更强的RAG:向量数据库和知识图谱的结合
传统 RAG 的局限性
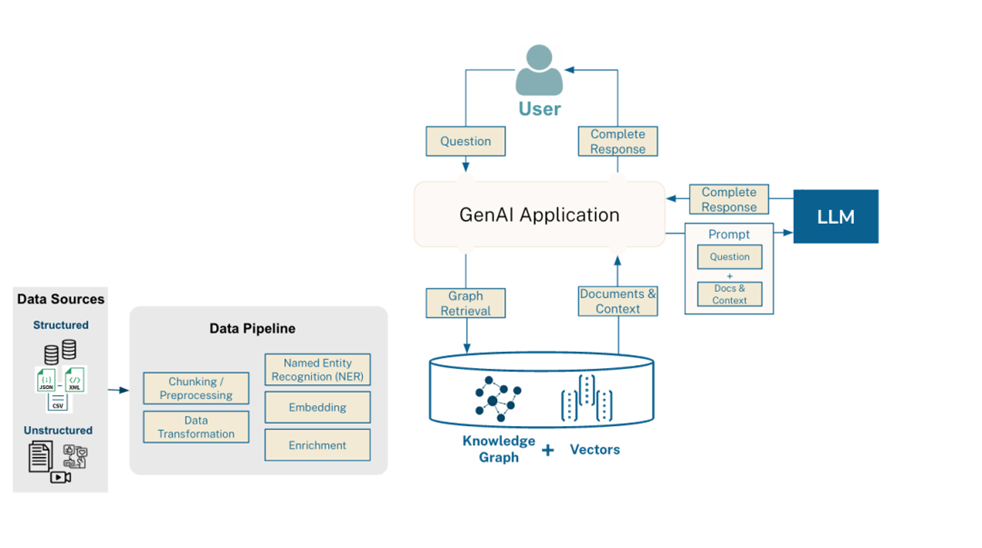
经典的 RAG 架构以向量数据库(VectorDB)为核心来检索语义相似性上下文,让大语言模型(LLM)不需要重新训练就能够获取最新的知识,其工作流如下图所示:
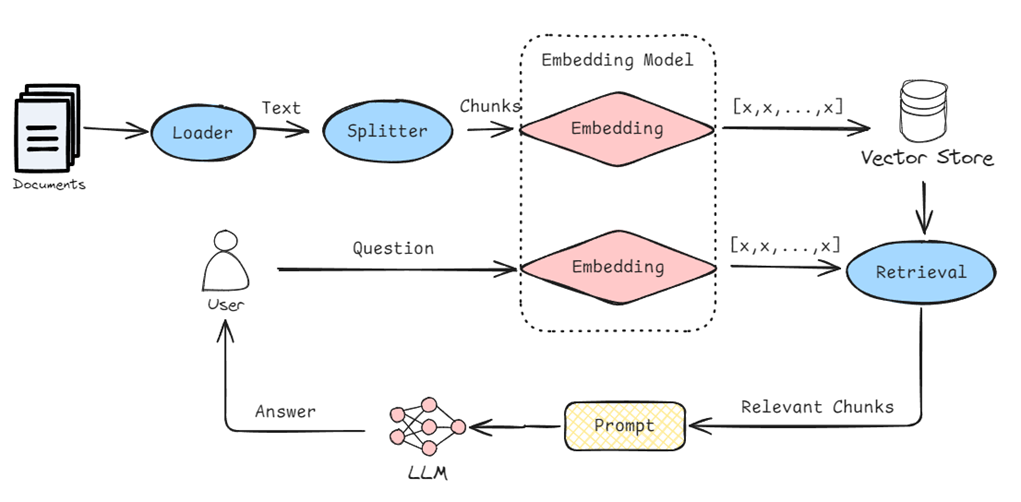
这一架构目前广泛应用于各类 AI 业务场景中,例如问答机器人、智能客服、私域知识库检索等等。虽然 RAG 通过知识增强一定程度上缓解了 LLM 幻觉问题,但是依然面临准确度不高的问题,它受限于信息检索流程固有的限制(比如信息检索相关性、搜索算法效率、Embedding模型)以及大量对 LLM 能力依赖,使得在生成结果的过程中有了更多的不确定性。
下图来自 RAG 领域一篇著名的论文:《Seven Failure Points When Engineering a Retrieval Augmented Generation System》 ,它总结了在使用 RAG 架构时经常会遇到的一些问题(红框部分,原作者称之为7个失败点)。
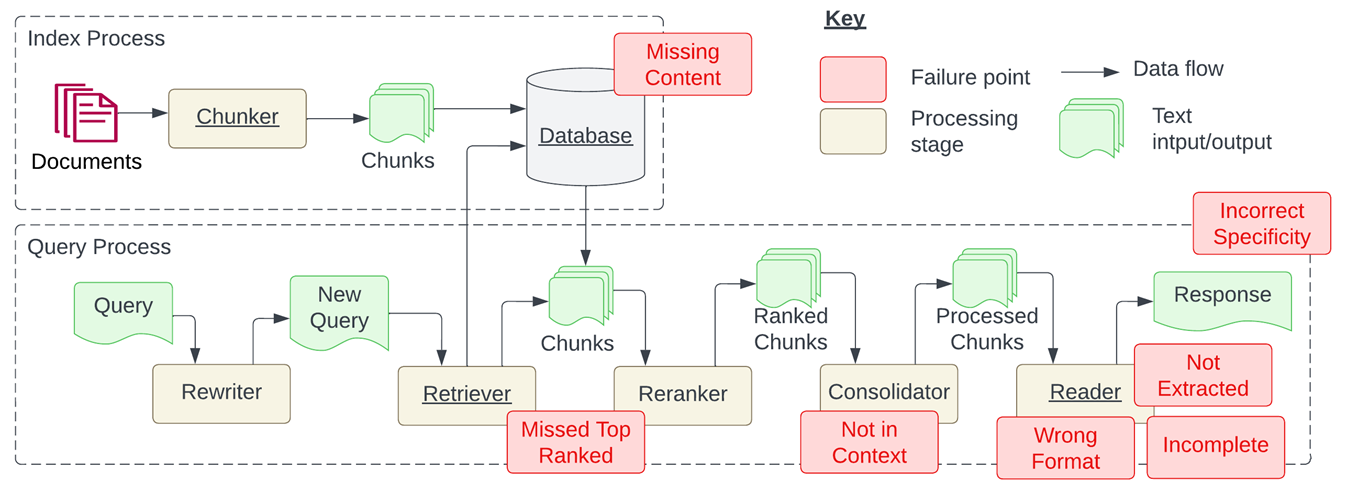
它们包括:
- 内容缺失(Missing Content),用户想要的答案并不在知识库中,LLM会给出无意义的回答。
- 缺失排名靠前的文档(Missed Top Ranked),受限于文本切分方式、大小、嵌入模型等影响,从向量数据库中检索出来的 top-k 不一定是最精确的答案。
- 不在上下文中(Not in Context),和上一条类似,经过各种处理后最终取出来的上下文质量较低。
- 格式错误(Wrong Format),检索出来的结果没有特定格式,而 LLM 没有很好地对其识别分析。
- 未提取(Not Extracted),Prompt 包含大量无关信息影响了 LLM 判断,即上下文包含很多噪音。
- 答案不完整(Incomplete),生成的答案不够完整。
- 不正确的差异(Incorrect Speciticity),答案在响应中返回,但不够具体或过于具体,无法满足用户的需求。
以上问题目前都有一些优化方法来提升回答准确度,但依然离我们的预期有差距。
因此除了基于语义匹配文本块之外,业内也探索新的数据检索形式,比如在语义之上关注数据之间的关联性。这种关联性区别于关系模型中的逻辑性强依赖,而是带有一定的语义关联。比如人和手机是两个独立的实体,在向量数据库中的相似性一定非常差,但是结合实际生活场景,人和手机的关系是非常密切的,假如我搜索一个人的信息,我大可能性也关心他的周边,例如用什么型号的手机、喜欢拍照还是玩游戏等等。
基于这样的关系模型,从知识库检索出来的上下文在某些场景中可能更有效,例如“公司里面喜欢使用手机拍照的人有哪些”。
用知识图谱来呈现数据关系
为了有效地描述知识库中的抽象数据关系,引入了知识图谱的概念,它不再使用二维表格来组织数据,而是用图结构来描述关系,这里面的关系没有固定的范式约束,类似下面这种人物关系图:

上图中有最重要的三个元素:对象(人物)、属性(身份)、关系,对于存储这样的数据有专门的数据库产品来支持,即图数据库。
图数据库(GraphDB)
图数据库是属于 NoSQL 的一种,它有着较为灵活的 schema 定义,可以简单高效表达真实世界中任意的关联关系。图数据库中的主要概念有:
- 实体(Entity),也称之为顶点或节点,图结构中的对象
- 边(Edge),连接两个实体的一条路径,即实体之间的关系
- 属性(Property),用来具体描述实体或边的特征
以上概念可对应到前面的人物关系图。
具体到 schema 定义和数据操作层面,以流行的图数据库 NebulaGraph 为例:
# 创建图空间
CREATE SPACE IF NOT EXISTS test(vid_type=FIXED_STRING(256), partition_num=1, replica_factor=1);
USE test;
# 创建节点和边
CREATE TAG IF NOT EXISTS entity(name string);
CREATE EDGE IF NOT EXISTS relationship(relationship string);
CREATE TAG INDEX IF NOT EXISTS entity_index ON entity(name(256));
# 写入数据
INSERT VERTEX entity (name) VALUES "1":("神州数码");
INSERT VERTEX entity (name) VALUES "2":("云基地");
INSERT EDGE relationship (relationship) VALUES "1"->"2":("建立了");
...
图数据库的查询语法遵循 Cypher 标准:
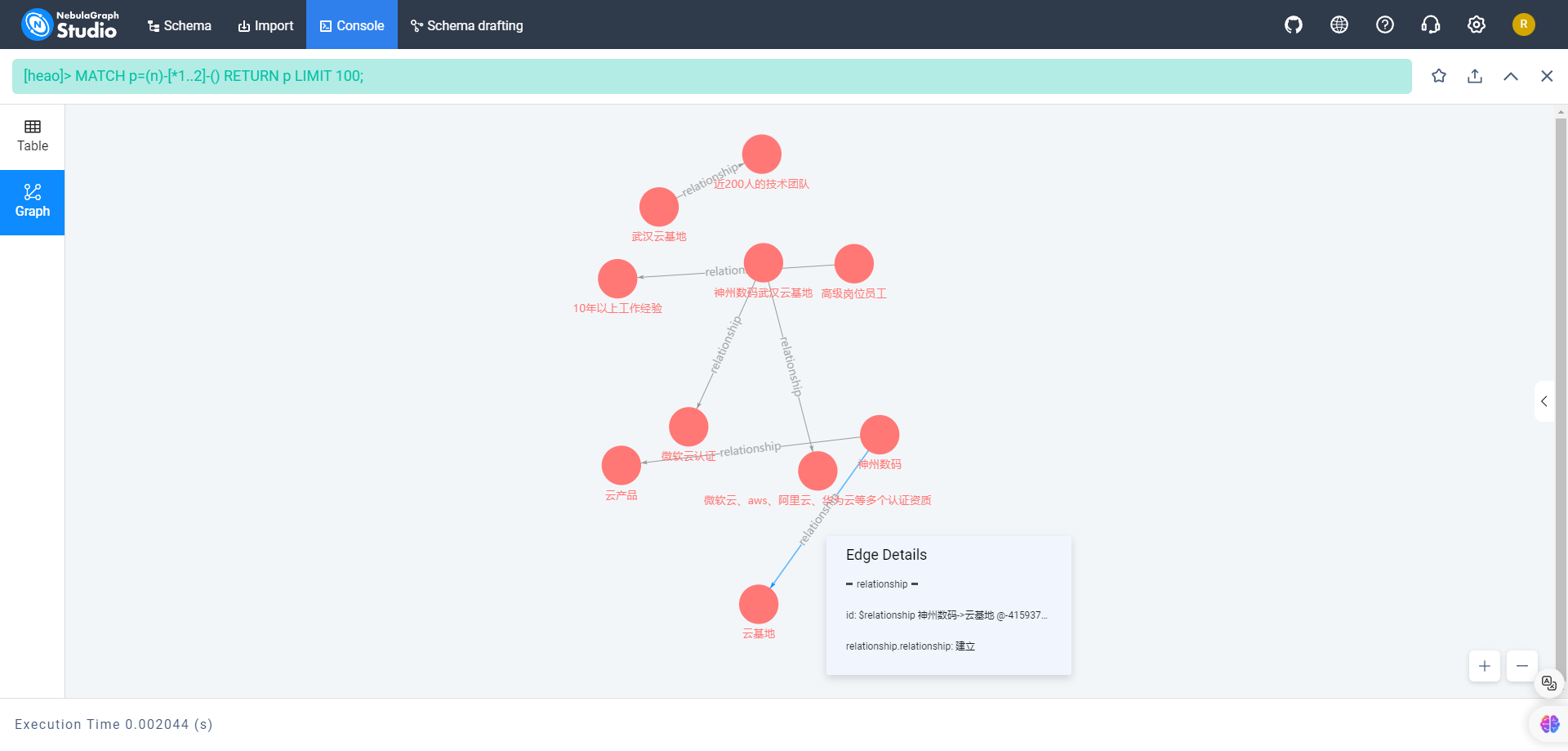
MATCH p=(n)-[*1..2]-() RETURN p LIMIT 100;
以上语句从 NebulaGraph 中找到最多100个从某个节点出发,通过1到2条边连接的路径,并返回这些路径。
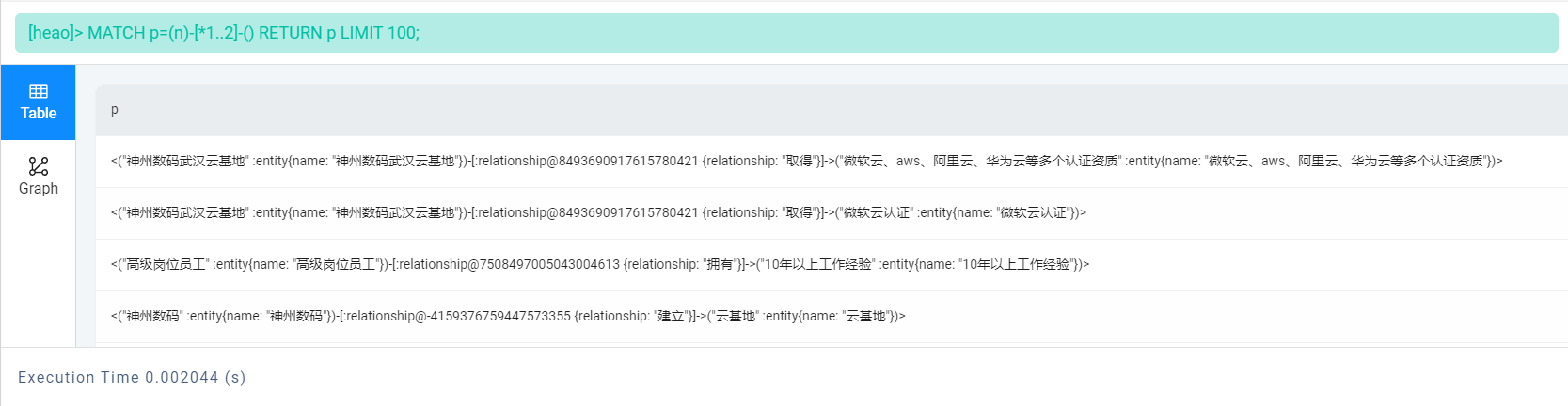
如果用可视化图结构展示的话,它是这个样子:
GraphRAG
如果借用 VectorRAG 的思想,通过图数据库来实现检索增强的话就演变出了 GraphRAG 架构,整体流程和 VectorRAG 并无差异,只是新知识的存储和检索都用知识图谱来实现,解决 VectorRAG 对抽象关系理解较弱的问题。
借助一些AI脚手架工具可以很容易地实现 GraphRAG,以下是用 LlamaIndex 和图数据库 NebulaGraph 实现的一个简易 GraphRAG 应用:
import os
from llama_index.core import KnowledgeGraphIndex, SimpleDirectoryReader
from llama_index.core import StorageContext
from llama_index.graph_stores.nebula import NebulaGraphStore
from llama_index.llms.openai import OpenAI
from pyvis.network import Network
from llama_index.core import (
Settings,
SimpleDirectoryReader,
KnowledgeGraphIndex,
)
# 参数准备
os.environ['OPENAI_API_KEY'] = "sk-proj-xxx"
os.environ["NEBULA_USER"] = "root"
os.environ["NEBULA_PASSWORD"] = "nebula"
os.environ["NEBULA_ADDRESS"] = "10.3.xx.xx:9669"
space_name = "heao"
edge_types, rel_prop_names = ["relationship"], ["relationship"]
tags = ["entity"]
llm = OpenAI(temperature=0, model="gpt-3.5-turbo")
Settings.llm = llm
Settings.chunk_size = 512
# 连接Nebula数据库实例
graph_store = NebulaGraphStore(
space_name=space_name,
edge_types=edge_types,
rel_prop_names=rel_prop_names,
tags=tags,
)
storage_context = StorageContext.from_defaults(graph_store=graph_store)
hosts=graph_store.query("SHOW HOSTS")
print(hosts)
# 抽取知识图谱写入数据库
documents = SimpleDirectoryReader(
"data"
).load_data()
kg_index = KnowledgeGraphIndex.from_documents(
documents,
storage_context=storage_context,
max_triplets_per_chunk=2,
space_name=space_name,
edge_types=edge_types,
rel_prop_names=rel_prop_names,
tags=tags,
max_knowledge_sequence=15,
)
# 信息检索生成答案
query_engine = kg_index.as_query_engine()
response = query_engine.query("神州数码云基地在哪里?")
print(response)
VectorRAG 擅长处理具有一定事实性的问题,对复杂关系理解较弱,而 GraphRAG 刚好弥补了这一点,如果把这两者进行结合,理论上能得到更优的结果。
HybridRAG — 新一代 RAG 架构
我们可以把数据在 VectorDB 和 GraphDB 各放一份,分别通过向量化检索和图检索得到与问题相关结果后,我们将这些结果连接起来,形成统一的上下文,最后将组合的上下文传给大语言模型生成响应,这就形成了 HybridRAG 架构。
由英伟达团队Benika Hall等人在前段时间发表的论文《HybridRAG: Integrating Knowledge Graphs and Vector Retrieval Augmented Generation for Efficient Information Extraction》提出了这一设想,并使用金融服务行业中的数据集成、风险管理、预测分析等场景进行对比验证。在需要从相关文本文档中获取上下文以生成有意义且连贯的响应时 VectorRAG 表现出色,而 GraphRAG 能够从金融文件中提取的结构化信息生成更准确的且具有上下文感知的响应,但 GraphRAG 在抽象问答任务或问题中没有明确提及实体时通常表现不佳。
该论文最后给出了 VectorRAG、GraphRAG和 HybridRAG 的测试结果:

表格中F代表忠实度,用来衡量生成的答案在多大程度上可以从提供的上下文中推断出来。AR代表答案相关性,用来评估生成的答案在多大程度上解决了原始问题。CP代表上下文精度,CR代表上下文召回率。
实现简单的 HybridRAG
以下示例用 Llama_index 作为应用框架,用 TiDB Vector 作为向量数据库,用 NebulaGraph 作为图数据库实现了简单的 HybridRAG 流程:
import os
from llama_index.core import KnowledgeGraphIndex, VectorStoreIndex,StorageContext,Settings
from llama_index.embeddings.openai import OpenAIEmbedding
from llama_index.graph_stores.nebula import NebulaGraphStore
from llama_index.llms.openai import OpenAI
from llama_index.vector_stores.tidbvector import TiDBVectorStore
TIDB_CONN_STR="mysql+pymysql://xx.root:xx@gateway01.eu-central-1.prod.aws.tidbcloud.com:4000/test?ssl_ca=isrgrootx1.pem&ssl_verify_cert=true&ssl_verify_identity=true"
os.environ["OPENAI_API_KEY"] = "sk-proj-xxx"
os.environ["NEBULA_USER"] = "root"
os.environ["NEBULA_PASSWORD"] = "nebula"
os.environ["NEBULA_ADDRESS"] = "10.3.xx.xx:9669"
llm = OpenAI(temperature=0, model="gpt-3.5-turbo")
Settings.llm = llm
Settings.chunk_size = 512
class HybridRAG:
def __init__(self):
# 初始化向量数据库
tidbvec = TiDBVectorStore(
connection_string=TIDB_CONN_STR,
table_name="semantic_embeddings",
distance_strategy="cosine",
vector_dimension=1536, # The dimension is decided by the model
drop_existing_table=False,
)
tidb_vec_index = VectorStoreIndex.from_vector_store(tidbvec)
self.vector_db = tidb_vec_index
# 初始化知识图谱
graph_store = NebulaGraphStore(
space_name="heao",
edge_types=["relationship"],
rel_prop_names=["relationship"],
tags=["entity"],
)
storage_context = StorageContext.from_defaults(graph_store=graph_store)
kg_index = KnowledgeGraphIndex.from_documents(
[],
storage_context=storage_context,
max_triplets_per_chunk=2,
max_knowledge_sequence=15,
)
self.kg = kg_index
# 初始化语言模型
self.llm = llm
# 初始化嵌入模型
self.embeddings = OpenAIEmbedding()
def vector_search(self, query):
# 在向量数据库中搜索相关文本
results = self.vector_db.as_retriever().retrieve(query)
print(results)
return [result.node for result in results]
def graph_search(self, query):
# 在知识图谱中搜索相关信息
results = self.kg.as_retriever().retrieve(query)
print(results)
return [result.node for result in results]
def generate_answer(self, query):
vector_context = self.vector_search(query)
graph_context = self.graph_search(query)
combined_context = "\n".join(vector_context) + "\n" + graph_context
prompt = f"Question: {query}\nContext: {combined_context}\nAnswer:"
return self.llm.generate(prompt)
# 使用示例
hybrid_rag = HybridRAG()
question = "TiDB从哪个版本开始支持资源管控特性?"
answer = hybrid_rag.generate_answer(question)
print(answer)
以上实现中只是简单的拼装了从向量数据库和图数据库中的检索结果,实际应用中可引入相关reranker模型进一步做精排提高上下文精准度。不管最终使用什么样的 RAG 架构,我们要达到的目的始终是保障传递给大语言模型的上下文是更完整更有效的,从而让大语言模型给出更准确的回答。
总结
RAG 架构已经是提升大语言模型能力的有效方案,鉴于在不同的业务场景中正确率无法稳定保持,因此也衍生出了一系列变化后的 RAG 架构,如 Advanced RAG、GraphRAG、HybridRAG、RAG2.0 等等,它们之间有的是互补关系,有的是优化增强,也有另起炉灶的路线,可以看出在 LLM 应用优化上依然处于快速变化当中。
更强的RAG:向量数据库和知识图谱的结合的更多相关文章
- 知识图谱如何运用于RecomSys
将知识图谱作为辅助信息引入到推荐系统中可以有效地解决传统推荐系统存在的稀疏性和冷启动问题,近几年有很多研究人员在做相关的工作.目前,将知识图谱特征学习应用到推荐系统中主要通过三种方式——依次学习.联合 ...
- ERNIE:知识图谱结合BERT才是「有文化」的语言模型
自然语言表征模型最近受到非常多的关注,很多研究者将其视为 NLP 最重要的研究方向之一.例如在大规模语料库上预训练的 BERT,它可以从纯文本中很好地捕捉丰富的语义模式,经过微调后可以持续改善不同 N ...
- 基于pyecharts的中医药知识图谱可视化
基于pyecharts的中医药知识图谱可视化 关键词: pyecharts:可视化:中医药知识图谱 摘要: 数据可视化是一种直观展示数据结果和变化情况的方法,可视化有助于知识发现与应用.Neo4j数据 ...
- 我发起了一个 .Net 平台上的 开源项目 知识图谱 Babana Map 和 文本文件搜索引擎 Babana Search
起因 也是 前几天 有 网友 在 群 里发了 知识图谱 相关的文章, 还有 有 网友 问起 NLog -> LogStash -> Elastic Search 的 问题, ...
- 一个比 Redis 性能更强的数据库
给大家推荐一个比Redis性能更强的数据:KeyDB KeyDB是Redis的高性能分支,侧重于多线程.内存效率和高吞吐量.除了性能改进外,KeyDB还提供主动复制.闪存和子密钥过期等功能.KeyDB ...
- 更强、更稳、更高效:解读 etcd 技术升级的三驾马车
点击下载<不一样的 双11 技术:阿里巴巴经济体云原生实践> 本文节选自<不一样的 双11 技术:阿里巴巴经济体云原生实践>一书,点击上方图片即可下载! 作者 | 陈星宇(宇慕 ...
- 最强最全的Java后端知识体系
目录 最全的Java后端知识体系 Java基础 算法和数据结构 Spring相关 数据库相关 方法论 工具清单 文档 @(最强最全的Java后端知识体系) 最全的Java后端知识体系 最全的Java后 ...
- 阿里面试官必问的12个MySQL数据库基础知识,哪些你还不知道?
数据库基础知识 1.为什么要使用数据库 (1)数据保存在内存 优点: 存取速度快 缺点: 数据不能永久保存 (2)数据保存在文件 优点: 数据永久保存 缺点: 1)速度比内存操作慢,频繁的IO操作. ...
- C# 数据操作系列 - 18 让Dapper更强的插件
0. 前言 在前一篇中我们讲到了Dapper的应用,但是给我们的感觉Dapper不像个ORM更像一个IDbConnection的扩展.是的,没错.在实际开发中我们经常用Dapper作为对EF Core ...
- MySQL数据库基础知识及优化
MySQL数据库基础知识及优化必会的知识点,你掌握了多少? 推荐阅读: 这些必会的计算机网络知识点你都掌握了吗 关于数据库事务和锁的必会知识点,你掌握了多少? 关于数据库索引,必须掌握的知识点 目录 ...
随机推荐
- Python和RPA网页自动化-处理iframe嵌入式框架
以网易云为例,歌曲列表都在<iframe>框架下,使用Python和RPA网页自动化依次点击10首歌的播放键 1.python代码 从网页源代码可见,整个歌曲列表都在<iframe& ...
- 使用 $fetch 进行 HTTP 请求
title: 使用 $fetch 进行 HTTP 请求 date: 2024/8/2 updated: 2024/8/2 author: cmdragon excerpt: 摘要:文章介绍了Nuxt3 ...
- 【H5】03 文本内容处理
摘自: https://developer.mozilla.org/zh-CN/docs/Learn/HTML/Introduction_to_HTML/HTML_text_fundamentals ...
- Git 学习笔记——git checkout
上图是我对git常用用法的一个总结,今天这里主要解释上面操作中没有的 " git checkout "操作. =================================== ...
- 关于mysql配置文件中jdbc url 的记录
版本不同 url不同 大同小异 基本就是不同参数配置的区别 maven 仓库地址 https://mvnrepository.com/artifact/mysql/mysql-connector-ja ...
- Java中如何以文本方式输出"\"
1. 转义符使用 "\"在 java中是一个转义符,只要有它的出现往往有他独特的意义,如下图: 那么,在输出文本时,需要输出"\"怎么办呢,其实很简单,只要多加 ...
- .NET 高效开发Nuget管理工具(开源)
我们.NET开发会引用很多外部Nuget包,多项目.多个解决方案.甚至多个仓库. 简单的Nuget包管理,通过VS就能比较简单处理好.但复杂的场景呢,比如: 1.一个仓库里,有多个解决方案的Nuget ...
- 初探 Rust 语言与环境搭建
1. Rust 简介 Rust 的历史 起源:Rust 语言最初由 Mozilla 研究员 Graydon Hoare 于 2006 年开始设计,并于 2009 年首次公开. 开发:Rust 是 Mo ...
- 模板链表类的扩展(QListEx<T>)
以前写的链表都是比较简单的,插入节点是在头节点上,所以循环链表时都是从最后一个数据往前找的,给人的感觉是倒着的, 今天写一个在链表尾部插入数据 1.链表节点类的定义 /链表节点类 template & ...
- CentOS 7.3离线安装 JDK
1.下载对应的JDK版本 # 网盘链接:https://pan.baidu.com/s/1HMCJis-FEicIcDTgbksBnQ # 密码:q65m 2.查看原系统jdk版本 [bw@local ...