HanLP — 感知机(Perceptron) -- Python
感知机
感知机是根据输入实例的特征向量 x 对其进行二类分类的线性模型:
\]
感知机模型对应于输入空间(特征空间)中的分离超平面 $ w\cdot x+b=0 $.其中w是超平面的法向量,b是超平面的截距。
可见感知机是一种线性分类模型,属于判别模型。
感知机学习的假设
感知机学习的重要前提假设是训练数据集是线性可分的。
感知机学习策略
感知机学的策略是极小化损失函数。
损失函数的一个自然选择是误分类点的总数。但是,这样的损失函数不是参数 w, b的连续可导的函数,不易于优化。所以通常是选择误分类点到超平面 S 的总距离:
\]
学习的策略就是求得使 L(w,b) 为最小值的 w 和 b。其中 M 是误分类点的集合。
感知机学习的算法
感知机学习算法是基于随机梯度下降法的对损失函数的最优化算法,有原始形式和对偶形式,算法简单易于实现。
原始形式
\]
首先,任意选取一个超平面$ w_0, b_0 $,然后用梯度下降法不断地极小化目标函数。极小化的过程中不是一次使 M 中所有误分类点得梯度下降,而是一次随机选取一个误分类点,使其梯度下降。
\]
\]
随机选取一个误分类点$ (x_i,y_i) $,对 w,b 进行更新:
\]
\]
其中$ \eta(0<\eta\leq1) $是学习率。
对偶形式
对偶形式的基本想法是,将 w 和 b 表示为是咧 $ x_i $ 和标记 $ y_i $的线性组合的形式,通过求解其系数而得到 w 和 b。
\]
\]
逐步修改 w,b,设修改 n 次,则 w,b 关于$ (x_i,y_i) $ 的增量分别是 $ \alpha_iy_ix_i $ 和 $ \alpha_iy_i $, 这里 $ \alpha_i=n_i\eta $。最后学习到的 w,b 可以分别表示为:
\]
\]
这里, $ \alpha_i\geq0, i=1,2,...,N $,当 $ \eta=1 $时,表示第i个是实例点由于误分类而进行更新的次数,实例点更新次数越多,说明它距离分离超平面越近,也就越难区分,该点对学习结果的影响最大。
感知机模型对偶形式: $$f(x)=sign(\sum_{j=1}^{N}\alpha_jy_jx_j\cdot x+b) $$ 其中$$\alpha=(\alpha_1,\alpha_2,...,\alpha_N)^T$$
学习时初始化 $ \alpha \leftarrow 0, b \leftarrow 0 $, 在训练集中找分类错误的点,即:
\]
然后更新:
\]
\]
知道训练集中所有点正确分类
对偶形式中训练实例仅以内积的形式出现,为了方便,可以预先将训练集中实例间的内积计算出来以矩阵的形式存储,即 Gram 矩阵。
总结
- 当训练数据集线性可分的时候,感知机学习算法是收敛的,感知机算法在训练数据集上的误分类次数 k 满足不等式:
\]
具体证明可见 李航《统计学习方法》或 林轩田《机器学习基石》。
当训练当训练数据集线性可分的时候,感知机学习算法存在无穷多个解,其解由于不同的初值或不同的迭代顺序而可能不同,即存在多个分离超平面能把数据集分开。
感知机学习算法简单易求解,但一般的感知机算法不能解决异或等线性不可分的问题。
导入相关包并创建数据集
为了快速方便的创建数据集,此处采用 scikit-learn 里的 make_blobs
import numpy as np
from sklearn.datasets import make_blobs
import matplotlib.pyplot as plt
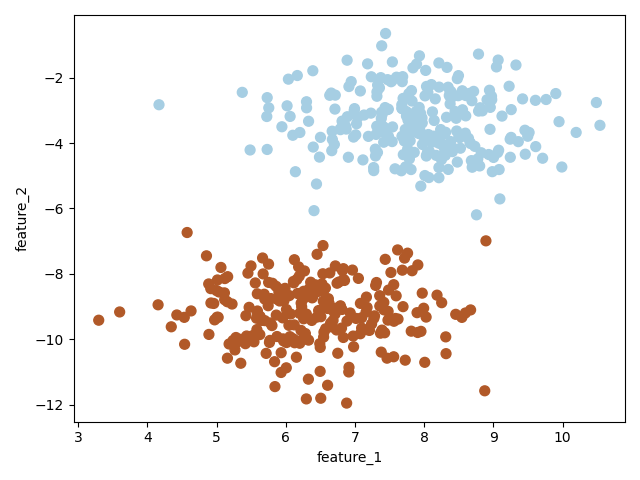
# 创建一个数据集,X有两个特征,y={-1,1}
X, y = make_blobs(n_samples=500, centers=2, random_state=6)
y[y==0] = -1
plt.scatter(X[:, 0], X[:, 1], c=y, s=30, cmap=plt.cm.Paired)
plt.xlabel("feature_1")
plt.ylabel("feature_2")
plt.show()
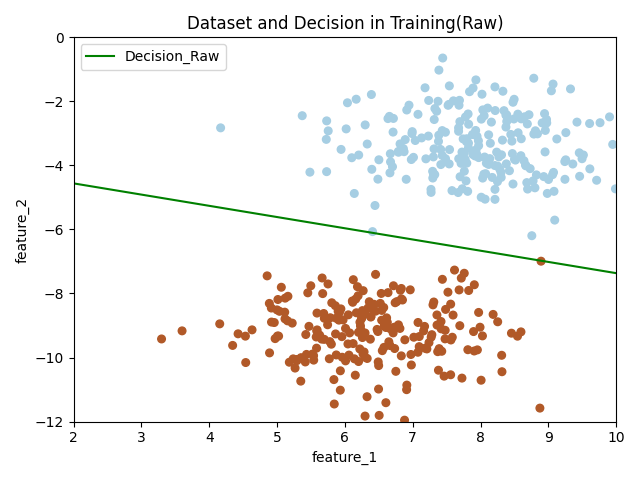
感知机(采用原始形式)
创建感知机模型的原始形式的类,并在训练集上训练,测试集上简单测试。
import numpy as np
from sklearn.datasets import make_blobs # 为了快速方便的创建数据集,此处采用 scikit-learn 里的 make_blobs
import matplotlib.pyplot as plt
# 创建一个数据集,X有两个特征,y={-1,1}
X, y = make_blobs(n_samples=500, centers=2, random_state=6)
y[y == 0] = -1
# plt.scatter(X[:, 0], X[:, 1], c=y, s=50, cmap=plt.cm.Paired)
# plt.xlabel("feature_1")
# plt.ylabel("feature_2")
# plt.show()
class PerceptronRaw():
def __init__(self):
self.W = None;
self.bias = None;
def fit(self, x_train, y_train, learning_rate=0.05, n_iters=100, plot_train=True):
print("开始训练...")
num_samples, num_features = x_train.shape
self.W = np.random.randn(num_features)
self.bias = 0
while True:
erros_examples = []
erros_examples_y = []
# 查找错误分类的样本点
for idx in range(num_samples):
example = x_train[idx]
y_idx = y_train[idx]
# 计算距离
distance = y_idx * (np.dot(example, self.W) + self.bias)
if distance <= 0:
erros_examples.append(example)
erros_examples_y.append(y_idx)
if len(erros_examples) == 0:
break;
else:
print("修正参数 w => %s b => %s" % (self.W, self.bias))
# 随机选择一个错误分类点,修正参数
random_idx = np.random.randint(0, len(erros_examples))
choosed_example = erros_examples[random_idx]
choosed_example_y = erros_examples_y[random_idx]
self.W = self.W + learning_rate * choosed_example_y * choosed_example
self.bias = self.bias + learning_rate * choosed_example_y
print("训练结束")
# 绘制训练结果部分
if plot_train is True:
x_hyperplane = np.linspace(2, 10, 8)
slope = -self.W[0] / self.W[1]
intercept = -self.bias / self.W[1]
y_hpyerplane = slope * x_hyperplane + intercept
plt.xlabel("feature_1")
plt.ylabel("feature_2")
plt.xlim((2, 10))
plt.ylim((-12, 0))
plt.title("Dataset and Decision in Training(Raw)")
plt.scatter(x_train[:, 0], x_train[:, 1], c=y_train, s=30, cmap=plt.cm.Paired)
plt.plot(x_hyperplane, y_hpyerplane, color='g', label='Decision_Raw')
plt.legend(loc='upper left')
plt.show()
def predict(self, x):
if self.W is None or self.bias is None:
raise NameError("模型未训练")
y_predict = np.sign(np.dot(x, self.W) + self.bias)
return y_predict
X_train = X[0:450]
y_train = y[0:450]
X_test = X[450:500]
y_test = y[450:500]
# 实例化模型,并训练
model_raw = PerceptronRaw()
model_raw.fit(X_train, y_train)
# 测试,因为测试集和训练集来自同一分布的线性可分数据集,所以这里测试准确率达到了 1.0
y_predict = model_raw.predict(X_test)
accuracy = np.sum(y_predict == y_test) / y_predict.shape[0]
print("原始形式模型在测试集上的准确率: {0}".format(accuracy))
# 原始形式模型在测试集上的准确率: 1.0
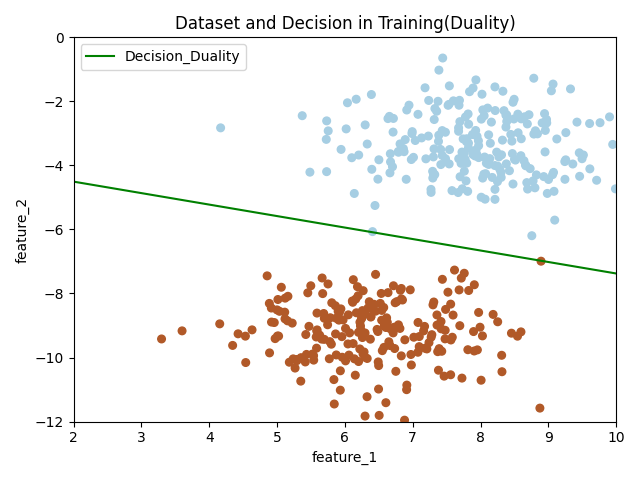
感知机(采用对偶形式)
创建感知机模型的对偶形式的类,并在训练集上训练,测试集上简单测试。
import numpy as np
from sklearn.datasets import make_blobs # 为了快速方便的创建数据集,此处采用 scikit-learn 里的 make_blobs
import matplotlib.pyplot as plt
# 创建一个数据集,X有两个特征,y={-1,1}
X, y = make_blobs(n_samples=500, centers=2, random_state=6)
y[y == 0] = -1
# plt.scatter(X[:, 0], X[:, 1], c=y, s=50, cmap=plt.cm.Paired)
# plt.xlabel("feature_1")
# plt.ylabel("feature_2")
# plt.show()
class PerceptronDuality():
def __init__(self):
self.alpha = None
self.bias = None
self.W = None
def fit(self, x_train, y_train, learning_rate=1, n_iters=100, plot_train=True):
print("开始训练...")
num_samples, num_features = x_train.shape
self.alpha = np.zeros((num_samples,))
self.bias = 0
# 计算 Gram 矩阵
gram = np.dot(x_train, x_train.T)
while True:
error_count = 0
for idx in range(num_samples):
inner_product = gram[idx]
y_idx = y_train[idx]
distance = y_idx * (np.sum(self.alpha * y_train * inner_product) + self.bias)
# 如果有分类错误点,修正 alpha 和 bias,跳出本层循环,重新遍历数据计算,开始新的循环
if distance <= 0:
error_count += 1
self.alpha[idx] = self.alpha[idx] + learning_rate
self.bias = self.bias + learning_rate * y_idx
break
# 数据没有错分类点,跳出 while 循环
if error_count == 0:
break
self.W = np.sum(self.alpha * y_train * x_train.T, axis=1)
print("训练结束")
# 绘制训练结果部分
if plot_train is True:
x_hyperplane = np.linspace(2, 10, 8)
slope = -self.W[0]/self.W[1]
intercept = -self.bias/self.W[1]
y_hpyerplane = slope * x_hyperplane + intercept
plt.xlabel("feature_1")
plt.ylabel("feature_2")
plt.xlim((2, 10))
plt.ylim((-12, 0))
plt.title("Dataset and Decision in Training(Duality)")
plt.scatter(x_train[:, 0], x_train[:, 1], c=y_train, s=30, cmap=plt.cm.Paired)
plt.plot(x_hyperplane, y_hpyerplane, color='g', label='Decision_Duality')
plt.legend(loc='upper left')
plt.show()
def predict(self, x):
if self.alpha is None or self.bias is None:
raise NameError("模型未训练")
y_predicted = np.sign(np.dot(x, self.W) + self.bias)
return y_predicted
X_train = X[0:450]
y_train = y[0:450]
X_test = X[450:500]
y_test = y[450:500]
# 训练
model_duality = PerceptronDuality()
model_duality.fit(X_train, y_train)
# 测试
y_predict_duality = model_duality.predict(X_test)
accuracy_duality = np.sum(y_predict_duality == y_test) / y_test.shape[0]
print("对偶形式模型在测试集上的准确率: {0}".format(accuracy_duality))
#对偶形式模型在测试集上的准确率: 1.0
比较两个模型
分别从原始模型和对偶模型中获取参数,可以看出,这两个模型的分离超平面都不同,但是都能正确进行分类,这验证了总结中的结论。
当训练当训练数据集线性可分的时候,感知机学习算法存在无穷多个解,其解由于不同的初值或不同的迭代顺序而可能不同,即存在多个分离超平面能把数据集分开。
print("原始形式模型参数:")
print("W: {0}, bias: {1}".format(model_raw.W, model_raw.bias))
print()
print("对偶形式模型参数:")
print("W: {0}, bias: {1}".format(model_duality.W, model_duality.bias))
原始形式模型参数:
W: [-1.07796999 -3.05384787], bias: -11.700000000000031
对偶形式模型参数:
W: [-25.35285228 -70.71533848], bias: -268
源码: https://gitee.com/VipSoft/VipPython/tree/master/perceptron
HanLP — 感知机(Perceptron) -- Python的更多相关文章
- 神经网络 感知机 Perceptron python实现
import numpy as np import matplotlib.pyplot as plt import math def create_data(w1=3,w2=-7,b=4,seed=1 ...
- 2. 感知机(Perceptron)基本形式和对偶形式实现
1. 感知机原理(Perceptron) 2. 感知机(Perceptron)基本形式和对偶形式实现 3. 支持向量机(SVM)拉格朗日对偶性(KKT) 4. 支持向量机(SVM)原理 5. 支持向量 ...
- 感知机(python实现)
感知机(perceptron)是二分类的线性分类模型,输入为实例的特征向量,输出为实例的类别(取+1和-1).感知机对应于输入空间中将实例划分为两类的分离超平面.感知机旨在求出该超平面,为求得超平面导 ...
- 感知机(perceptron)概念与实现
感知机(perceptron) 模型: 简答的说由输入空间(特征空间)到输出空间的如下函数: \[f(x)=sign(w\cdot x+b)\] 称为感知机,其中,\(w\)和\(b\)表示的是感知机 ...
- 20151227感知机(perceptron)
1 感知机 1.1 感知机定义 感知机是一个二分类的线性分类模型,其生成一个分离超平面将实例的特征向量,输出为+1,-1.导入基于误分类的损失函数,利用梯度下降法对损失函数极小化,从而求得此超平面,该 ...
- HanLP https://pypi.python.org/pypi/sumy/
HanLP - 汉语言处理包 http://hanlp.linrunsoft.com/doc.html https://pypi.python.org/pypi/sumy/
- 感知机(perceptron)
- pyhanlp:hanlp的python接口
HanLP的Python接口,支持自动下载与升级HanLP,兼容py2.py3. 安装 pip install pyhanlp 使用命令hanlp来验证安装,如因网络等原因自动安装失败,可参考手动配置 ...
- 利用Python实现一个感知机学习算法
本文主要参考英文教材Python Machine Learning第二章.pdf文档下载链接: https://pan.baidu.com/s/1nuS07Qp 密码: gcb9. 本文主要内容包括利 ...
- 分词工具Hanlp基于感知机的中文分词框架
结构化感知机标注框架是一套利用感知机做序列标注任务,并且应用到中文分词.词性标注与命名实体识别这三个问题的完整在线学习框架,该框架利用1个算法解决3个问题,时自治同意的系统,同时三个任务顺序渐进,构 ...
随机推荐
- 全文手敲代码,教你用Java实现扫雷小游戏
摘要:本程序共封装了五个类,分别是主类GameWin类,绘制底层地图和绘制顶层地图的类MapBottom类和MapTop类,绘制底层数字的类BottomNum类,以及初始化地雷的BottomRay类和 ...
- DBA:这有一份对接NBU备份故障排除指南,请查收!
摘要:当前DWS支持NBU介质备份恢复,本文介绍DWS对接NBU备份故障排除方法. 本文分享自华为云社区<DWS对接NBU备份故障排除指南>,作者: 唐伯虎点蚊香. NetBackup是V ...
- 华为云PB级数据库GaussDB(for Redis)揭秘第13期:如何搞定推荐系统存储难题
摘要:GaussDB(for Redis)轻松搞定推荐系统核心存储,为企业级应用保驾护航. 本文分享自华为云社区<GaussDB(for Redis)揭秘第13期:如何搞定推荐系统存储难题?&g ...
- STM32CubeMX教程16 DAC - 输出3.3V内任意电压
1.准备材料 开发板(正点原子stm32f407探索者开发板V2.4) STM32CubeMX软件(Version 6.10.0) keil µVision5 IDE(MDK-Arm) ST-LINK ...
- 微信公众号短链实时阅读量、点赞数爬虫(不会Hook可用)
众所周知,微信分享的公众号分享出的一般都是短链,在这个锻炼下使用浏览器打开并不能获取微信公众的阅读量点赞数等这些信息,如图1所示. 但是实际拥有详细信息的则是这个链接下面,提取链接所需要提交的信息包括 ...
- 三、redis集群搭建
系列导航 一.redis单例安装(linux) 二.redis主从环境搭建 三.redis集群搭建 四.redis增加密码验证 五.java操作redis 环境:centos7需要的安装包: redi ...
- vue tabBar导航栏设计实现1-初步设计
系列导航 一.vue tabBar导航栏设计实现1-初步设计 二.vue tabBar导航栏设计实现2-抽取tab-bar 三.vue tabBar导航栏设计实现3-进一步抽取tab-item 四.v ...
- eyebeam高级设置
概述 VOIP测试过程中,经常会用到各种各样的SIP终端,eyebeam是其中最常见的一种. 在eyebeam的配置option中,只有少量的配置选项,有些特殊的设置无法配置. 比如DTMF码的发码形 ...
- C#通过泛型实现对子窗体的不同操作
private void button1_Click(object sender, EventArgs e) { FormOperate<object>();//调用FormOperate ...
- python之HtmlTestRunner(三)中文字体乱码的情况
使用HtmlTestRunner测试报告时,遇到中文字体无法识别的情况: 解决方案修改 \Lib\site-packages\HtmlTestRunner\result.py:def generat ...