【已解决】BeautifulSoup已经获得了Unicode的Soup但是print出来却是乱码
【问题】
某人遇到的问题:
关于BeautifulSoup抓取表格及SAE数据库导入的问题(跪求大神帮忙)
简单说就是:
用如下代码:
|
1
2
3
4
5
6
7
|
import re,urllib2from BeautifulSoup import BeautifulSoupfrom urllib import urlopensoup = BeautifulSoup(doc,fromEncoding="GB2312")这里怎么改也没用a=soup.findAll("td")print a |
但是得到的打印输出还是显示的是乱码:
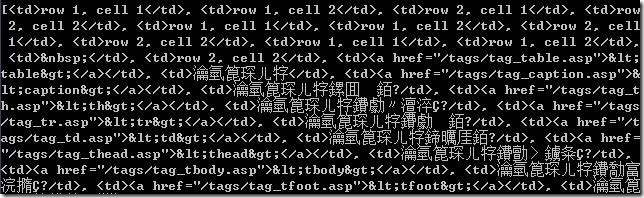
【解决过程】
1. 此处专门通过实际测试,然后再去查证资料,最终,完整的代码和解释,如下:
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
|
#!/usr/bin/python# -*- coding: utf-8 -*-"""Function:【已解决】BeautifulSoup已经获得了Unicode的Soup但是print出来却是乱码Author: Crifan LiVersion: 2013-05-30Contact: http://www.crifan.com/contact_me/""" import re,urllib2from BeautifulSoup import BeautifulSoupfrom urllib import urlopen def scrapeW3school(): #soup = BeautifulSoup(html); #此句效果是一样的: #实测结果是:不加fromEncoding,也是可以自动正确(去判断原始的字符编码为GB2312,然后去)解析(出后来的Unicode的soup)的 soup = BeautifulSoup(html, fromEncoding="GB2312"); #print "soup=",soup; allTdSoup = soup.findAll("td"); print "type(allTdSoup)=",type(allTdSoup); #type(allTdSoup)= <class 'BeautifulSoup.ResultSet'>,但是实际上算是个List print "len(allTdSoup)=",len(allTdSoup); #len(allTdSoup)= 32,此处List的长度是32 print "allTdSoup=",allTdSoup; # allTdSoup= [<td>row 1, cell 1</td>, <td>row 1, cell 2</td>, <td>row 2, ......, <td><a href="/tags/tag_tfoot.asp"><tfoot></a></td> # , <td>瀹氫箟琛ㄦ牸鐨勯〉鑴氥€?/td>, <td><a href="/tags/tag_col.asp"><col></a></td>, <td>瀹氫箟鐢ㄤ簬琛ㄦ牸鍒楃殑灞 # 炴€с€?/td>, <td><a href="/tags/tag_colgroup.asp"><colgroup></a></td>, <td>瀹氫箟琛ㄦ牸鍒楃殑缁勩€?/td>] #此处,看起来是乱码,但是实际上,此处得到的allTdSoup是个列表,而其中的每个soup,虽然内部编码都是正常的unicode了 #但还是会打印出来乱码,那是因为: #1.先看官网的解释: #"当你调用__str__,prettify或者renderContents时, 你可以指定输出的编码。默认的编码(str使用的)是UTF-8。" #所以: #此处,对于去打印allTdSoup,即去打印一个soup的List,所以,针对List中的每个soup(其本质是个对象),而将其输出为字符串的话,默认是调用其__str__属性 #所以就相当于: #针对allTdSoup中的每个soup: # 调用该soup的__str__获得对应的字符串(表示的该soup的内容) #最终组合输出你所看到的["xxx", "xxx", ...]之类的结果, #其中,"xxx",就是对应的每个soup.__str__的结果 #而此处的每个soup的__str__的值: #如官网所述,默认是UTF-8的编码 #所以,此处获得的字符串是UTF-8编码的字符串, #所以print输出到此处cmd #而cmd是GBK编码 #所以,将UTF-8编码的字符,在GBK的cmd中显示,就显示出乱码了 #其中: #(1)如果对于cmd是GBK不了解,去看: #设置字符编码:简体中文GBK/英文 #http://www.crifan.com/files/doc/docbook/soft_dev_basic/release/html/soft_dev_basic.html#cmd_encoding #(2)如果对于GBK,UTF-8本身不了解,去看: #字符编码详解 #(3)针对于soup本身,其实已经是Unicode编码,所以可以通过官网所说的,指定__str__输出时的编码为GBK,以使得此处正确显示非乱码的中文 for eachTdSoup in allTdSoup: print "type(eachTdSoup)=",type(eachTdSoup); #type(eachTdSoup)= <type 'instance'>,说明类型是BeautifulSoup的实例instance print "eachTdSoup.string=",eachTdSoup.string; #输出soup的string属性,即该tag中的字符串内容部分,其本身已经是Unicode,所以可以正常输出非乱码的中文 print "type(eachTdSoup.string)=",type(eachTdSoup.string); #但是要注意一下,此处不是Unicode类型,而是:type(eachTdSoup.string)= <class 'BeautifulSoup.NavigableString'> print "eachTdSoup=",eachTdSoup; #直接输出soup本身,所以相当于:eachTdSoup.__str__ == eachTdSoup.__str__("UTF-8"),所以遇到中文时是乱码 print "eachTdSoup.renderContents()=",eachTdSoup.renderContents(); #直接输出内容本身,默认也是用的是UTF-8,所以遇到中文时也是乱码 print "eachTdSoup.__str__('GBK')=",eachTdSoup.__str__('GBK');#专门指定了GBK编码,所以可以正常显示非乱码的中文 #摘录其中部分输出: # type(eachTdSoup)= <type 'instance'> # eachTdSoup.string= row 1, cell 1 # type(eachTdSoup.string)= <class 'BeautifulSoup.NavigableString'> # eachTdSoup= <td>row 1, cell 1</td> # eachTdSoup.renderContents()= row 1, cell 1 # eachTdSoup.__str__('GBK')= <td>row 1, cell 1</td> # ...... # type(eachTdSoup)= <type 'instance'> # eachTdSoup.string= 定义表格列的组。 # type(eachTdSoup.string)= <class 'BeautifulSoup.NavigableString'> # eachTdSoup= <td>瀹氫箟琛ㄦ牸鍒楃殑缁勩€?/td> # eachTdSoup.renderContents()= 瀹氫箟琛ㄦ牸鍒楃殑缁勩€ # eachTdSoup.__str__('GBK')= <td>定义表格列的组。</td> # #(4)另外,关于BeautifulSoup可以根据html中的charset猜测其编码的事情,不了解的去看: #【整理】关于HTML网页源码的字符编码(charset)格式(GB2312,GBK,UTF-8,ISO8859-1等)的解释 if __name__ == "__main__": scrapeW3school(); |
【总结】
所以说:
表面上看起来从BeautifulSoup解析后得到的soup,打印出来是乱码,但是实际上其本身已经是,正确的(从原始的GB2312编码)解析(为Unicode)后的了。
之所以乱码,那是因为,打印soup时,调用的是__str__,其默认是UTF-8,所以输出到GBK的cmd中,才显示是乱码。
总结下来就是:
非得搞懂了:
各种编码本身的逻辑:啥是GBK,啥是UTF-8,啥是Unicode
BeautifulSoup的逻辑:可以通过fromEncoding去正确的解析html为Unicode编码的
print一个对象的逻辑:内部是调用对象的__str__得到对应的字符串的,此处对应的是soup的__str__
soup的__str__的逻辑:默认编码是UTF-8
cmd的逻辑:(中文的系统中)编码为GBK
然后才能明白此处的问题的根本的原因的。
【已解决】BeautifulSoup已经获得了Unicode的Soup但是print出来却是乱码的更多相关文章
- 【已解决】python中文字符乱码(GB2312,GBK,GB18030相关的问题)
http://againinput4.blog.163.com/blog/static/1727994912011111011432810/ [已解决]python中文字符乱码(GB2312,GB ...
- Microsoft.Office.Interop.Excel, Version=12.0.0.0版本高于引用的程序集(已解决)
Microsoft.Office.Interop.Excel, Version=12.0.0.0版本高于引用的程序集(已解决) 论坛里的帮助:http://bbs.csdn.net/topics/39 ...
- 解决 git 中文路径显示 unicode 代码的问题
解决 git 中文路径显示 unicode 代码的问题 当被修改的文件中带有中文字符时,中文字符会被转换为 unicode 代码,看不出原来的文件名. 这时,只要配置 :: git config -- ...
- 使用Notepad++编码编译时报错(已解决?)
使用Notepad++编码编译时报错(已解决?) 使用Notepad++编码,编译的时候经常会报错,说什么GBK编码啥啥啥~~~但同样的编码用ECLIPSE就没有问题.再有,用记事本把他保存成ANSI ...
- 已解决】Sublime中运行带input或raw_input的Python代码出错:EOFError: EOF when reading a line(转)
[问题] 在折腾: [已解决]Sublime Text 2中运行Python程序出错:The system cannot find the file specified 的过程中,虽然解决了找不到py ...
- 【已解决】Android ADT中增大AVD内存后无法启动:emulator failed to allocate memory 8
[问题] 折腾: [已解决]Android ADT中增大AVD内存后无法启动:emulator failed to allocate memory 8 过程中,增大对应AVD的内存为2G后,结果无法启 ...
- Access中出现改变字段“自己主动编号”类型,不能再改回来!(已解决)
Access中出现改变字段"自己主动编号"类型,不能再改回来! (已解决) 一次把access中的自增字段改成了数值,再改回自增时,提示:在表中输入了数据之后,则不能将不论什么字段 ...
- sqlserver,执行生成脚本时“引发类型为“System.OutOfMemoryException”的异常”(已解决)
sqlserver,执行生成脚本时“引发类型为“System.OutOfMemoryException”的异常”(已解决) 出现此错误主要是因为.sql的脚本文件过大(一般都超过100M)造成内存无法 ...
- LOL是什么意思? - 已解决 - 搜狗问问
LOL是什么意思? - 已解决 - 搜狗问问 N A T S U . |分类:QQ工具栏 2009-05-04 LOL是什么意思? 满意答案 Shim Nyong 19级 2009-05-04 LOL ...
随机推荐
- WS103C8例程——串口2【worldsing笔记】
在超MINI核心板 stm32F103C8最小系统板上调试Usart2功能:用Jlink 6Pin接口连接WStm32f103c8的Uart2,PC机向mcu发送数据,mcu收到数据后数据加1,回传给 ...
- 关于cocoapods添加静态库的奇葩配置
不多说,直接上代码 当引入这个静态库时,一开始死活在编辑时找不到这个静态库. 直到看到这个贴子:http://stackoverflow.com/questions/19189463/cocoapod ...
- Arduino Due, Maple and Teensy3.0 的 W5200性能测试
开源平台中以太网连接方案里W5100是众所周知的,W5200正在此领域越来越受欢迎.这个测试结果是在Arduino Due(Atmel CortexM3-84Mhz), Maple(ST Cortex ...
- 编译小结(6)认识Automake
我前面说了很多如何用gcc或 Makefile怎么编译的东东,但在Linux下装过软件的都应当见过,很多源码安装的包是用Automake 来编译的.输入下"./configur ...
- Javascript 原型继承(续)—从函数到构造器的角色转换
对于每一个声明的函数,里边都会带有一个prototype成员,prototype会指向一个对象,现在我们来聚焦prototype指向的这个对象,首先我们会认为,这个对象是一个该函数对应的一个实例对象, ...
- 基于linux 的2048
在 debian 下写了一个 2048, 效果如下: 感兴趣的朋友可以在这里(http://download.csdn.net/download/kamsau/7330933)下载. 版权声明:本文为 ...
- Android Layout_Gravity和Gravity
简单来说layout_gravity表示子控件在父容器的位置,gravity表示控件内容在控件内的位置. 上面图片的xml代码 <?xml version="1.0" enc ...
- [置顶] 《Windows编程零基础》__2 一个完整的程序
Windows开发的常识 1)窗口 Windows中最基本的概念也许就是窗口了,每一个前台程序都至少有一个窗口,一个窗口也是你可以看到的部分,比如,QQ有如下的登录窗口 基本上你在Windows中可见 ...
- Codeforces Round #114 (Div. 1) B. Wizards and Huge Prize 概率dp
B. Wizards and Huge Prize Time Limit: 20 Sec Memory Limit: 256 MB 题目连接 http://codeforces.com/contest ...
- C++技术问题总结-第12篇 设计模式原则
设计模式六大原则,參见http://www.uml.org.cn/sjms/201211023.asp. 1. 单一职责原则 定义:不要存在多于一个导致类变更的原因.通俗的说,即一个类仅仅负责一项职责 ...