记 suds 模块循环依赖的坑-RuntimeError: maximum recursion depth exceeded
下面是soa接口调用的核心代码
#! /usr/bin/python
# coding:utf-8
from suds.client import Client
def SoaRequest(wsdl,fnname,data):
soaService = Client(wsdl).service
soaRep = getattr(soaService,fnname)(data)
return soaRep
问题就这样出现了:
我调用一个接口,总是报错,见下图:
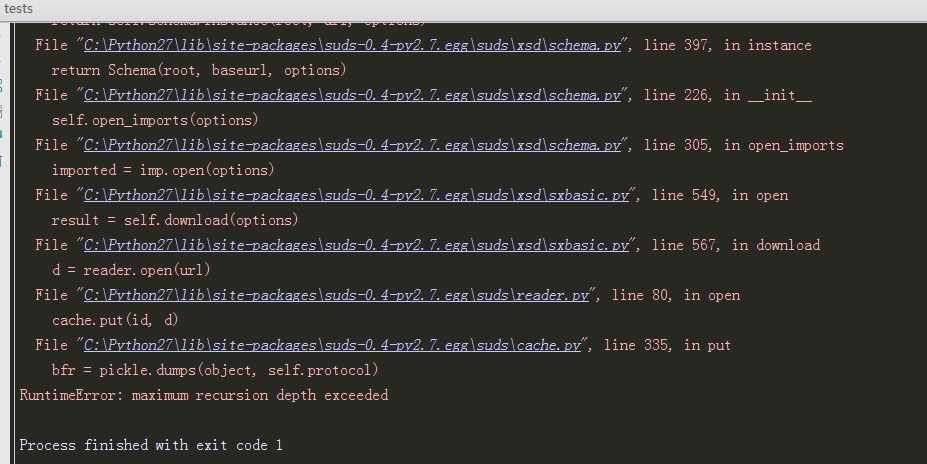
之后Debug断点定位到suds模块的sxbasic.py文件中的Import类的open方法
def open(self, options):"""
Open and import the refrenced schema.
@param options: An options dictionary.
@type options: L{options.Options}
@return: The referenced schema.
@rtype: L{Schema}
"""
if self.opened:
return
self.opened = True
log.debug('%s, importing ns="%s", location="%s"', self.id, self.ns[1], self.location)
result = self.locate() if result is None:
if self.location is None:
log.debug('imported schema (%s) not-found', self.ns[1])
else:
result = self.download(options)
log.debug('imported:\n%s', result)
return result
self.location 为None时日志打印,否则就执行download
而我测试的接口有个这种问题,A中依赖B,B中依赖C,C中依赖A,循环依赖
运行后控制台就会报错:
RuntimeError: maximum recursion depth exceeded 是不是递归深度不够呢(个人觉得循环的话,深度再大有什么用了)
import sys
sys.setrecursionlimit(1000000)
设置100万的递归深度,再运行直接 stack overflow,溢出了
好吧,那就改吧
在类Import外定义数组变量resultList = []
def open(self, options):
global resultList
if self.opened:
return
self.opened = True
log.debug('%s, importing ns="%s", location="%s"', self.id, self.ns[1], self.location)
result = self.locate() if result is None:
if self.location is None:
log.debug('imported schema (%s) not-found', self.ns[1])
else:
if self.location in resultList: #若location存在List中,则打印debug日志,不加载options
log.debug('location is already in resultList')
else:
resultList.append(self.location) #location不存在时,List中append后,加载options
result = self.download(options)
log.debug('imported:\n%s', result)
return result
去除了循环依赖,出现另外一个问题:
先看下我soap接口的通用调用方法:
#! /usr/bin/python
# coding:utf-8
import sys
reload(sys)
sys.setdefaultencoding( "utf-8" )
from suds.client import Clientdef SoaRequest(wsdl,fnname,data): #soap接口调用方法
soaService = Client(wsdl).service
soaRep = getattr(soaService,fnname)(data)
return soaRep
通过这个方法去逐行调用excel中的用例参数,来实现数据驱动的接口自动化框架
但是单个接口,多组参数用例的组合场景,运用上面的脚本后就报错

Type not found.......
考虑到可能是因为第一行用例执行过程中,在List中append 进location,到执行第二条用例的时候,由于和第一行用例的接口是一样的,故而List判断中就没有进入到download分支,所以就抛出了not found的异常
解决方法是在执行用例前,清空list
改造soap接口核心调用程序
#! /usr/bin/python
# coding:utf-8
import sys
reload(sys)
sys.setdefaultencoding( "utf-8" )
from suds.client import Client
from suds.xsd import sxbasic
def SoaRequest(wsdl,fnname,data): #soap接口调用方法
sxbasic.resultList=[] #初始化location列表
soaService = Client(wsdl).service
soaRep = getattr(soaService,fnname)(data)
return soaRep
这样就万事大吉了
如果有人有更好的解决方案,更简便的处理方法,欢迎沟通交流 本人邮箱:270193176@qq.com
记 suds 模块循环依赖的坑-RuntimeError: maximum recursion depth exceeded的更多相关文章
- Python递归报错:RuntimeError: maximum recursion depth exceeded in comparison
Python中默认的最大递归深度是989,当尝试递归第990时便出现递归深度超限的错误: RuntimeError: maximum recursion depth exceeded in compa ...
- python递归深度报错--RuntimeError: maximum recursion depth exceeded
当你的程序递归的次数超过999次的时候,就会引发RuntimeError: maximum recursion depth exceeded. 解决方法两个: 1.增加系统的递归调用的次数: impo ...
- scrapy RuntimeError: maximum recursion depth exceeded while calling a Python object 超出python最大递归数异常
2019-10-21 19:01:00 [scrapy.core.engine] INFO: Spider opened2019-10-21 19:01:00 [scrapy.extensions.l ...
- 函数递归时,递归次数到900多时,就是抛出异常exception RuntimeError('maximum recursion depth exceeded',)
import subprocess import multiprocessing import urllib import sys import os import pymongo import si ...
- 这个 Spring 循环依赖的坑,90% 以上的人都不知道
1. 前言 这两天工作遇到了一个挺有意思的Spring循环依赖的问题,但是这个和以往遇到的循环依赖问题都不太一样,隐藏的相当隐蔽,网络上也很少看到有其他人遇到类似的问题.这里权且称他非典型Spring ...
- 一起来踩踩 Spring 中这个循环依赖的坑
1. 前言 2. 典型场景 3. 什么是依赖 4. 什么是依赖调解 5. 为什么要依赖注入 6. Spring的依赖注入模型 7. 非典型问题 参考资料 1. 前言 这两天工作遇到了一个挺有意思的Sp ...
- RequireJS 循环依赖报 模块undefined 处理方案
RequireJS 循环依赖 开始学习使用RequireJS之后做了几个小例子,之后想着把手头的项目也用RequireJS写一遍试试.感觉胜利就在前方了,忽然发现始终卡在一个问题上: 很常见的一个问题 ...
- kmdjs和循环依赖
循环依赖 循环依赖是非常必要的,有的程序写着写着就循环依赖了,可以提取出一个对象来共同依赖解决循环依赖,但是有时会破坏程序的逻辑自封闭和高内聚.所以没解决好循环依赖的模块化库.框架.编译器都不是一个好 ...
- seaJS循环依赖的解决原理
seajs模块的六个状态. var STATUS = { 'FETCHING': 1, // The module file is fetching now. 模块正在下载中 'FETCHED': ...
随机推荐
- redis内存占用说明
执行info命令后,找到Memory这一栏,就可以看到内存的使用信息了,如下图: # Memory used_memory:13490096 //数据占用了多少内存(字节) used_memory_h ...
- Plugin execution not covered by lifecycle configuration的解决方案
pom配置文件中,提示错误:Plugin execution not covered by lifecycle configuration. 如图: 这表示m2e在其执行maven的生命周期管理时没有 ...
- 编写JQuery插件-1
看到这篇文章的人相信大家都学会了jq,或者正在用jq,在这里简单介绍一下jq的插件封装: jQuery的插件主要分为3种类型: 1.封装对象方法的插件 这种插件是将对象的方法封装起来,用于对通过选择器 ...
- 关于JavaScript中的编码和解码函数
js对文字进行编码涉及3个函数:escape,encodeURI,encodeURIComponent,相应3个解码函数:unescape,decodeURI,decodeURIComponent 1 ...
- mybatis进阶--一对一查询
所谓的一对一查询,就是说我们在查询一个表的数据的时候,需要关联查询其他表的数据. 需求 首先说一个使用一对一查询的小需求吧:假设我们在查询某一个订单的信息的时候,需要关联查询出创建这个订单对应的用户信 ...
- Java静态代理和动态代理总结
静态代理 第一种实现(基于接口): 1>接口 public interface Hello { void say(String msg);} 2>目标类,至少实现一个接口 public c ...
- Android Asynctask的优缺点
导语:之前做习惯了Framework层的开发,今天在武汉斗鱼公司面试APP客户端的开发,其中一道题是讲述Asynctask的优缺点,我靠,我只是知道有这么一个东西,会用而已,看来之前的生活太过于安逸, ...
- [Hadoop] - Mapreduce自定义Counter
在Hadoop的MR程序开发中,经常需要统计一些map/reduce的运行状态信息,这个时候我们可以通过自定义Counter来实现,这个实现的方式是不是通过配置信息完成的,而是通过代码运行时检查完成的 ...
- linux下php开发环境搭建(nginx+php+mysql)
安装前准备工作 先安装一些必要的类库 yum install -y wget zlib-devel bzip2-devel curl-devel openssl openssl-devel vim ...
- jquery序列化form表单
在开发中有时需要在js中提交form表单数据,就需要将form表单进行序列化. jquery提供的serialize方法能够实现. $("#searchForm").seriali ...