C#爬虫系列(一)——国家标准全文公开系统
网上有很多Python爬虫的帖子,不排除很多培训班借着AI的概念教Python,然后爬网页自然是其中的一个大章节,毕竟做算法分析没有大量的数据怎么成。
C#相比Python可能笨重了些,但实现简单爬虫也很便捷。网上有不少爬虫工具,通过配置即可实现对某站点内容的抓取,出于定制化的需求以及程序员重复造轮子的习性,我也做了几个标准公开网站的爬虫。
在学习的过程中,爬网页的难度越来越大,但随着问题的一一攻克,学习到的东西也越来越多,从最初简单的GET,到POST,再到模拟浏览器填写表单、提交表单,数据解析也从最初的字符串处理、正则表达式处理,到HTML解析。一个NB的爬虫需要掌握的知识不少,HTTP请求、响应,HTML DOM解析,正则表达式匹配内容,多线程、数据库存储,甚至有些高级验证码的处理都得AI。
当然,爬爬公开标准不是那么难,比如国家标准全文公开系统。
整个过程需要爬以下页面:
- 列表页
- 详细信息页
- 文件下载页
需要处理的技术问题有:
- HTTP请求
- 正则表达式
- HTML解析
- SqlLite数据库存储
一、列表页
首先查看到标准分GB和GB/T两类,地址分别为:
http://www.gb688.cn/bzgk/gb/std_list_type?p.p1=1&p.p90=circulation_date&p.p91=desc
和
http://www.gb688.cn/bzgk/gb/std_list_type?p.p1=2&p.p90=circulation_date&p.p91=desc。
从中可以看出,GET请求的查询字符串参数p1值为1和2分别查询到GB和GB/T。因此,要获取到标准列表,向以上地址发送GET请求即可。
HttpWebRequest httprequst = (HttpWebRequest)WebRequest.Create(Url);
HttpWebResponse webRes = (HttpWebResponse)httprequst.GetResponse();
using (System.IO.Stream stream = webRes.GetResponseStream())
{
using (System.IO.StreamReader reader = new StreamReader(stream, System.Text.Encoding.GetEncoding("utf-8")))
{
content = reader.ReadToEnd();
}
}
标准共N多页,查看第二页标准列表,地址更改为:
http://www.gb688.cn/bzgk/gb/std_list_type?r=0.7783908698326173&page=2&pageSize=10&p.p1=1&p.p90=circulation_date&p.p91=desc。
由此可见page参数指定了分页列表的当前页数,据此,循环请求即可获取到所有的标准列表信息。
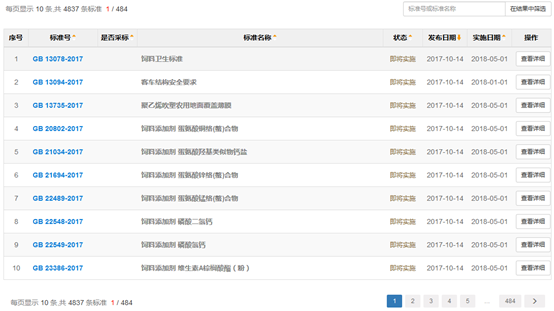
二、详细信息页
获取到标准列表后,下一步我需要获取到标准的详细信息页,从详细信息页中抓取更多的标准说明信息,例如标准的发布单位、归口单位等。
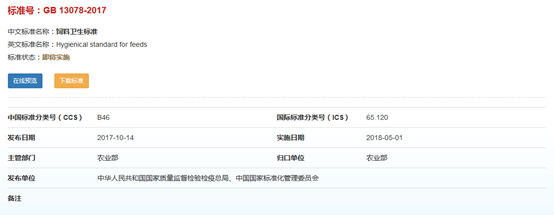
查看标准详细页URL,其值为:
http://www.gb688.cn/bzgk/gb/newGbInfo?hcno=9E5467EA1922E8342AF5F180319F34A0。
可以看出每个标准有个GUID值,在列表页面中点击按钮“查看详细”,转到详细页。实现这个跳转的方式,最简单的是HTML超链接,此外还可以是JS脚本,甚至是POST数据到服务器。不同的链接方式,自然需要不同的抓取方式,因此需要查看列表页源码来分析该站点的实现方式并找到对应的处理方法。

通过分析源码,可以看到在点击标准号时,通过JS的showInfo函数打开详细页面,由于JS方法传递的ID即为详细页面的参数ID,因此没必要去模拟onclick执行JS函数,直接解析到该GUID,GET请求详细页面即可。解析该GUID值,可以通过正则表达式方便的抓取到。
获取到详细信息页面后,要解析其中的内容,此时使用正则表达式解析就比较费劲了,可以采用HTML解析。C#解析HTML的第三方类库有不少,选择其中一款即可,HtmlAgilityPack或Winista.HtmlParser都是比较好用的。
三、文件下载页
解析到标准详细信息后,还需要进一步获取到标准PDF文件,分析详细页面可以看到标准文件下载页面路径为:
http://c.gb688.cn/bzgk/gb/showGb?type=download&hcno=9E5467EA1922E8342AF5F180319F34A0

进一步分析PDF文件的URL为:
http://c.gb688.cn/bzgk/gb/viewGb?hcno=9E5467EA1922E8342AF5F180319F34A0。
仍然是那个GUID值,因此可以直接GET请求该地址即可下载标准PDF文件。
至此标准的属性信息和标准PDF文件都可以下载到了,然后需要将这些信息存储起来。存储为SQL Server、Oracle自然比较笨重,即使Excel和Access也不大友好,推荐此类临时存储可以使用SqlLite。
string connectionString = @"Data Source=" + dbBasePath + "StandardDB.db;Version=3;";
m_dbConnection = new SQLiteConnection(connectionString);
m_dbConnection.Open();
SQLiteCommand command = new SQLiteCommand(sql, m_dbConnection);
command.ExecuteNonQuery();
m_dbConnection.Close();
C#爬虫系列(一)——国家标准全文公开系统的更多相关文章
- C#爬虫系列(二)——食品安全国家标准数据检索平台
上篇对“国家标准全文公开系统”的国标进行抓取,本篇对食品领域的标准公开系统“食品安全国家标准数据检索平台”进行抓取. 平台地址:http://bz.cfsa.net.cn/db 一.标准列表 第一步还 ...
- python3爬虫系列19之反爬随机 User-Agent 和 ip代理池的使用
站长资讯平台:python3爬虫系列19之随机User-Agent 和ip代理池的使用我们前面几篇讲了爬虫增速多进程,进程池的用法之类的,爬虫速度加快呢,也会带来一些坏事. 1. 前言比如随着我们爬虫 ...
- python 全栈开发,Day134(爬虫系列之第1章-requests模块)
一.爬虫系列之第1章-requests模块 爬虫简介 概述 近年来,随着网络应用的逐渐扩展和深入,如何高效的获取网上数据成为了无数公司和个人的追求,在大数据时代,谁掌握了更多的数据,谁就可以获得更高的 ...
- Java爬虫系列之实战:爬取酷狗音乐网 TOP500 的歌曲(附源码)
在前面分享的两篇随笔中分别介绍了HttpClient和Jsoup以及简单的代码案例: Java爬虫系列二:使用HttpClient抓取页面HTML Java爬虫系列三:使用Jsoup解析HTML 今天 ...
- Java爬虫系列二:使用HttpClient抓取页面HTML
爬虫要想爬取需要的信息,首先第一步就要抓取到页面html内容,然后对html进行分析,获取想要的内容.上一篇随笔<Java爬虫系列一:写在开始前>中提到了HttpClient可以抓取页面内 ...
- 爬虫系列(四) 用urllib实现英语翻译
这篇文章我们将以 百度翻译 为例,分析网络请求的过程,然后使用 urllib 编写一个英语翻译的小模块 1.准备工作 首先使用 Chrome 浏览器打开 百度翻译,这里,我们选择 Chrome 浏览器 ...
- Wix打包系列(七) 添加系统必备组件的安装程序
原文:Wix打包系列(七) 添加系统必备组件的安装程序 我们知道在vs的打包工程中添加系统必备组件是一件很容易的事情,那么在wix中如何检测系统必备组件并在安装过程中安装这些组件.这里以.Net Fr ...
- java爬虫系列第一讲-爬虫入门
1. 概述 java爬虫系列包含哪些内容? java爬虫框架webmgic入门 使用webmgic爬取 http://ady01.com 中的电影资源(动作电影列表页.电影下载地址等信息) 使用web ...
- java爬虫系列目录
1. java爬虫系列第一讲-爬虫入门(爬取动作片列表) 2. java爬虫系列第二讲-爬取最新动作电影<海王>迅雷下载地址 3. java爬虫系列第三讲-获取页面中绝对路径的各种方法 4 ...
随机推荐
- github 项目绑定自己的域名
上周脑子发热申请了自己的一个域名.本想搞一个自己的网站,后来囊中羞涩,数据库,服务器..买不起了,只买个域名,发现啥也搞不成.后来突然想到了不行找个东西映射到这个域名上吧,就想到了github,之前也 ...
- swift 之 mustache模板引擎
用法: Variable Tags {{name}} 用来渲染值name datas: let data = ["value": "test"] ------- ...
- CentOS7安装GitLab、汉化、邮箱配置及使用
同步首发:http://www.yuanrengu.com/index.php/20171112.html 一.GitLab简介 GitLab是利用Ruby On Rails开发的一个开源版本管理系统 ...
- Android模拟器调试html5 app
主机:Linux x641.Android模拟器,模拟器设置--->打开Enable Usb Debug2.在主机上安装firefox,最低v36.菜单--->开发者--->WebI ...
- Turn the corner
Turn the corner Time Limit: 3000/1000 MS (Java/Others) Memory Limit: 32768/32768 K (Java/Others) Tot ...
- Entropy
Entropy Time Limit: 2000/1000 MS (Java/Others) Memory Limit: 65536/32768 K (Java/Others) Total Submi ...
- 关于php的命名空间
php定义命名空间要使用namespace关键字,例:namespace Database 使用命名空间中的类要使用use关键字,也可以在use后面加as给类取别名,例:use Database\SQ ...
- keepalived中的脑裂
在高可用(HA)系统中,当联系2个节点的“心跳线”断开时,本来为一整体.动作协调的HA系统,就分裂成为2个独立的个体.由于相互失去了联系,都以为是对方出了故障.两个节点上的HA软件像“裂脑人”一样,争 ...
- Python-week1,第一周(基于Python3.0以上)
1,变量 准确来说不是第一周学习了吧,应该是采用博客记录学习的第一周,记录并做个笔记吧,可能做的不好,但我高兴啊,废话不说了,上图. 学习过程中做的一些笔记,当然能面面俱到,只能在写博客的时候又能复习 ...
- 网页头部 lang的声明
1. 简体中文页面:html lang=zh-cmn-Hans2. 繁体中文页面:html lang=zh-cmn-Hant3. 英语页面:html lang=en 4. <回来>的音频, ...