[原创]HBase学习笔记(4)- 数据导入
需要分别从Oracle和文本文件往HBase中导入数据,这里介绍几种数据导入方案。
1.使用importTSV导入HBase
importTSV支持增量导入。新数据插入,已存在数据则修改。
1.1.首先将待导入文本test_import.txt放到hdfs集群
文本格式如下(从网上找的虚拟话单数据)。逗号分隔,共13个字段,其中第1个字段作为rowkey。
1,12026546272,2013/10/19,20:52,33分18秒,被叫,13727310234,北京市,省际,0,32.28,0.4,全球通商旅88套餐
2,12026546272,2013/10/19,20:23,33分18秒,被叫,13727310234,北京市,省际,0,32.28,0.4,全球通商旅88套餐
3,16072996404,2013/10/19,20:52,10分52秒,主叫,19271253211,北京市,省际,0,2.8,1.9,全球通商旅88套餐
4,10023895821,2013/10/19,20:52,09分20秒,被叫,15115468122,绵阳市,省内,0,45.91,5.26,全球通商旅88套餐
5,13381653644,2013/10/19,20:53,06分00秒,被叫,10991482287,北京市,省际,0,54.79,7.16,全球通商旅88套餐
6,18695195919,2013/10/19,21:37,27分00秒,主叫,14858652217,绵阳市,省内,0,36.27,6.68,全球通商旅88套餐
7,11396010469,2013/10/19,21:37,27分02秒,主叫,12939968466,绵阳市,省内,0,65.63,4.45,全球通商旅88套餐
8,15109754362,2013/10/19,21:37,05分00秒,被叫,14240771580,绵阳市,省内,0,66.86,5.75,全球通商旅88套餐
9,13845944798,2013/10/19,21:37,13分50秒,被叫,13648619896,广州市,省际,0,60.71,3.39,全球通商旅88套餐
10,17883953443,2013/10/19,21:38,37分54秒,被叫,10110778698,广州市,省际,0,55.14,1.45,全球通商旅88套餐
11,19643495044,2013/10/19,21:38,49分34秒,主叫,14581482419,广州市,省际,0,16.84,1.36,全球通商旅88套餐
1.2.在HBase中创建表:create ‘test_import’, ‘cf’
1.3.使用importTSV导入

执行命令:
$hbase org.apache.hadoop.hbase.mapreduce.ImportTsv -Dimporttsv.separator="," -Dimporttsv.columns=HBASE_ROW_KEY,cf:field1,cf:field2,cf:field3,cf:field4,cf:field5,cf:field6,cf:field7,cf:field8,cf:field9,cf:field10,cf:field11,cf:field12 test_import /test_import.txt
其中:
-Dimporttsv.separator指定分隔符,只支持单字节分隔符。
-Dimporttsv.columns指定导入的列。HBASE_ROW_KEY是关键字,导入数据时必须指定rowkey。
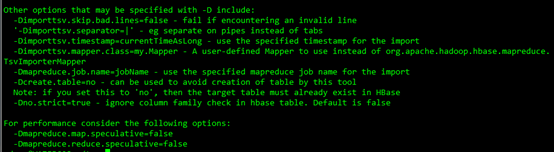
其它可选参数:
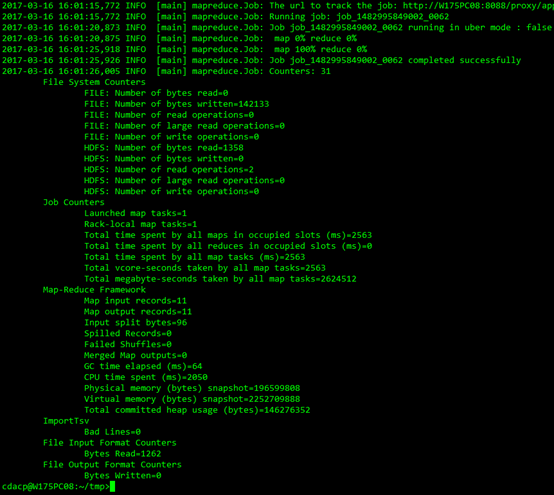
执行后自动提交MapReduce任务进行导入:
1.4.用scan命令查看hbase中test_import表的内容


一共11条记录。
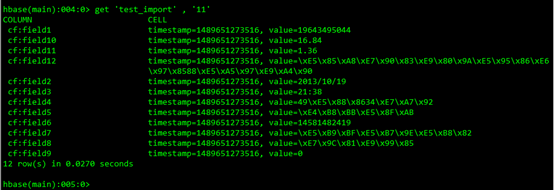
1.5.使用get查看记录
2.使用importTSV+bulkload导入HBase
先使用importTSV生成HFile文件,再使用bulkload导入HBase。
这种方式对RegionServer更友好一些,加载数据几乎不占用RegionServer的计算资源,只是在HDFS上移动HFile文件,然后通过HMaster将该RegionServer的一个或多个Region上线。
2.1.生成HFile文件
使用importTSV生成HFile文件。与上一中方法略有不同的是,在importTSV执行时指定-Dimporttsv.bulk.output参数,则是生成HFile文件到指定文件,而不会直接导入HBase表。
$hbase org.apache.hadoop.hbase.mapreduce.ImportTsv -Dimporttsv.separator="," -Dimporttsv.columns=HBASE_ROW_KEY,cf:field1,cf:field2,cf:field3,cf:field4,cf:field5,cf:field6,cf:field7,cf:field8,cf:field9,cf:field10,cf:field11,cf:field12 -Dimporttsv.bulk.output=/test_import_outputdir/ test_import /test_import.txt
查看/test_import_outputdir/数据:
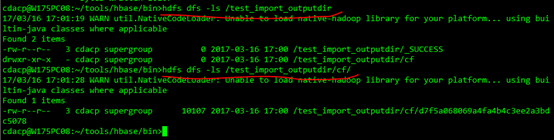
2.2.导入HBase表
使用bulkload导入HBase表。执行速度非常快。

执行命令:
$hbase org.apache.hadoop.hbase.mapreduce.LoadIncrementalHFiles /test_import_outputdir/ test_import
2.3.使用get查看记录
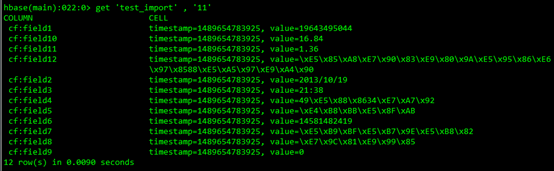
3.支持多字节分隔符导入HBase
importTSV只支持单字节分隔符,不支持多字节分隔符,比如“|@|”。如果要实现多字节分隔符,需要自己编写MapReduce作业生成HFile文件,或者导入HBase。
3.1.数据格式
待导入数据如下。|@|作为分隔符,第1个字段是主键。
1|@|12026546272|@|2013/10/19|@|20:52|@|33分18秒|@|被叫|@|13727310234|@|北京市|@|省际|@|0|@|32.28|@|0.4|@|全球通商旅88套餐
2|@|12026546272|@|2013/10/19|@|20:23|@|33分18秒|@|被叫|@|13727310234|@|北京市|@|省际|@|0|@|32.28|@|0.4|@|全球通商旅88套餐
......
......
......
3.2.编写Mapper生成HFile
我们只要使用1个Mapper生成HFile即可,不需要额外写Reducer。示例代码如下。
public class HfileGenMapper extends Mapper<LongWritable, Text, ImmutableBytesWritable, KeyValue> {
protected void map(LongWritable key, Text value,
Mapper<LongWritable, Text, ImmutableBytesWritable, KeyValue>.Context context)
throws IOException, InterruptedException {
// 第一个字段作为rowkey
ImmutableBytesWritable rowkey = new ImmutableBytesWritable(
value.toString().split("\\|@\\|")[0].getBytes());
List<KeyValue> list = createKeyValue(value.toString());
Iterator<KeyValue> itor = list.iterator();
while (itor.hasNext()) {
KeyValue kv = itor.next();
if (kv != null) {
context.write(rowkey, kv);
}
}
}
// 解析一行记录,得到多个KeyValue对象。
private List<KeyValue> createKeyValue(String line) {
List<KeyValue> list = new ArrayList<KeyValue>();
String[] fields = line.split("\\|@\\|");
String rowkey = fields[0];
String columnFamily = "cf";
for (int i = 1; i < fields.length; i++) {
String qualifyName = "field" + String.valueOf(i);
String value = fields[i];
KeyValue kv = new KeyValue(rowkey.getBytes(), columnFamily.getBytes(),
qualifyName.getBytes(), System.currentTimeMillis(), value.getBytes());
list.add(kv);
}
return list;
}
}
3.3.创建作业实例
创建job实例,填写相关配置。指定输入输出数据,设置Mapper和Reducer,并提交作业。
public class BulkLoadHFileJob extends Configured implements Tool {
public static void main(String[] args) throws Exception {
int status = ToolRunner.run(new BulkLoadHFileJob(), args);
System.exit(status);
}
@Override
public int run(String[] args) throws Exception {
this.setConf(HBaseConfiguration.create(this.getConf()));
getConf().set("hbase.zookeeper.property.clientPort", "2181");
getConf().set("hbase.zookeeper.quorum", "W122PC04VM07,W122PC05VM07,W122PC06VM07");
String inputPath = "hdfs://cluster1/test_import2.txt";
String outputPath = "hdfs://cluster1/test_import2_outputdir";
Job job = Job.getInstance(getConf(), "Hdfs2HFile test");
job.setJarByClass(BulkLoadHFileJob.class);
job.setInputFormatClass(TextInputFormat.class);
job.setMapperClass(HfileGenMapper.class);
job.setReducerClass(KeyValueSortReducer.class);
job.setMapOutputKeyClass(ImmutableBytesWritable.class);
job.setMapOutputValueClass(KeyValue.class);
job.setOutputFormatClass(HFileOutputFormat2.class);
job.setPartitionerClass(SimpleTotalOrderPartitioner.class);
FileInputFormat.addInputPath(job, new Path(inputPath));
FileOutputFormat.setOutputPath(job, new Path(outputPath));
Connection connection = ConnectionFactory.createConnection(getConf());
TableName tableName = TableName.valueOf("table_test");
HFileOutputFormat2.configureIncrementalLoad(job, connection.getTable(tableName), connection.getRegionLocator(tableName));
return job.waitForCompletion(true) ? 0 : 1;
}
}
3.4.提交作业
使用hadoop客户端提交作业。
hadoop jar ./hbasetest.jar com.hbase.test.hdfs2hbase.BulkLoadHFileJob
3.5.导入HBase
使用bulkload将生成的HFile导入HBase,速度非常快。具体操作步骤参考2.2节。
[原创]HBase学习笔记(4)- 数据导入的更多相关文章
- ArcGIS案例学习笔记_3_2_CAD数据导入建库
ArcGIS案例学习笔记_3_2_CAD数据导入建库 计划时间:第3天下午 内容:CAD数据导入,建库和管理 目的:生成地块多边形,连接属性,管理 问题:CAD存在拓扑错误,标注位置偏移 教程:pdf ...
- [原创]HBase学习笔记(1)-安装和部署
HBase安装和部署 使用的HBase版本是1.2.4 1.安装步骤(默认hdfs已安装好) # 下载并解压安装包 cd tools/ tar -zxf hbase-1.2.4-bin.tar.gz ...
- [原创]HBase学习笔记(3)- Java程序访问HBase
这里介绍使用java api来访问和操作HBase,例如create.delete.select.update等操作. 1.HBase配置 配置HBase使用的zookeeper集群地址和端口. pr ...
- [原创]HBase学习笔记(2)- 基本操作
1.使用hbase shell连接hbase 2.输入help可以查看帮助 3.输入list查看当前hbase中的所有表 4.使用create创建表test 其中test是表名,cf是列族.该表只创建 ...
- GIS案例学习笔记-CAD数据分层导入现有模板实例教程
GIS案例学习笔记-CAD数据分层导入现有模板实例教程 联系方式:谢老师,135-4855-4328,xiexiaokui#qq.com 1. 原始数据: CAD数据 目标模板 2. 任务:分5个图层 ...
- ArcGIS案例学习笔记-CAD数据自动拓扑检查
ArcGIS案例学习笔记-CAD数据自动拓扑检查 联系方式:谢老师,135-4855-4328,xiexiaokui#qq.com 功能:针对CAD数据,自动进行拓扑检查 优点:类别:地理建模项目实例 ...
- HBase学习笔记之HBase的安装和配置
HBase学习笔记之HBase的安装和配置 我是为了调研和验证hbase的bulkload功能,才安装hbase,学习hbase的.为了快速的验证bulkload功能,我安装了一个节点的hadoop集 ...
- HBASE学习笔记(四)
这两天把要前几天的知识点回顾一下,接下来我会用自己对知识点的理解来写一些东西 一.知识点回顾 1.hbase集群启动:$>start-hbase.sh ===>hbase-daemon.s ...
- Windows phone 8 学习笔记(2) 数据文件操作
原文:Windows phone 8 学习笔记(2) 数据文件操作 Windows phone 8 应用用于数据文件存储访问的位置仅仅限于安装文件夹.本地文件夹(独立存储空间).媒体库和SD卡四个地方 ...
随机推荐
- php类与构造函数解析
关于类大家都有一定的认识这里只介绍在php中类值得注意的地方----类的创建----php使用关键字class创建一个类,并且使用一对大括号如: class name{ public $n=" ...
- JavaScript从作用域到闭包
目录 作用域 全局作用域和局部作用域 块作用域与函数作用域 作用域中的声明提前 作用域链 函数声明与赋值 声明式函数.赋值式函数与匿名函数 代码块 自执行函数 闭包 作用域(scope) 全局作用域 ...
- node Express安装与使用(一)
首先放上官网地址 http://www.expressjs.com.cn/ 学会查阅官方手册,它是最好的资料. 1.Express安装 首先确定你已经安装了 Node.js,然后去你创建的项目目录下( ...
- Eclipse / Intellij Idea配置Git+Maven+Jetty开发环境
作者:鹿丸不会多项式 出处:http://www.cnblogs.com/hechao123 转载请先与我联系. 最近公司给加配了Mac,本想着花一个小时的时间搭好开发环境,最后全部弄好却用了一上午 ...
- 为什么Java可以跨平台,而其他语言不行
你好 我是大福 你现在看的是大福笔记 今天复习了Java语言的概述 内容包括Java 语言的历史.语言特点及平台版本 JRE和JDK的区别 这篇文章的主题是总结下对Java语言特点中的跨平台原理. 在 ...
- vb是如何连接数据库的
vb是如何连接数据库的 刚开始学习数据库时 ,对数据库很不了解,尤其是模块中的代码.照着抄都有很多错的,每一句到底是什么意思呢,根本不懂.于是我就花费了大量的时间去查每一句代码的具体作 ...
- Vue.js的环境搭建
vue这个新的工具,确实能够提高效率,vue入门的精髓:(前提都是在网络连接上的情况下) 1.要使用vue来开发前端框架,首先要有环境,这个环境要借助于node,所以要先安装node,借助于node里 ...
- 缓冲流自动把getchar()填充
#include"stdio.h" #include"conio.h" #include<stdlib.h> int main() { char c ...
- 【问题解决】使用自定义控件时,vs停止工作
问题表现:向页面中添加自定义控件时,vs卡住了,随便点击一下,然后窗口未响应,然后用资源管理器看到内存使用在飙升,监视进程会发现就是vs的进程出现了异常 问题的解决:菜鸟D在网上搜了一下,发现一个奇葩 ...
- BZOJ 1076: [SCOI2008]奖励关(概率+dp)
首先嘛,看了这么久概率论真的不错啊。看到就知道怎么写(其实也挺容易的= =) 直接数位dp就行了 CODE: #include<cstdio> #include<cstring> ...