机器学习算法(一):1. numpy从零实现线性回归
系列文章目录
机器学习算法(一):1. numpy从零实现线性回归
机器学习算法(一):2. 线性回归之多项式回归(特征选取)
@
前言
最近,想将本科学过的一些机器学习算法从零开始实现一下,毕竟天天当调包侠,虽然也能够很愉快的玩耍,但对于我这个强迫症患者是很难受的,底层逻辑是怎么样的,还是需要知道的。接下来我会从最简单的多元线性回归开始,一步一步在\(jupyter\)里面实现。
【注1】:本文默认读者具有基本的机器学习基础、\(numpy\)基础,如果没有建议看完吴恩达老师的机器学习课程在来看本文。
【注2】:本文大部分代码会采用向量化加速编程,当然部分情况下也会用到循环遍历的情况。后面有时间会再出一起循环遍历实现的。
【注3】:作者实力有限,有错在所难免,欢迎大家指出。
一、理论介绍
线性回归的预测函数:
\]
写成向量的形式:$$y = \mathbf{w^Tx}+b $$
其中:\(\mathbf{w} = (w_1,...,w_n)^T,\mathbf{x}=(x_1,...,x_n)^T\)
为了编程方便,将\(b\)收缩到\(w\)向量里面去,有$$\mathbf{w} = (w_0,w_1,...,w_n)^T,w_0=b$$
\]
上面模型变为$$y = \mathbf{w^Tx}$$
损失函数和偏导公式如下:
\]
\]
有了以上的理论操作,下面可以开始操作了
【注】:上述理论推导本文不作说明,有需要可参考周志华老师西瓜书。
二、代码实现
1、导入库
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
库就不用介绍了,很常见的机器学习会用到的库。
2、准备数据集
生成数据集的方式很多,random库,或者你有数据(csv等)都可以。本文重点不是这个,因此简单用numpy手打生成了。
X_train = np.array([[2104, 5, 1, 45], [1416, 3, 2, 40], [852, 2, 1, 35]])
y_train = np.array([[460], [232], [178]])
print(X_train)
print(y_train)
输出结果:

注:我一般喜欢将向量是列向量还是行向量与数学公式中严格对应起来,否则,广播机制出现了问题真的很头疼的。
# 训练集第一列插入全为1的1列
new_column = np.ones((X_train.shape[0], 1)) # 创建一列全是 1 的数组
X_train = np.concatenate((new_column, X_train), axis=1) # 在索引为 0 的位置插入新列
print(X_train)

3、定义预测函数(predict)
def predict(x,w):
'''
:param x: 要预测的样本点向量,x是行向量
:param w: 训练出来的参数向量,w,是列向量
:param b: 训练出来的参数 b ,b可以是标量,也可以是一个元素的数组
:return: prediction,预测值
'''
return np.dot(x,w)
w_init = np.array([ [785.1811367994083],[0.39133535], [18.75376741], [-53.36032453], [-26.42131618]])
x_vec = X_train[0,:]
print(f"x_vec shape {x_vec.shape}, x_vec value: {x_vec}")
# make a prediction
f_wb = predict(x_vec,w_init)
print(f"f_wb shape {f_wb.shape}, prediction: {f_wb}")
输出:
4 代价(损失)函数
向量化加速:
\]
def loss(X,y,w):
m = X.shape[0]
err = np.dot(X,w) -y
return (1/(2*m))*np.dot(err.T,err)
cost = loss(X_train, y_train, w_init)
print(f'Cost at optimal w : {cost}')
输出:
5 计算参数梯度
向量化加速:
\]
def compute_gradient(X, y, w):
err = np.dot(X,w) - y
return (1/len(X))*np.dot(X.T,err)
g = compute_gradient(X_train,y_train,w_init)
print(g)
输出:
6 批量梯度下降
def gradient_descent(X, y, w_in, loss, gradient_function, alpha, num_iters):
J_history = []
# 用来存每进行一次梯度后的损失,方便查看损失变化。如果要画损失变化也是用这个
# w = copy.deepcopy(w_in) #avoid modifying global w within function
w = w_in
for i in range(num_iters):
dj_dw = gradient_function(X, y, w)
w = w - alpha * dj_dw
if i<100000:
J_history.append( loss(X, y, w))
if i % math.ceil(num_iters / 10) == 0:
# 控制间隔 打印出一次损失结果
# 总迭代次数分成均分10组,在每组最后打印一次损失
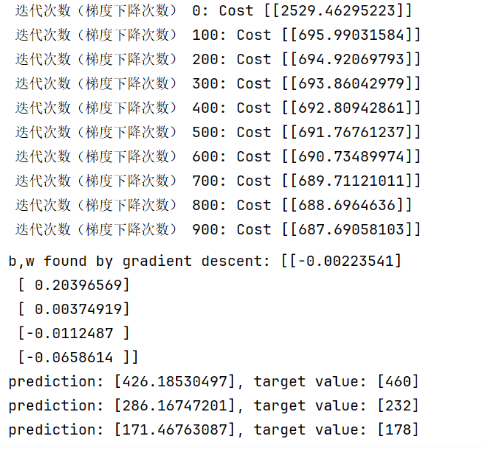
print(f"迭代次数(梯度下降次数) {i}: Cost {J_history[-1]}")
return w,J_history
7 训练
initial_w = np.zeros_like(w_init)
iterations = 1000
alpha = 5.0e-7
# run gradient descent
w_final,J_hist = gradient_descent(X_train, y_train, initial_w,loss, compute_gradient,
alpha, iterations)
print(f"b,w found by gradient descent: {w_final} ")
m = X_train.shape[0]
for i in range(m):
print(f"prediction: {np.dot(X_train[i], w_final)}, target value: {y_train[i]}")
输出:
8 可视化一下损失
J_hist = [i[0,0] for i in J_hist]
# 画一下损失变化图
fig, (ax1, ax2) = plt.subplots(1, 2, constrained_layout=True, figsize=(12, 4))
ax1.plot(J_hist)
ax2.plot(100 + np.arange(len(J_hist[100:])), J_hist[100:])
ax1.set_title("Cost vs. iteration"); ax2.set_title("Cost vs. iteration (tail)")
ax1.set_ylabel('Cost') ; ax2.set_ylabel('Cost')
ax1.set_xlabel('iteration step') ; ax2.set_xlabel('iteration step')
plt.show()
输出:
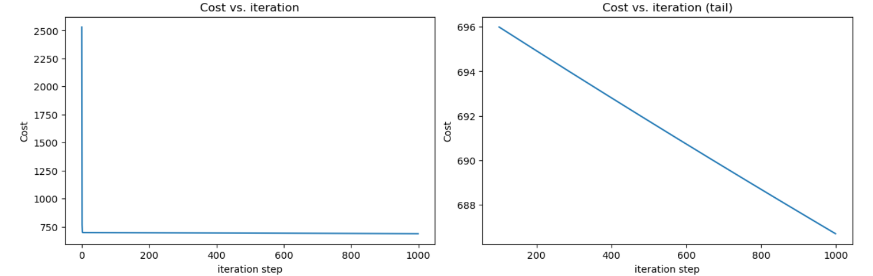
明显看到,随便取的数据集,\(loss\)迭代到后面就稳定600多了,线性回归不太适合该数据集。有时间在用多项式回归试试效果。
总结
以上就是基本的线性回归实现思路了,这里都是用矩阵向量化实现的,大家也可以试试迭代实现。后面有时间,我也会将迭代版本上传的。
【注】:需要\(jupyter\)源文件的可以评论区留言,看到我会回复的。
【注】:最后,作者实力有限,有错误在所难免,欢迎大家指出,会慢慢修改。
机器学习算法(一):1. numpy从零实现线性回归的更多相关文章
- 2018-02-03-PY3下经典数据集iris的机器学习算法举例-零基础
---layout: posttitle: 2018-02-03-PY3下经典数据集iris的机器学习算法举例-零基础key: 20180203tags: 机器学习 ML IRIS python3mo ...
- 机器学习算法与Python实践之(四)支持向量机(SVM)实现
机器学习算法与Python实践之(四)支持向量机(SVM)实现 机器学习算法与Python实践之(四)支持向量机(SVM)实现 zouxy09@qq.com http://blog.csdn.net/ ...
- Python机器学习算法 — 朴素贝叶斯算法(Naive Bayes)
朴素贝叶斯算法 -- 简介 朴素贝叶斯法是基于贝叶斯定理与特征条件独立假设的分类方法.最为广泛的两种分类模型是决策树模型(Decision Tree Model)和朴素贝叶斯模型(Naive Baye ...
- 建模分析之机器学习算法(附python&R代码)
0序 随着移动互联和大数据的拓展越发觉得算法以及模型在设计和开发中的重要性.不管是现在接触比较多的安全产品还是大互联网公司经常提到的人工智能产品(甚至人类2045的的智能拐点时代).都基于算法及建模来 ...
- Computer Science Theory for the Information Age-4: 一些机器学习算法的简介
一些机器学习算法的简介 本节开始,介绍<Computer Science Theory for the Information Age>一书中第六章(这里先暂时跳过第三章),主要涉及学习以 ...
- 机器学习算法与Python实践之(二)支持向量机(SVM)初级
机器学习算法与Python实践之(二)支持向量机(SVM)初级 机器学习算法与Python实践之(二)支持向量机(SVM)初级 zouxy09@qq.com http://blog.csdn.net/ ...
- 简单易学的机器学习算法——EM算法
简单易学的机器学习算法——EM算法 一.机器学习中的参数估计问题 在前面的博文中,如“简单易学的机器学习算法——Logistic回归”中,采用了极大似然函数对其模型中的参数进行估计,简单来讲即对于一系 ...
- 机器学习算法库scikit-learn的安装
scikit-learn 是一个python实现的免费开源的机器学习算法包,从字面意思可知,science 代表科学,kit代表工具箱,直接翻译过来就是用于机器学习的科学计算包. 安装scikit-l ...
- 【机器学习算法-python实现】KNN-k近邻算法的实现(附源代码)
,400],[200,5],[100,77],[40,300]]) shape:显示(行,列)例:shape(group)=(4,2) zeros:列出一个同样格式的空矩阵,例:zeros(group ...
- 机器学习算法与Python实践之(五)k均值聚类(k-means)
机器学习算法与Python实践这个系列主要是参考<机器学习实战>这本书.因为自己想学习Python,然后也想对一些机器学习算法加深下了解,所以就想通过Python来实现几个比较常用的机器学 ...
随机推荐
- Java实现学生投票系统
"感谢您阅读本篇博客!如果您觉得本文对您有所帮助或启发,请不吝点赞和分享给更多的朋友.您的支持是我持续创作的动力,也欢迎留言交流,让我们一起探讨技术,共同成长!谢谢!" 代码 im ...
- 阿里云安全运营中心:DDoS攻击趁虚而入,通过代理攻击已成常态
应用层DDoS攻击与传统的DDoS攻击有着很大不同.传统的DDoS攻击通过向攻击目标发起大流量并发式访问造成服务不可用,系统瘫痪,这种方式比较容易被识破,且市场上已经有成熟的应对方案.而近年来兴起的应 ...
- 开课啦 dubbo-go 微服务升级实战
简介: 杭州开课啦教育科技有限公司是一家致力于为中小学生提供学习辅导的在线教育公司,目前公司后端服务基础设施主要依托于阿里云原生,其中包含计算.网络.存储以及 Kubernetes 服务. 技术选型背 ...
- Apache Flink 在京东的实践与优化
简介: Flink 助力京东实时计算平台朝着批流一体的方向演进. 本文整理自京东高级技术专家付海涛在 Flink Forward Asia 2020 分享的议题<Apache Flink 在京 ...
- [FAQ] Python的虚拟环境和包管理
1. 创建虚拟环境 $ python -m venv test-env 2. 激活虚拟环境 windows:tutorial-env\Scripts\activate (powershell: . ...
- dotnet 6 在 System.Text.Json 使用 source generation 源代码生成提升 JSON 序列化性能
这是一个在 dotnet 6 早就引入的功能,此功能的使用方法能简单,提升的效果也很棒.使用的时候需要将 Json 序列化工具类换成 dotnet 运行时自带的 System.Text.Json 进行 ...
- [ABC345D] Tiling 位运算の极致运用
[ABC345D] Tiling 原题解地址:Editorial by Kiri8128 神写法. 将 \(H \times W\) 的网格展开为 \(H \times (W + 1)\) 的序列, ...
- 【进阶篇】基于 Redis 实现分布式锁的全过程
目录 前言 一.关于分布式锁 二.RedLock 红锁(不推荐) 三.基于 setIfAbsent() 方法 四.使用示例 4.1RedLock 使用 4.2setIfAbsent() 方法使用 五. ...
- Kafka源码分析(四) - Server端-请求处理框架
系列文章目录 https://zhuanlan.zhihu.com/p/367683572 一. 总体结构 先给一张概览图: 服务端请求处理过程涉及到两个模块:kafka.network和kafka. ...
- VSCode:所选环境中没有可用的Pip安装程序
VSCode:所选环境中没有可用的Pip安装程序 然后我尝试格式化我的代码,VSCode说没有安装autopep8,可以通过Pip安装 . 但是,当我尝试通过Pip安装时,它会说 There is n ...