RocketMQ 端云一体化设计与实践
简介:本文首先介绍了端云消息场景一体化的背景,然后重点分析了终端消息场景特点,以及终端消息场景支撑模型,最后对架构和存储内核进行了阐述。我们期望基于 RocketMQ 统一内核一体化支持终端和服务端不同场景的消息接入目标,以能够给使用者带来一体化的价值,如降低存储成本,避免数据在不同系统间同步带来的一致性挑战。
作者 | 悟幻
一体化背景
不止于分发
我们都知道以 RocketMQ 为代表的消息(队列)起源于不同应用服务之间的异步解耦通信,与以 Dubbo 为代表的 RPC 类服务通信一同承载了分布式系统(服务)之间的通信场景,所以服务间的消息分发是消息的基础诉求。然而我们看到,在消息(队列)这个领域,近些年我们业界有个很重要的趋势,就是基于消息这份数据可以扩展到流批计算、事件驱动等不同场景,如 RocketMQ-streams,Kafka-Streams、Rabbit-Streams 等等。
不止于服务端
传统的消息队列 MQ 主要应用于服务(端)之间的消息通信,比如电商领域的交易消息、支付消息、物流消息等等。然而在消息这个大类下,还有一个非常重要且常见的消息领域,即终端消息。消息的本质就是发送和接受,终端和服务端并没有本质上的大区别。
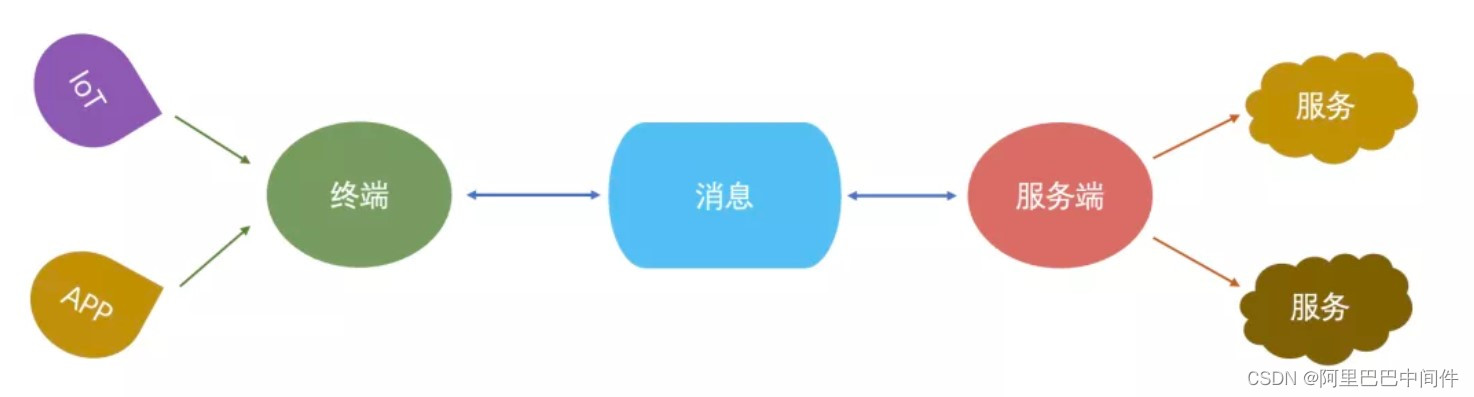
一体化价值
如果可以有一个统一的消息系统(产品)来提供多场景计算(如 stream、event)、多场景(IoT、APP)接入,其实是非常有价值的,因为消息也是一种重要数据,数据如果只存在一个系统内,可以最大地降低存储成本,同时可以有效地避免数据因在不同系统间同步带来的一致性难题。
终端消息分析
本文将主要描述的是终端消息和服务端消息一体化设计与实践问题,所以首先我们对面向终端的这一大类消息做一下基本分析。
场景介绍
近些年,我们看到随着智能家居、工业互联而兴起的面向 IoT 设备类的消息正在呈爆炸式增长,而已经发展十余年的移动互联网的手机 APP 端消息仍然是数量级庞大。面向终端设备的消息数量级比传统服务端的消息要大很多量级,并仍然在快速增长。
特性分析
尽管无论是终端消息还是服务端消息,其本质都是消息的发送和接受,但是终端场景还是有和服务端不太一样的特点,下面简要分析一下:

- 轻量
服务端一般都是使用很重的客户端 SDK 封装了很多功能和特性,然而终端因为运行环境受限且庞杂必须使用轻量简洁的客户端 SDK。
- 标准协议
服务端正是因为有了重量级客户端 SDK,其封装了包括协议通信在内的全部功能,甚至可以弱化协议的存在,使用者无须感知,而终端场景因为要支持各类庞杂的设备和场景接入,必须要有个标准协议定义。
- P2P
服务端消息如果一台服务器处理失败可以由另外一台服务器处理成功即可,而终端消息必须明确发给具体终端,若该终端处理失败则必须一直重试发送该终端直到成功,这个和服务端很不一样。
- 广播比
服务端消息比如交易系统发送了一条订单消息,可能有如营销、库存、物流等几个系统感兴趣,而终端场景比如群聊、直播可能成千上万的终端设备或用户需要收到。
- 海量接入
终端场景接入的是终端设备,而服务端接入的就是服务器,前者在量级上肯定远大于后者。
架构与模型
消息基础分析
实现一体化前我们先从理论上分析一下问题和可行性。我们知道,无论是终端消息还是服务端消息,其实就是一种通信方式,从通信的层面看要解决的基础问题简单总结就是:协议、匹配、触达。
- 协议
协议就是定义了一个沟通语言频道,通信双方能够听懂内容语义。在终端场景,目前业界广泛使用的是 MQTT 协议,起源于物联网 IoT 场景,OASIS 联盟定义的标准的开放式协议。 MQTT 协议定义了是一个 Pub/Sub 的通信模型,这个与 RocketMQ 类似的,不过其在订阅方式上比较灵活,可以支持多级 Topic 订阅(如 “/t/t1/t2”),可以支持通配符订阅(如 “/t/t1/+”)
MQTT 协议定义了是一个 Pub/Sub 的通信模型,这个与 RocketMQ 类似的,不过其在订阅方式上比较灵活,可以支持多级 Topic 订阅(如 “/t/t1/t2”),可以支持通配符订阅(如 “/t/t1/+”)
- 匹配
匹配就是发送一条消息后要找到所有的接受者,这个匹配查找过程是不可或缺的。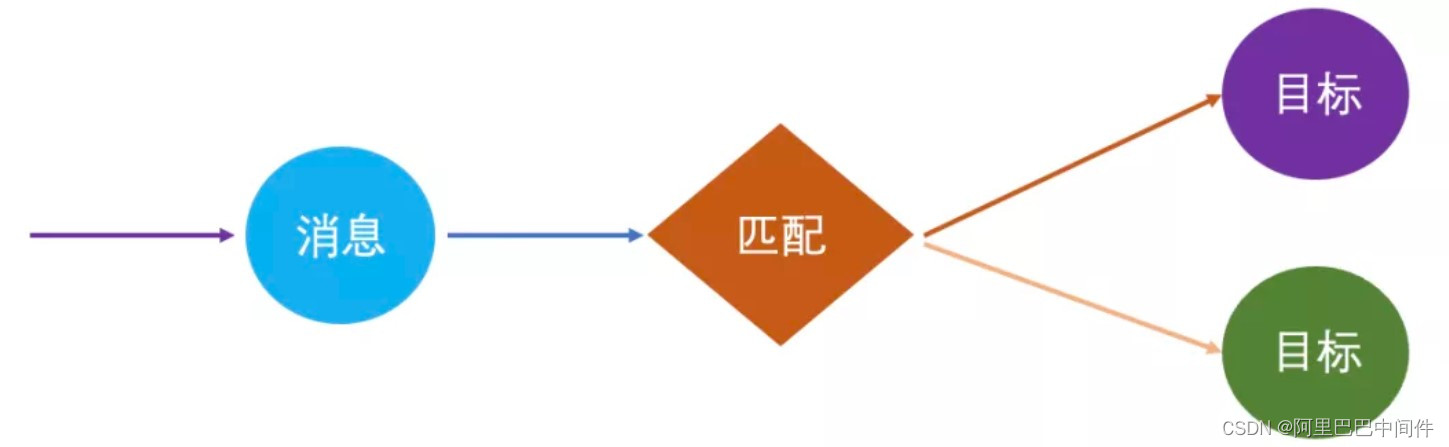 在 RocketMQ 里面实际上有这个类似的匹配过程,其通过将某个 Queue 通过 rebalance 方式分配到消费组内某台机器上,消息通过 Queue 就直接对应上了消费机器,再通过订阅过滤(Tag 或 SQL)进行精准匹配消费者。之所以通过 Queue 就可以匹配消费机器,是因为服务端场景消息并不需要明确指定某台消费机器,一条消息可以放到任意 Queue 里面,并且任意一台消费机器对应这个 Queue 都可以,消息不需要明确匹配消费机器。
在 RocketMQ 里面实际上有这个类似的匹配过程,其通过将某个 Queue 通过 rebalance 方式分配到消费组内某台机器上,消息通过 Queue 就直接对应上了消费机器,再通过订阅过滤(Tag 或 SQL)进行精准匹配消费者。之所以通过 Queue 就可以匹配消费机器,是因为服务端场景消息并不需要明确指定某台消费机器,一条消息可以放到任意 Queue 里面,并且任意一台消费机器对应这个 Queue 都可以,消息不需要明确匹配消费机器。
而在终端场景下,一条消息必须明确指定某个接受者(设备),必须准确找到所有接受者,而且终端设备一般只会连到某个后端服务节点即单连接,和消息产生的节点不是同一个,必须有个较复杂的匹配查找目标的过程,还有如 MQTT 通配符这种更灵活的匹配特性。
- 触达
触达即通过匹配查找后找到所有的接受者目标,需要将消息以某种可靠方式发给接受者。常见的触发方式有两种:Push、Pull。Push,即服务端主动推送消息给终端设备,主动权在服务端侧,终端设备通过 ACK 来反馈消息是否成功收到或处理,服务端需要根据终端是否返回 ACK 来决定是否重投。Pull,即终端设备主动来服务端获取其所有消息,主动权在终端设备侧,一般通过位点 Offset 来依次获取消息,RocketMQ 就是这种消息获取方式。
对比两种方式,我们可以看到 Pull 方式需要终端设备主动管理消息获取逻辑,这个逻辑其实有一定的复杂性(可以参考 RocketMQ 的客户端管理逻辑),而终端设备运行环境和条件都很庞杂,不太适应较复杂的 Pull 逻辑实现,比较适合被动的 Push 方式。
另外,终端消息有一个很重要的区别是可靠性保证的 ACK 必须是具体到一个终端设备的,而服务端消息的可靠性在于只要有一台消费者机器成功处理即可,不太关心是哪台消费者机器,消息的可靠性 ACK 标识可以集中在消费组维度,而终端消息的可靠性 ACK 标识需要具体离散到终端设备维度。简单地说,一个是客户端设备维度的 Retry 队列,一个是消费组维度的 Retry 队列。
模型与组件
基于前面的消息基础一般性分析,我们来设计消息模型,主要是要解决好匹配查找和可靠触达两个核心问题。
- 队列模型
消息能够可靠性触达的前提是要可靠存储,消息存储的目的是为了让接受者能获取到消息,接受者一般有两种消息检索维度:
1)根据订阅的主题 Topic 去查找消息;
2)根据订阅者 ID 去查找消息。这个就是业界常说的放大模型:读放大、写放大。
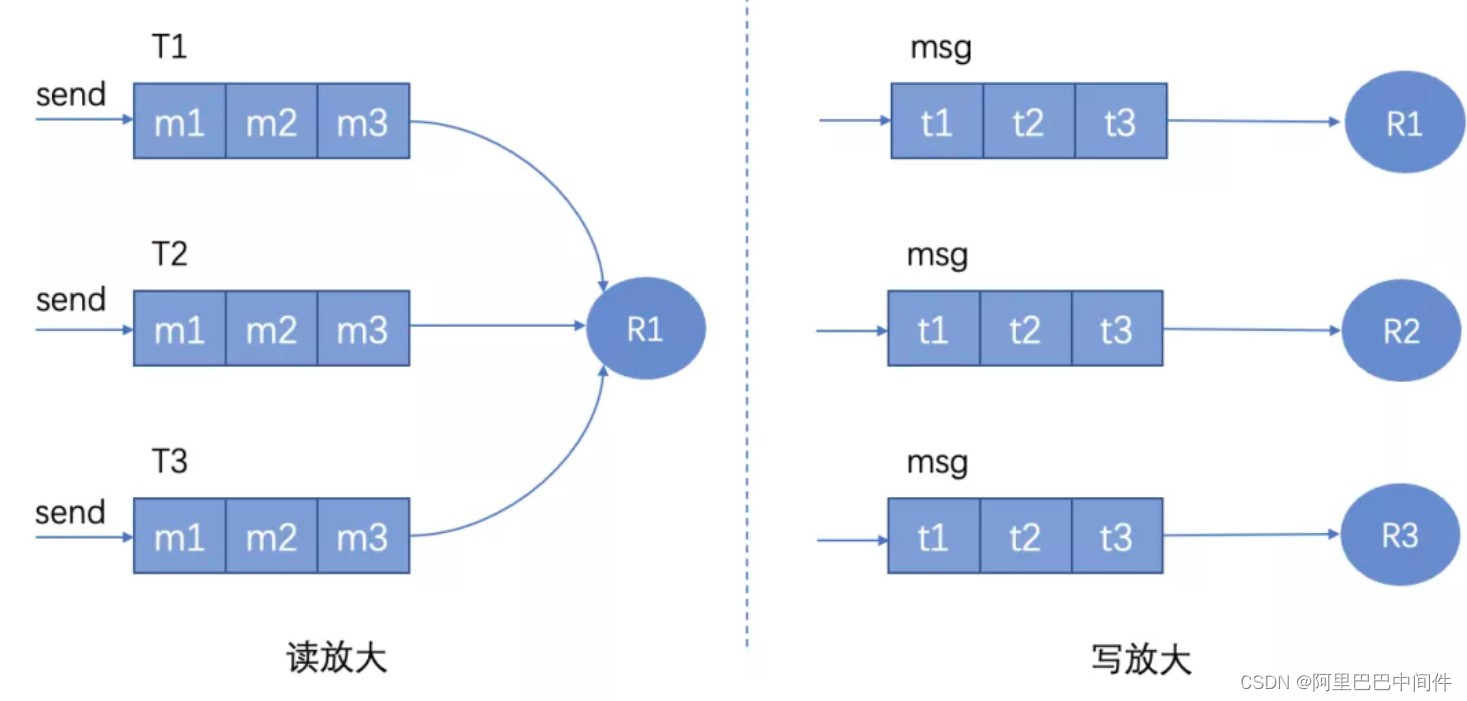

读放大:即消息按 Topic 进行存储,接受者根据订阅的 Topic 列表去相应的 Topic 队列读取消息。
写放大:即消息分别写到所有订阅的接受者队列中,每个接受者读取自己的客户端队列。
可以看到读放大场景下消息只写一份,写到 Topic 维度的队列,但接受者读取时需要按照订阅的 Topic 列表多次读取,而写放大场景下消息要写多份,写到所有接受者的客户端队列里面,显然存储成本较大,但接受者读取简单,只需读取自己客户端一个队列即可。
我们采用的读放大为主,写放大为辅的策略,因为存储的成本和效率对用户的体感最明显。写多份不仅加大了存储成本,同时也对性能和数据准确一致性提出了挑战。但是有一个地方我们使用了写放大模式,就是通配符匹配,因为接受者订阅的是通配符和消息的 Topic 不是一样的内容,接受者读消息时没法反推出消息的 Topic,因此需要在消息发送时根据通配符的订阅多写一个通配符队列,这样接受者直接可以根据其订阅的通配符队列读取消息。
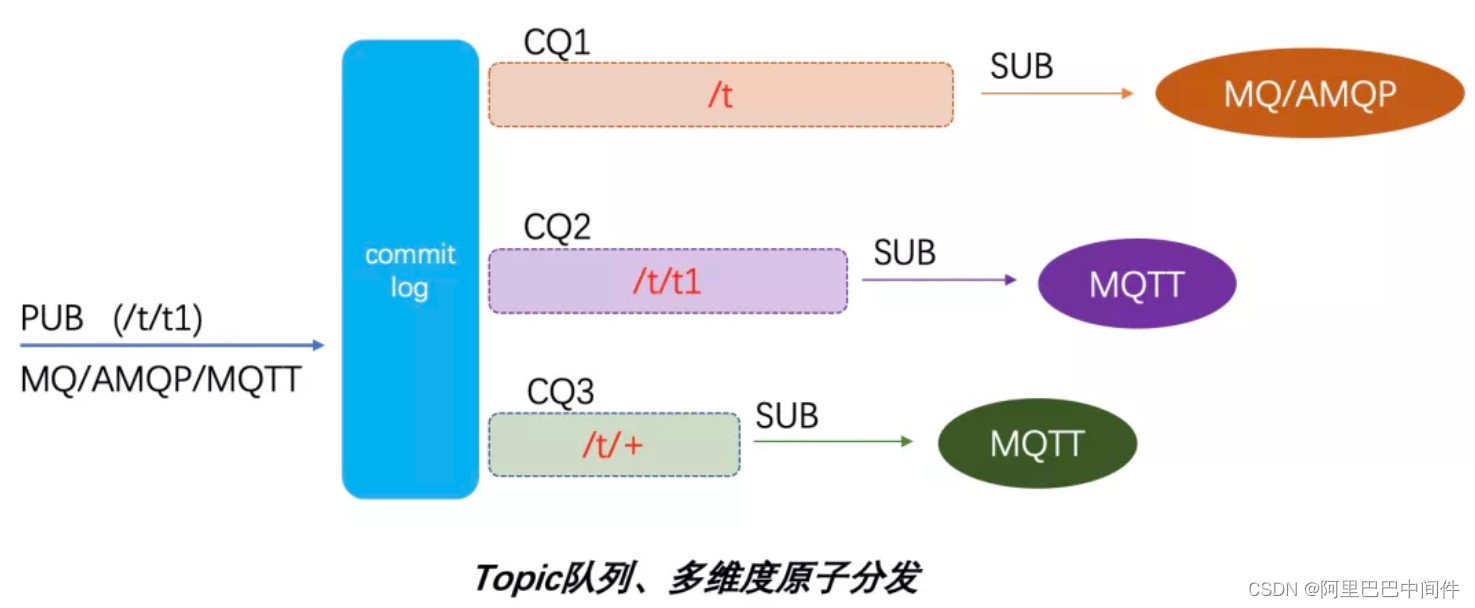
上图描述的接受我们的队列存储模型,消息可以来自各个接入场景(如服务端的 MQ/AMQP,客户端的 MQTT),但只会写一份存到 commitlog 里面,然后分发出多个需求场景的队列索引(ConsumerQueue),如服务端场景(MQ/AMQP)可以按照一级 Topic 队列进行传统的服务端消费,客户端 MQTT 场景可以按照 MQTT 多级 Topic 以及通配符订阅进行消费消息。
这样的一个队列模型就可以同时支持服务端和终端场景的接入和消息收发,达到一体化的目标。
- 推拉模型
介绍了底层的队列存储模型后,我们再详细描述一下匹配查找和可靠触达是怎么做的。

上图展示的是一个推拉模型,图中的 P 节点是一个协议网关或 broker 插件,终端设备通过 MQTT 协议连到这个网关节点。消息可以来自多种场景(MQ/AMQP/MQTT)发送过来,存到 Topic 队列后会有一个 notify 逻辑模块来实时感知这个新消息到达,然后会生成消息事件(就是消息的 Topic 名称),将该事件推送至网关节点,网关节点根据其连上的终端设备订阅情况进行内部匹配,找到哪些终端设备能匹配上,然后会触发 pull 请求去存储层读取消息再推送终端设备。
一个重要问题,就是 notify 模块怎么知道一条消息在哪些网关节点上面的终端设备感兴趣,这个其实就是关键的匹配查找问题。一般有两种方式:1)简单的广播事件;2)集中存储在线订阅关系(如图中的 lookup 模块),然后进行匹配查找再精准推送。事件广播机制看起来有扩展性问题,但是其实性能并不差,因为我们推送的数据很小就是 Topic 名称,而且相同 Topic 的消息事件可以合并成一个事件,我们线上就是默认采用的这个方式。集中存储在线订阅关系,这个也是常见的一种做法,如保存到 Rds、Redis 等,但要保证数据的实时一致性也有难度,而且要进行匹配查找对整个消息的实时链路 RT 开销也会有一定的影响。
可靠触达及实时性这块,上图的推拉过程中首先是通过事件通知机制来实时告知网关节点,然后网关节点通过 Pull 机制来换取消息,然后 Push 给终端设备。Pull+Offset 机制可以保证消息的可靠性,这个是 RocketMQ 的传统模型,终端节点被动接受网关节点的 Push,解决了终端设备轻量问题,实时性方面因为新消息事件通知机制而得到保障。
上图中还有一个 Cache 模块用于做消息队列 cache,因为在大广播比场景下如果为每个终端设备都去发起队列 Pull 请求则对 broker 读压力较大,既然每个请求都去读取相同的 Topic 队列,则可以复用本地队列 cache。
- lookup组件
上面的推拉模型通过新消息事件通知机制来解决实时触达问题,事件推送至网关的时候需要一个匹配查找过程,尽管简单的事件广播机制可以到达一定的性能要求,但毕竟是一个广播模型,在大规模网关节点接入场景下仍然有性能瓶颈。另外,终端设备场景有很多状态查询诉求,如查找在线状态,连接互踢等等,仍然需要一个 KV 查找组件,即 lookup。
我们当然可以使用外部 KV 存储如 Redis,但我们不能假定系统(产品)在用户的交付环境,尤其是专有云的特殊环境一定有可靠的外部存储服务依赖。
这个 lookup 查询组件,实际上就是一个 KV 查询,可以理解为是一个分布式内存 KV,但要比分布式 KV 实现难度至少低一个等级。我们回想一下一个分布式 KV 的基本要素有哪些:

如上图所示,一般一个分布式 KV 读写流程是,Key 通过 hash 得到一个逻辑 slot,slot 通过一个映射表得到具体的 node。Hash 算法一般是固定模数,映射表一般是集中式配置或使用一致性协议来配置。节点扩缩一般通过调整映射表来实现。
分布式 KV 实现通常有三个基本关键点:
1)映射表一致性
读写都需要根据上图的映射表进行查找节点的,如果规则不一致数据就乱了。映射规则配置本身可以通过集中存储,或者 zk、raft 这类协议保证强一致性,但是新旧配置的切换不能保证节点同时进行,仍然存在不一致性窗口。
2)多副本
通过一致性协议同步存储多个备份节点,用于容灾或多读。
3)负载分配
slot 映射 node 就是一个分配,要保证 node 负载均衡,比如扩缩情况可能要进行 slot 数据迁移等。
我们主要查询和保存的是在线状态数据,如果存储的 node 节点宕机丢失数据,我们可以即时重建数据,因为都是在线的,所以不需要考虑多副本问题,也不需要考虑扩缩情况 slot 数据迁移问题,因为可以直接丢失重建,只需要保证关键的一点:映射表的一致性,而且我们有一个兜底机制——广播,当分片数据不可靠或不可用时退化到广播机制。
架构设计
基于前面的理论和模型分析介绍,我们在考虑用什么架构形态来支持一体化的目标,我们从分层、扩展、交付等方面进行一下描述。
- 分层架构
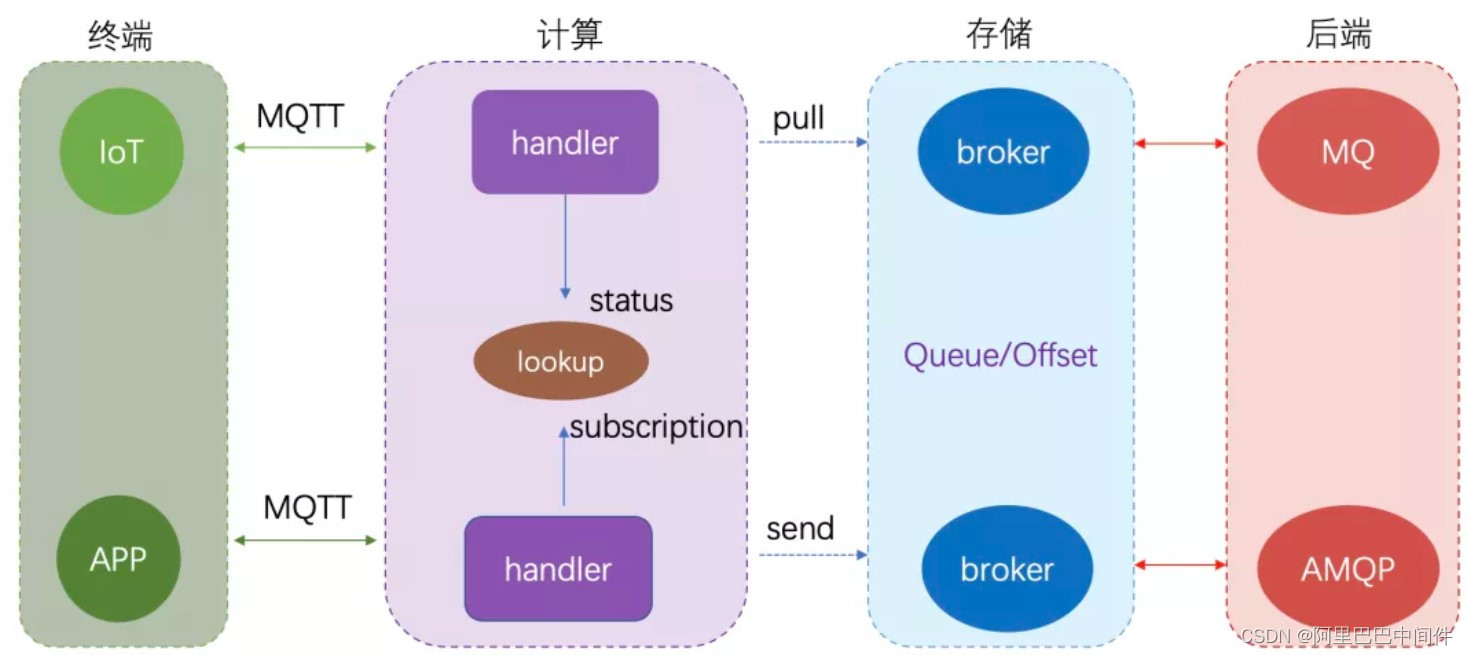
我们的目标是期望基于 RocketMQ 实现一体化且自闭环,但不希望 Broker 被侵入更多场景逻辑,我们抽象了一个协议计算层,这个计算层可以是一个网关,也可以是一个 broker 插件。Broker 专注解决 Queue 的事情以及为了满足上面的计算需求做一些 Queue 存储的适配或改造。协议计算层负责协议接入,并且要可插拔部署。
- 扩展设计
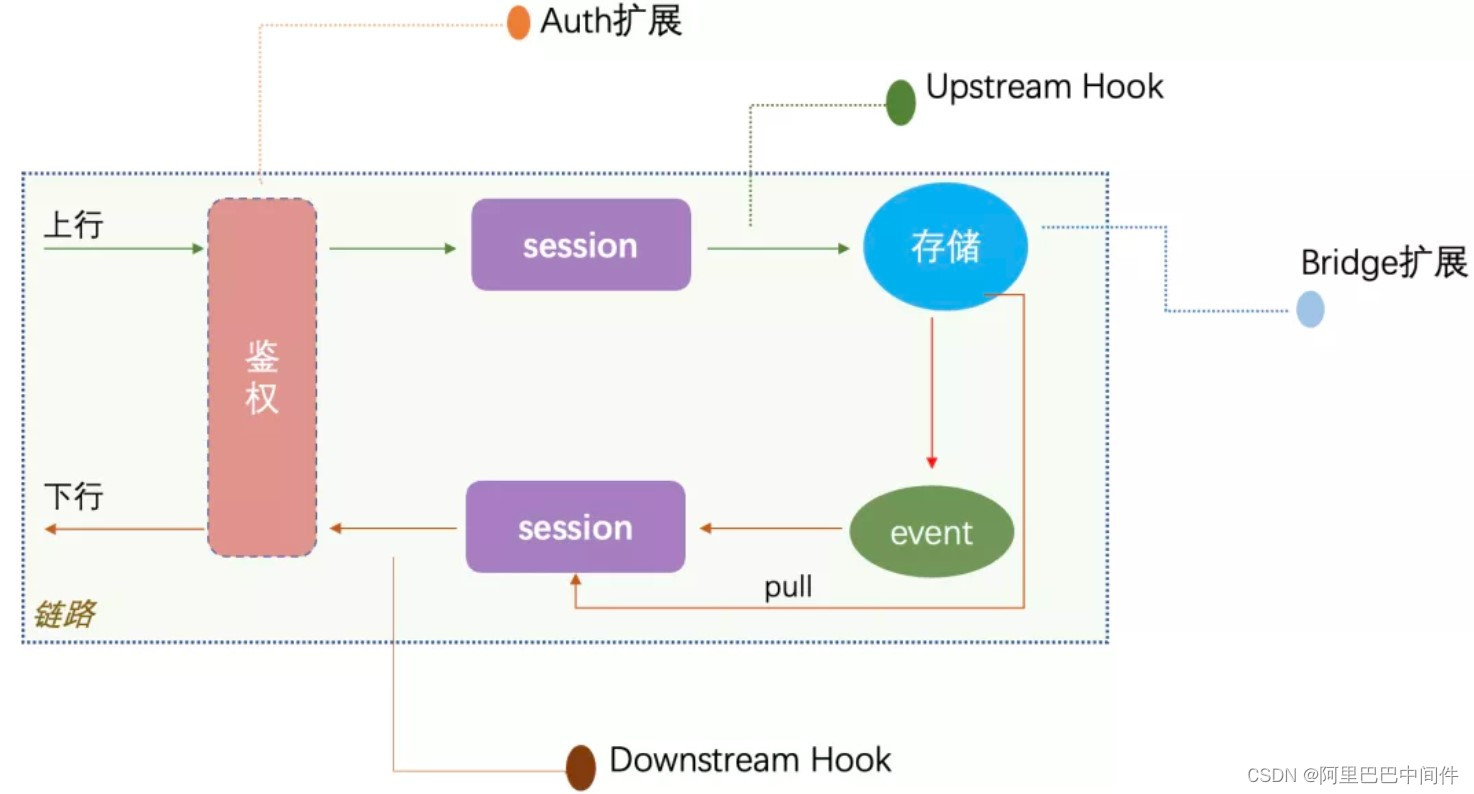
我们都知道消息产品属于 PaaS 产品,与上层 SaaS 业务贴得最近,为了适应业务的不同需求,我们大致梳理一下关键的核心链路,在上下行链路上添加一些扩展点,如鉴权逻辑这个最偏业务化的逻辑,不同的业务需求都不一样,又比如 Bridge 扩展,其能够把终端设备状态和消息数据与一些外部生态系统(产品)打通。
- 交付设计
好的架构设计还是要考虑最终的落地问题,即怎么交付。如今面临的现状是公共云、专有云,甚至是开源等各种环境条件的落地,挑战非常大。其中最大的挑战是外部依赖问题,如果产品要强依赖一个外部系统或产品,那对整个交付就会有非常大的不确定性。
为了应对各种复杂的交付场景,一方面会设计好扩展接口,根据交付环境条件进行适配实现;另一方面,我们也会尽可能对一些模块提供默认内部实现,如上文提到的 lookup 组件,重复造轮子也是不得已而为之,这个也许就是做产品与做平台的最大区别。
统一存储内核
前面对整个协议模型和架构进行了详细介绍,在 Broker 存储层这块还需要进一步的改造和适配。我们希望基于 RocketMQ 统一存储内核来支撑终端和服务端的消息收发,实现一体化的目标。
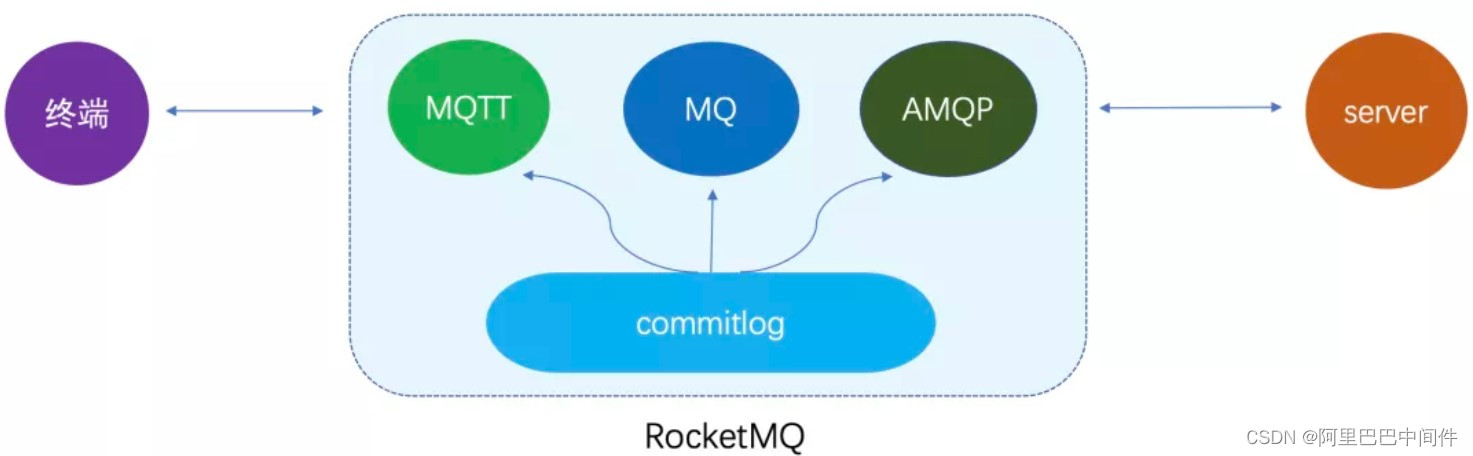
前面也提到了终端消息场景和服务端一个很大的区别是,终端必须要有个客户端维度的队列才能保证可靠触达,而服务端可以使用集中式队列,因为消息随便哪台机器消费都可以,但是终端消息必须明确可靠推送给具体客户端。客户端维度的队列意味着数量级上比传统的 RocketMQ 服务端 Topic 队列要大得多。
另外前面介绍的队列模型里面,消息也是按照 Topic 队列进行存储的,MQTT 的 Topic 是一个灵活的多级 Topic,客户端可以任意生成,而不像服务端场景 Topic 是一个很重的元数据强管理,这个也意味着 Topic 队列的数量级很大。
海量队列
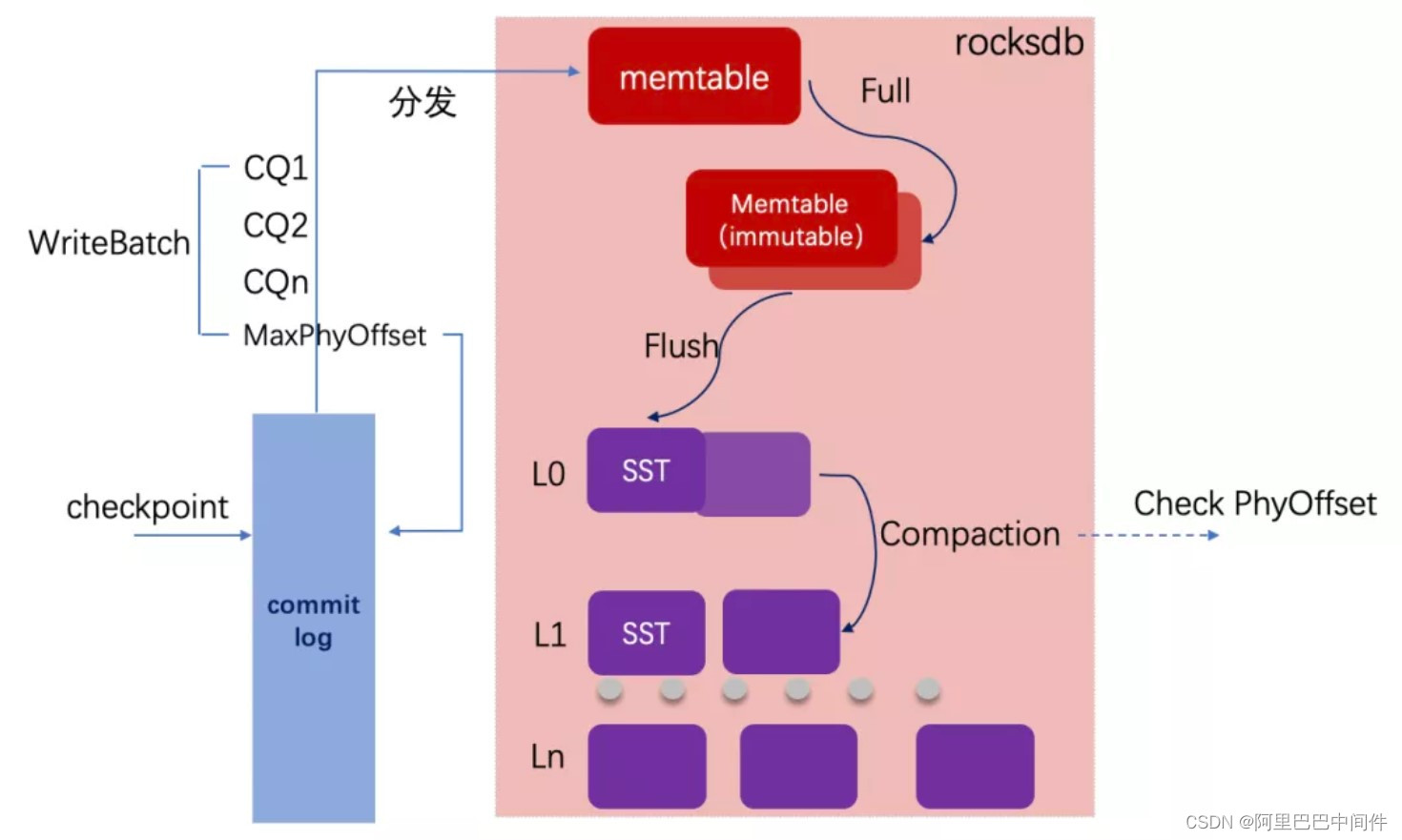
我们都知道像 Kafka 这样的消息队列每个 Topic 是独立文件,但是随着 Topic 增多消息文件数量也增多,顺序写就退化成了随机写,性能下降明显。RocketMQ 在 Kafka 的基础上进行了改进,使用了一个 Commitlog 文件来保存所有的消息内容,再使用 CQ 索引文件来表示每个 Topic 里面的消息队列,因为 CQ 索引数据较小,文件增多对 IO 影响要小很多,所以在队列数量上可以达到十万级。然而这终端设备队列场景下,十万级的队列数量还是太小了,我们希望进一步提升一个数量级,达到百万级队列数量,我们引入了 Rocksdb 引擎来进行 CQ 索引分发。
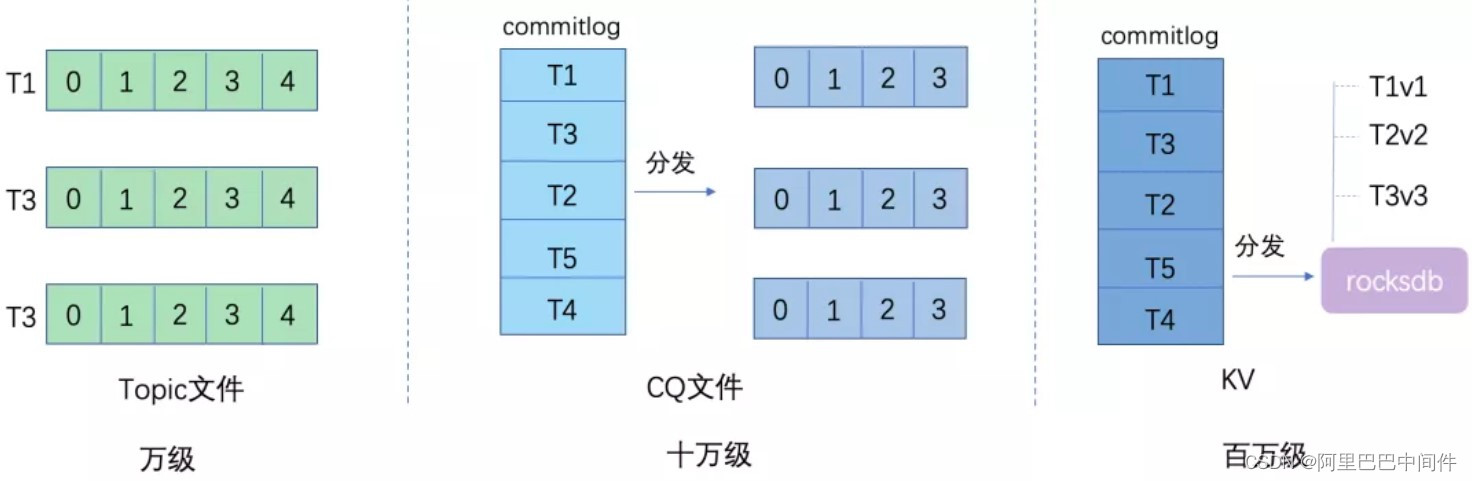
Rocksdb 是一个广泛使用的单机 KV 存储引擎,具有高性能的顺序写能力。因为我们有了 commitlog 已具备了消息顺序流存储,所以可以去掉 Rocksdb 引擎里面的 WAL,基于 Rocksdb 来保存 CQ 索引。在分发的时候我们使用了 Rocksdb 的 WriteBatch 原子特性,分发的时候把当前的 MaxPhyOffset 注入进去,因为 Rocksdb 能够保证原子存储,后续可以根据这个 MaxPhyOffset 来做 Recover 的 checkpoint。我们提供了一个 Compaction 的自定义实现,来进行 PhyOffset 的确认,以清理已删除的脏数据。
轻量Topic
我们都知道 RocketMQ 中的 Topic 是一个重要的元数据,使用前要提前创建,并且会注册到 namesrv 上,然后通过 Topicroute 进行服务发现。前面说了,终端场景订阅的 Topic 比较灵活可以任意生成,如果基于现有的 RocketMQ 的 Topic 重管理逻辑显然有些困难。我们定义了一种轻量的 Topic,专门支持终端这种场景,不需要注册 namesrv 进行管理,由上层协议逻辑层进行自管理,broker 只负责存储。
总结
本文首先介绍了端云消息场景一体化的背景,然后重点分析了终端消息场景特点,以及终端消息场景支撑模型,最后对架构和存储内核进行了阐述。我们期望基于 RocketMQ 统一内核一体化支持终端和服务端不同场景的消息接入目标,以能够给使用者带来一体化的价值,如降低存储成本,避免数据在不同系统间同步带来的一致性挑战。
本文为阿里云原创内容,未经允许不得转载。
RocketMQ 端云一体化设计与实践的更多相关文章
- vivo 服务端监控架构设计与实践
一.业务背景 当今时代处在信息大爆发的时代,信息借助互联网的潮流在全球自由的流动,产生了各式各样的平台系统和软件系统,越来越多的业务也会导致系统的复杂性. 当核心业务出现了问题影响用户体验,开发人员没 ...
- 一套海量在线用户的移动端IM架构设计实践分享(含详细图文)(转)
1.写在前面 1.1.引言 如果在没有太多经验可借鉴的情况下,要设计一套完整可用的移动端IM架构,难度是相当大的.原因在于,IM系统(尤其是移动端IM系统)是多种技术和领域知识的横向应用综合体:网络编 ...
- 一面数据: Hadoop 迁移云上架构设计与实践
背景 一面数据创立于 2014 年,是一家领先的数据智能解决方案提供商,通过解读来自电商平台和社交媒体渠道的海量数据,提供实时.全面的数据洞察.长期服务全球快消巨头(宝洁.联合利华.玛氏等),获得行业 ...
- RocketMQ入门(2)最佳实践
转自:http://www.changeself.net/archives/rocketmq入门(2)最佳实践.html RocketMQ入门(2)最佳实践 一.服务端安装部署 我是在虚拟机中的Cen ...
- Apache Beam实战指南 | 大数据管道(pipeline)设计及实践
Apache Beam实战指南 | 大数据管道(pipeline)设计及实践 mp.weixin.qq.com 策划 & 审校 | Natalie作者 | 张海涛编辑 | LindaAI 前 ...
- MaxCompute表设计最佳实践
MaxCompute表设计最佳实践 产生大量小文件的操作 MaxCompute表的小文件会影响存储和计算性能,因此我们先介绍下什么样的操作会产生大量小文件,从 而在做表设计的时候考虑避开此类操作. 使 ...
- 比特大陆发布终端 AI 芯片 端云联手聚焦安防
雷帝网 乐天 10月17日报道 比特大陆今日正式发布终端人工智能芯片BM1880,一同发布的还有基于云端人工智能芯片 BM1682 的算丰智能服务器 SA3.嵌入式AI迷你机 SE3.3D 人脸识别智 ...
- 跨国合作:Serverless Components 在腾讯云的落地和实践
导语 | Serverless Components 是 Serverless Framework 推出的最新解决⽅案,具有基础设施编排能⼒,开发者通过使⽤ Serverless Components ...
- 华为刘腾:华为终端云Cassandra运维实践分享
点击此处观看完整活动视频 各位线上的嘉宾朋友大家好,我是来自华为消费者BG云服务部的刘腾,我今天给大家分享的主题是华为终端云Cassandra运维实践.和前面王峰老师提到的Cassandra在360中 ...
- 从 FFmpeg 性能加速到端云一体媒体系统优化
7 月 31 日,阿里云视频云受邀参加由开放原子开源基金会.Linux 基金会亚太区.开源中国共同举办的全球开源技术峰会 GOTC 2021 ,在大会的音视频性能优化专场上,分享了开源 FFmpeg ...
随机推荐
- 流媒体通信中RTP/RTCP在项目中的应用
一 概述: 本文档描述RTC通信中RTP/RTCP的应用以及当前项目中的使用策略. 二 RTP/RTCP协议简介 2.1 协议标准 RTP 由 IETF(http://www.ietf.org/)定义 ...
- 00-【K210】API资料、电气接线图、PCB文件
K210的接口说明文档 API接口文档: 链接:https://pan.baidu.com/s/1mlzYRJYQIeHSEMysp_v4cg?pwd=pjmv 提取码:pjmv 2.原理图.PCB文 ...
- 记录--canvas 复刻锤子时钟
这里给大家分享我在网上总结出来的一些知识,希望对大家有所帮助 介绍 canvas:使用脚本 (通常为 JavaScript) 来绘制图形的 HTML 元素. 本人遍历了以下两份文档,学习完就相当于有了 ...
- C++ Concurrency in Action 读书笔记一:thread的管理
为避免混淆,用thread表示std::thread及其对象实例,用线程表示操作系统概念下的线程 Chapter 2 thread的管理 2.1 thread的创建(构造函数) a. 默认构造函数 d ...
- Java中使用fastJson
FastJson简介 Fastjson是阿里巴巴开发的一个开源Java库,用于处理JSON数据,广泛应用于Web服务.API接口.数据交换等多个场景. FastJson的作用 主要作用是用于将Java ...
- Android Graphics 多屏同显/异显
" 亏功一篑,未成丘山.凿井九阶,不次水泽.行百里者半九十,小狐汔济濡其尾.故曰时乎,时不再来.终终始始,是谓君子." 01 前言 随着Android智能驾舱系统的普及各种信息交互 ...
- java 计算两个date日期相差天数或者时间差
相差天数计算: /** * 相差天数计算 */ public int differentDaysByMillisecond(Date date1, Date date2) { return Math. ...
- Markdown文档图片展示问题解决方案
微信不支持Markdown排版 目前来看微信公众号是不支持Markdown语法的,所以就会出现Markdown预览,复制在粘贴完成吧. 从资料收集来看有一款出现频率比较高的插件 Markdown ni ...
- Python爬取imdb电影数据并存储到mysql数据库
数据获取方式:微信搜索关注[靠谱杨阅读人生]回复[电影].整理不易,资源付费,谢谢支持. Python爬虫代码: 1 import re 2 import time 3 import tracebac ...
- 活动报名|OpenHarmony 战“码”先锋,PR 征集令
OpenAtom OpenHarmony(以下简称"OpenHarmony")工作委员会首度发起「OpenHarmony 开源贡献者计划」,旨在鼓励开发者参与 OpenHarmon ...