FileBeat简单使用
简介
首先要了解ELK架构
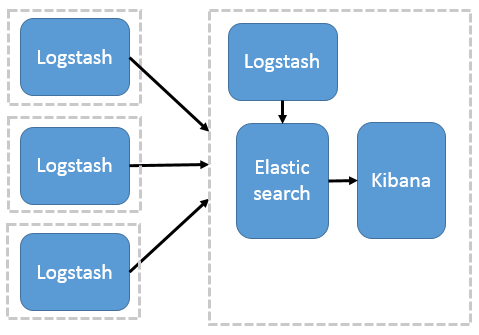
这种结构因为需要在各个服务器上部署 Logstash,而它比较消耗 CPU 和内存资源,所以比较适合计算资源丰富的服务器,否则容易造成服务器性能下降,甚至可能导致无法正常工作。
Beats 同样作为ELK Stack的新成员,包含

Beats 将搜集到的数据发送到 Logstash,经 Logstash 解析、过滤后,将其发送到 Elasticsearch 存储,并由 Kibana 呈现给用户
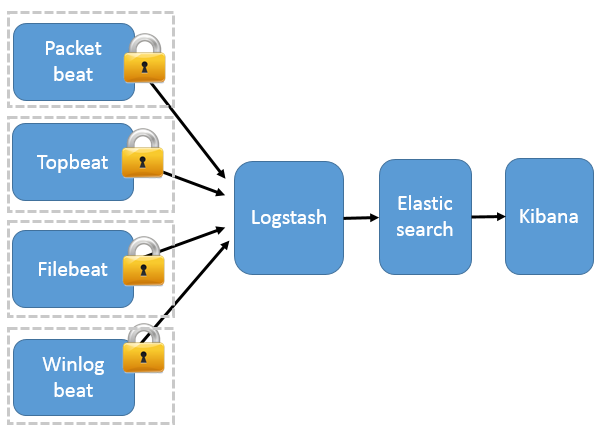
这种架构解决了 Logstash 在各服务器节点上占用系统资源高的问题。
filebeat是一个轻量级日志收集器,有多轻量?和logstatsh一比的话就很轻量了
首先logstatsh是使用java编写的,所以跑起来需要占用jvm资源,默认的堆大小就是1g
而filebeat是使用go语言写的,占用的资源比logstatsh少的多

官网的原话
使用
其实需要我们配置的地方就是收集日志的策略,在filebeat.yml里有很多日志策略的配置
比如说你只要收集info或者error的日志,或者合并某段日志
因为不指定合并日志的策略,filebeat会一行一行的显示在kibana上,但是比如说一些sql的日志就是占几行的
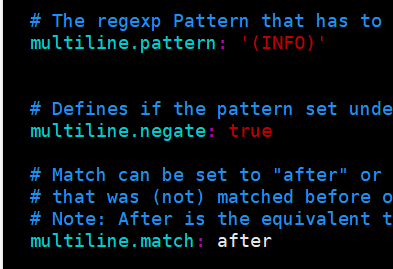
我这里的需求就很简单,日志全部收集,需要合并日志,只要通过配置multiline这个配置
multiline.pattern: '^\['
multiline.negate: true
multiline.match: after
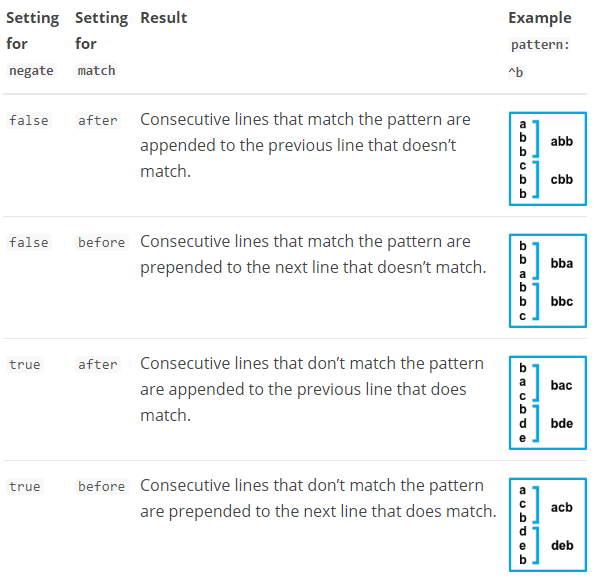
根据你配置其他多行选项的方式,与指定正则表达式匹配的行将被视为上一行的延续或新多行事件的开始。 你可以设置 negate 选项以否定模式。
multiline.pattern 匹配的正则
multiline.match after 或 before,合并到上一行的末尾或开头
multiline.negate 默认是false,匹配pattern的行合并到上一行;true,不匹配pattern的行合并到上一行
效果
实战
日志格式
配置
收集info的日志
原理
示例图

实现
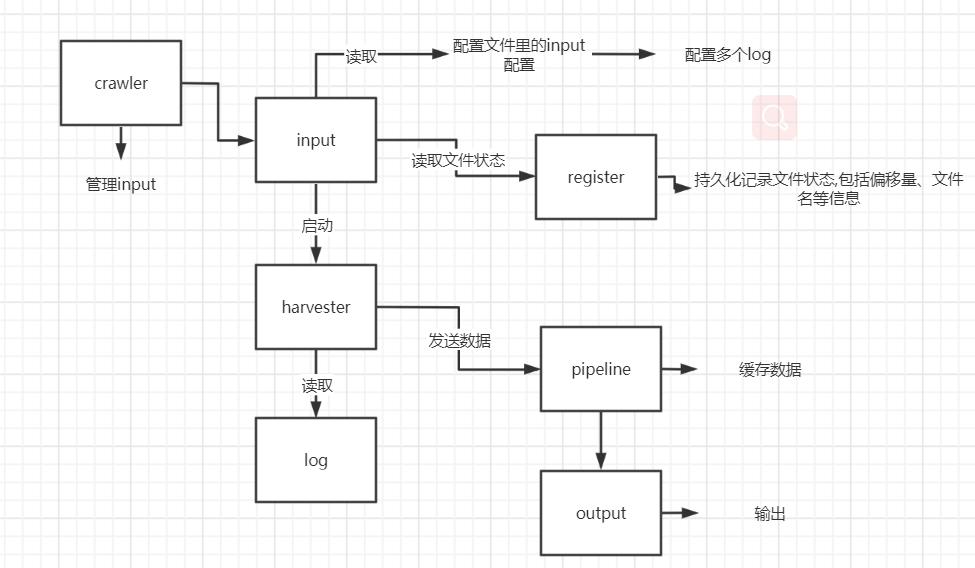
整个 filebeat 主要包含以下重要组件:
- Crawler:负责管理和启动各个 Input
- Input:负责管理和解析输入源的信息,以及为每个文件启动 Harvester。可由配置文件指定输入源信息。
- Harvester: Harvester 负责读取一个文件的信息。
- Pipeline: 负责管理缓存、Harvester 的信息写入以及 Output 的消费等,是 Filebeat 最核心的组件。
- Output: 输出源,可由配置文件指定输出源信息。
- Registrar:管理记录每个文件处理状态,包括偏移量、文件名等信息。当 Filebeat 启动时,会从 Registrar 恢复文件处理状态。
filebeat 的整个生命周期,几个组件共同协作,完成了日志从采集到上报的整个过程。
关于如何保证日志文件的正确性,input里有两个重要的状态offset和finished
- offset: 代表文件当前读取的 offset,从 Registrar 中初始化。Harvest 读取文件后,会同时修改 offset。
- finished: 代表该文件对应的 Harvester 是否已经结束,Harvester 开始时置为 false,结束时置为 True。
对于每次定时扫描到的文件,概括来说,会有三种大的情况:
- Input 找不到该文件状态的记录, 说明是新增文件,则开启一个 Harvester,从头开始解析该文件
- 如果可以找到文件状态,且 finished 等于 false。这个说明已经有了一个 Harvester 在处理了,这种情况直接忽略就好了。
- 如果可以找到文件状态,且 finished 等于 true。说明之前有 Harvester 处理过,但已经处理结束了。
除此之外,一个比较有意思的点是,Filebeat 甚至可以处理文件名修改的问题。即使一个日志的文件名被修改过,Filebeat 重启后,也能找到该文件,从上次读过的地方继读。
这是因为 Filebeat 除了在 Registrar 存储了文件名,还存储了文件的唯一标识。对于 Linux 来说,这个文件的唯一标识就是该文件的 inode ID + device ID。
FileBeat简单使用的更多相关文章
- elk + filebeat,6.3.2版本简单搭建,实现我们自己的集中式日志系统
前言 刚从事开发那段时间不习惯输出日志,认为那是无用功,徒增代码量,总认为自己的代码无懈可击:老大的叮嘱.强调也都视为耳旁风,最终导致的结果是我加班排查问题,花的时间还挺长的,要复现问题.排查问题等, ...
- fileBeat的简单使用
Beat的简单使用 Filebeat配置 Output 常见日志格式封装 简单使用filebeat格式化nginx日志 Filebeat的配置: # 修改filebeat.yml # vim file ...
- Filebeat原理与简单配置入门
Filebeat工作原理 Filebeat由两个主要组件组成:prospectors 和 harvesters.这两个组件协同工作将文件变动发送到指定的输出中. Harvester(收割机):负责读取 ...
- CentOS7下 简单安装和配置Elasticsearch Kibana Filebeat 快速搭建集群日志收集平台
目录 1.添加elasticsearch官网的yum源 2.Elasticsearch 安装elasticsearch 配置elasticsearch 启动elasticsearch并设为开机启动 3 ...
- Filebeat日志收集简单使用
1.简略介绍 轻量型日志采集器,用于转发和汇总日志与文件. 官网: https://www.elastic.co/cn/beats/filebeat 2.本文实现的功能 3.事先必备: 至少一台Kaf ...
- 日志分析 第四章 安装filebeat
在进行前面准备之后可以开始安装了,我们的安装顺序是filebeat--->logstash--->elasticsearch filebeat安装很简单,先下载filebeat,这里我们使 ...
- filebeat安装与基础用法
来自官网,版本为1.2 下载rpm包并安装 wget -c https://download.elastic.co/beats/filebeat/filebeat-1.2.3-x86_64.rpm r ...
- ELK+FileBeat+Log4Net搭建日志系统
ELK+FileBeat+Log4Net搭建日志系统 来源:https://www.zybuluo.com/muyanfeixiang/note/608470 标签(空格分隔): ELK Log4Ne ...
- Logstash学习1-logstash的简单例子
如何安装ELK Redis插件 1. 安装好logstash后.2. 最简单的logstash.logstash -e 'input { stdin { } } output { stdout {} ...
- Filebeat中文指南
Filebeat中文指南 翻译自:https://www.elastic.co/guide/en/beats/filebeat/current/index.html 译者:kerwin 鸣谢:tory ...
随机推荐
- [转帖]Kafka-LEO和HW概念及更新流程
https://www.cnblogs.com/youngchaolin/p/12641463.html 目录 LEO&HW基本概念 LEO&HW更新流程 LEO HW 更新流程示例分 ...
- MySQL数据库存储varchar时多大长度会出现行迁移?
最近客户现场有人问过mysql数据库的一些参数配置的问题, 这边数据库需要将strict 严格模式关掉, 目的是为了保证数据库在插入字段时不会出现8126的长度限制错误问题. 但是一直很困惑, mys ...
- 高性能MySQL实战(二):索引 | 京东物流技术团队
我们在上篇 高性能MySQL实战(一):表结构 中已经建立好了表结构,这篇我们则是针对已有的表结构和搜索条件为表创建索引. 1. 根据搜索条件创建索引 我们还是先将表结构的初始化 SQL 拿过来: C ...
- MySQL查询语句(1)
连接数据库 mysql -hlocalhost -uroot -proot DQL-介绍 DQL英文全称是Data Query Language(数据查询语言),数据查询语言,用来查询数据库中表的记录 ...
- Git的使用(一):创建本地仓库并在其中添加、修改、删除文件
创建本地版本库 版本库又名仓库,英文名repository,可以简单理解成一个目录,这个目录里面的所有文件都可以被Git管理起来,每个文件的修改.删除,Git都能跟踪,以便任何时刻都可以追踪历史,或者 ...
- Linux 多种方式实现文件共享
文件共享服务在Linux系统上有多种方式,最常用的有Samba,vsftp,iSCSI,NFS这四种方式,如下将分别配置四种不同的文件共享服务. VSFTP 文件传输 FTP是文件传输协议.用于Int ...
- Visual Basic 6的安装与辅助插件 - 初学者系列 - 学习者系列文章
好久没玩VB6了,今天无聊,就把原来的VB6相关的代码翻了出来,然后上了VMWare虚拟机,把VB6安装上,然后把架构设计那个模板找出来完善了一下.看了一下,VB6这块需要记录一些内容,于是有了本文. ...
- 树莓派4B改造成云桌面客户端,连接DoraCloud免费版
Raspberry Pi(树莓派) 是为学习计算机编程教育而设计的只有信用卡大小的微型电脑,自问世以来受众多计算机发烧友和创客的追捧,曾经一"派"难求. DoraCloud是一款多 ...
- docker容器-乌班图安装vim
apt-get update && apt-get install -y vim
- .NET 云原生架构师训练营(模块二 基础巩固 引入)--学习笔记
2.1 引入 http协议 web server && web application framework .net 与 .net core asp .net core web api ...