单元Tokens. 要看分词器的分析效果,只需要看Tok ...
- solr 学习片段
全文检索技术——Solr 1 主要内容 1.站内搜索技术选型 2.什么是solr Solr和lucene的区别 3.solr服务器的安装及配置 Solr整合tomcat Solr的演示 4.维护索引 ...
- 搜索引擎学习(三)Lucene查询索引
一.查询理论 创建查询:构建一个包含了文档域和语汇单元的文档查询对象.(例:fileName:lucene) 查询过程:根据查询对象的条件,在索引中找出相应的term,然后根据term找到对应的文档i ...
- 学习笔记CB011:lucene搜索引擎库、IKAnalyzer中文切词工具、检索服务、查询索引、导流、word2vec
影视剧字幕聊天语料库特点,把影视剧说话内容一句一句以回车换行罗列三千多万条中国话,相邻第二句很可能是第一句最好回答.一个问句有很多种回答,可以根据相关程度以及历史聊天记录所有回答排序,找到最优,是一个 ...
- Lucene.net(4.8.0) 学习问题记录三: 索引的创建 IndexWriter 和索引速度的优化
前言:目前自己在做使用Lucene.net和PanGu分词实现全文检索的工作,不过自己是把别人做好的项目进行迁移.因为项目整体要迁移到ASP.NET Core 2.0版本,而Lucene使用的版本是3 ...
随机推荐
- [html/js]点击标题出现下拉列表
效果 初始 点击后 参考代码 <!DOCTYPE html> <html> <head> <title>Layer group example</ ...
- 用Gvim建立IDE编程环境 (Windows篇)
转自:http://my.oschina.net/kontor/blog/50717 0.准备软件及插件.(a)gvim72.exe 地址ftp://ftp.vim.org/pub/vim/pc/gv ...
- C# 服务端控件 asp:RadioButton 选择选中值
1.服务端控件RadioButton <asp:RadioButton ID="rbNewUser" runat="server" GroupName=& ...
- [转]Debugging into .NET Core源代码的两种方式
本文转自:http://www.cnblogs.com/maxzhang1985/p/6015719.html 阅读目录 一.前言 二.符号服务器 三.项目中添加ASP.NET Core源代码 四.写 ...
- ThinkPHP3.2 整合支付宝RSA加密方式
RSA核心加密验证算法 <?php /** * RSA签名 * @param $data 待签名数据 * @param $private_key 商户私钥字符串 * return 签名结果 */ ...
- 2017年10月9日 冒泡&去重复习
今天看了一下,就是数组跟js还是不太熟悉 冒泡排序 var arr = [4, 2, 1, 3, 6, 5]; for(var i = 1; i < arr.length; ...
- mac解决系统设置安全与隐私没有允许所有来源
解决系统设置安全与隐私没有允许所有来源:sudo spctl --master-disable
- hdu 3265 矩形剪块面积并
http://acm.hust.edu.cn/vjudge/problem/10769 给n张海报,在每张海报上剪掉一个矩形,求面积并 把剪块的海报分成四个矩形,就是普通的求面积并问题了 #inclu ...
- JS基础学习——闭包
JS基础学习--闭包 什么是闭包 闭包的定义如下,它的意思是闭包使得函数可以记住和访问它的词法范围,即使函数是在它声明的词法范围外执行.更简单来讲,函数为了自己能够正确执行,它对自己的词法范围产生闭包 ...
- Web前端面试指导(八):iframe有那些缺点
本题的特点 这道题目的特点就是不按照正常的套路来提问,一般都是问优点,这里比较反常问iframe的缺点,很多同学肯定很不习惯这种问答,因为平时只关注有点,这么一问就懵逼了! 本题解答的思路及要点 ① ...