利用docker搭建spark hadoop workbench
目的
- 用docker实现所有服务
- 在spark-notebook中编写Scala代码,实时提交到spark集群中运行
- 在HDFS中存储数据文件,spark-notebook中直接读取
组件
- Spark (Standalone模式, 1个master节点 + 可扩展的worker节点)
- Spark-notebook
- Hadoop name node
- Hadoop data node
- HDFS FileBrowser
实现
最初用了Big Data Europe的docker-spark-hadoop-workbench,但是docker 服务运行后在spark-notebook中运行代码会出现经典异常:
java.lang.ClassCastException: cannot assign instance of scala.collection.immutable.List$SerializationProxy to field org.apache.spark.rdd.RDD.org$apache$spark$rdd$RDD$$dependencies_ of type scala.collection.Seq in instance of org.apache.spark.rdd.MapPartitionsRDD
发现是因为spark-notebook和spark集群使用的spark版本不一致. 于是fork了Big Data Europe的repo,在此基础上做了一些修改,基于spark2.11-hadoop2.7实现了一个可用的workbench.
运行docker服务
docker-compose up -d
扩展spark worker节点
docker-compose scale spark-worker=
测试服务
各个服务的URL如下:
Namenode: http://localhost:50070
Datanode: http://localhost:50075
Spark-master: http://localhost:8080
Spark-notebook: http://localhost:9001
Hue (HDFS Filebrowser): http://localhost:8088/home
以下是各个服务的运行截图
HDFS Filebrower

Spark集群

Spark-notebook

运行例子
1. 上传csv文件到HDFS FileBrowser,
2. Spark notebook新建一个notebook
3. 在新建的notebook里操作HDFS的csv文件
具体的步骤参考这里
以下是spark-notebook运行的截图:
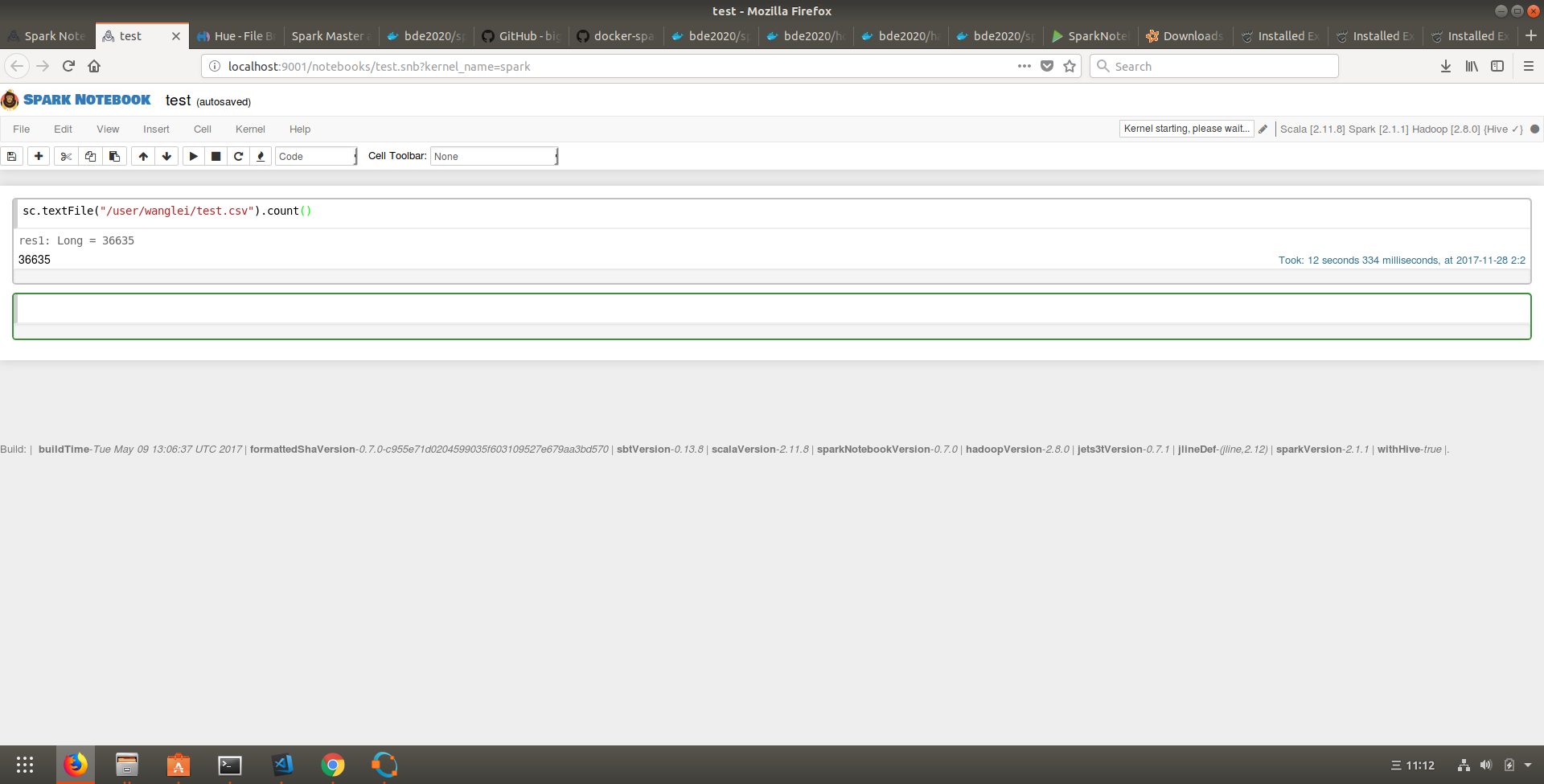
代码链接
利用docker搭建spark hadoop workbench的更多相关文章
- 使用Docker搭建Spark集群(用于实现网站流量实时分析模块)
上一篇使用Docker搭建了Hadoop的完全分布式:使用Docker搭建Hadoop集群(伪分布式与完全分布式),本次记录搭建spark集群,使用两者同时来实现之前一直未完成的项目:网站日志流量分析 ...
- Windows下搭建Spark+Hadoop开发环境
Windows下搭建Spark+Hadoop开发环境需要一些工具支持. 只需要确保您的电脑已装好Java环境,那么就可以开始了. 一. 准备工作 1. 下载Hadoop2.7.1版本(写Spark和H ...
- 利用Docker搭建本地https环境的完整步骤
利用Docker搭建本地https环境的完整步骤 这篇文章主要给大家介绍了关于如何利用Docker搭建本地https环境的完整步骤,文中通过示例代码将实现的步骤介绍的非常详细,对大家的学习或者工作具有 ...
- 利用 Docker 搭建 IPFS 私有网络
利用 Docker 搭建 IPFS 私有网络 本文原始地址:https://sitoi.cn/posts/40630.html 下载项目 项目地址:https://github.com/Sitoi/p ...
- 利用 Docker 搭建单机的 Cloudera CDH 以及使用实践
想用 CDH 大礼包,于是先在 Mac 上和 Centos7.4 上分别搞个了单机的测试用.其实操作的流和使用到的命令差不多就一并说了: 首先前往官方下载包: https://www.cloudera ...
- 利用Docker搭建开发环境
一. 前言 随着平台的不断壮大,项目的研发对于开发人员而言,对于外部各类环境的依赖逐渐增加,特别是针对基础服务的依赖.这些现象导致开 发人员常常是为了简单从而直接使用公有的基础组件进行协同开发,在出现 ...
- ubuntu14.04环境下利用docker搭建solrCloud集群
在Ubuntu14.04操作系统的宿主机中,安装docker17.06.3,将宿主机的操作系统制作成docker基础镜像,之后使用自制的基础镜像在docker中启动3个容器,分配固定IP,再在3个容器 ...
- Docker入门详解——安装docker并利用docker搭建lnmp
首先我们需先安装docker环境,这个比较简单,以centos7为例 docker在centos7上安装需要系统内核版本3.10+,可以通过uname -r查看内核版本号,如果版本不符请自行查阅资料更 ...
- Docker 搭建Spark 依赖singularities/spark:2.2镜像
singularities/spark:2.2版本中 Hadoop版本:2.8.2 Spark版本: 2.2.1 Scala版本:2.11.8 Java版本:1.8.0_151 拉取镜像: [root ...
随机推荐
- Windows 10新功能
Windows 10 中面向开发人员的新增功能 Windows 10 及新增的开发人员工具将提供新通用 Windows 平台支持的工具.功能和体验.在 Windows 10 上安装完工具和 SDK后, ...
- UVa437,The Tower of Babylon
转:http://blog.csdn.net/wangtaoking1/article/details/7308275 题意为输入若干种立方体(每种若干个),然后将立方体堆成一个塔,要求接触的两个面下 ...
- 墨卡托投影坐标系(Mercator Projection)原理及实现C代码
墨卡托投影是一种"等角正切圆柱投影",荷兰地图学家墨卡托(Mercator)在1569年拟定:假设地球被围在一个中空的圆柱里,其赤道与圆柱相接触,然后再假想地球中心有一盏灯,把球面 ...
- codeblocks无法编译的问题
(题外话:网上垃圾资源太多,良心推荐下载 codeblocks的码农们,别TM用DevC++,百度搜索100个不用devc++的理由加上我自己亲身经历!!!) https://jingyan.baid ...
- CentOS6.9中挂载NTFS移动硬盘
公司需要本地备份,不占用公网带宽,而本地服务器硬盘容量不够,所以需要将本地服务器centos 6.9系统的备份数据拷贝到移动硬盘. 所以需要在centos上挂载NTFS格式的移动硬盘. 方法/步骤: ...
- css英文字符或者数字不换行的问题
table-layout:fixed; word-break: break-all; overflow:hidden;
- 八皇后问题 dfs/递归
#include <bits/stdc++.h> using namespace std; const int maxn = 55; int ans=0; int vis_Q[maxn]; ...
- 从ELK到EFK演进
背景 作为中国最大的在线教育站点,目前沪江日志服务的用户包含网校,交易,金融,CCTalk 等多个部门的多个产品的日志搜索分析业务,每日产生的各类日志有好十几种,每天处理约10亿条(1TB)日志,热数 ...
- 使用 Go-Ethereum 1.7.2搭建以太坊私有链
目录 [toc] 1.什么是Ethereum(以太坊) 以太坊(Ethereum)并不是一个机构,而是一款能够在区块链上实现智能合约.开源的底层系统,以太坊从诞生到2017年5月,短短3年半时间,全球 ...
- 三星R428 内存不兼容金士顿2G DDR3
京东上买了个金士顿2G DDR3, 回家装上之后发现不兼容, 原机带的是三星DDR3 1066的2G条子,买的是 金士顿DDR3 2G 1333的条子,结果单独插任何一根都好使,两个插槽均无问题,但是 ...