LLM在text2sql上的应用
一、前言:
目前,大模型的一个热门应用方向text2sql它可以帮助用户快速生成想要查询的SQL语句。那对于用户来说,大部分简单的sql都是正确的,但对于一些复杂逻辑来说,需要用户在产出SQL的基础上进行简单修改,Text2SQL应用主要还是帮助用户去解决开发时间,减少开发成本。
Text to SQL: 简称Text2SQl,是将自然语言文本(Text)转换成结构化查询语言SQL的过程,属于自然语言处理-语义分析(Semantic Parsing)领域中的子任务。
它的目的可以简单概括为:“打破人与结构化数据之间的壁垒”,即普通用户可以通过自然语言描述完成复杂数据库的查询工作,得到想要的结果。
二、背景应用:
目前大家对T2S的做法大致分为两种,
- 一种是用现有的大模型来直接生成,例如ChatGPT、GPT-4模型,但是对于一些公司来说,数据是属于保密资产,这种方式相当于将自己公司的数据信息透漏给大模型,属于数据泄露行为;
- 另一种方式是利用开源的大模型做finetune,比如chatglm2-6b来做微调,这个也是目前我们在做的,同时开源的数据集也有很多,简单罗列如下:
| 数据集 | 数据集介绍 |
|---|---|
| WikiSQL | WikiSQL是一个大型的语义解析数据集,由80,654个自然语句表述和24,241张表格的sql标注构成。 WikiSQL中每一个问句的查询范围仅限于同一张表,不包含排序、分组、子查询等复杂操作。 虽然数据规模大,SQL语法却非常简单;适合做NL2SQL任务入门。 |
| Spider | 耶鲁大学在2018年新提出的一个大规模的NL2SQL(Text-to-SQL)数据集。 该数据集包含了10,181条自然语言问句、分布在200个独立数据库中的5,693条SQL,内容覆盖了138个不同的领域。 涉及的SQL语法最全面,是目前难度最大的NL2SQL数据集。 |
| Cspider | CSpider是Spider的中文版,西湖大学出品。 |
| Sparc | 耶鲁大学在2019年提出的基于对话的Text-to-SQL数据集。 SParC是一个跨域上下文语义分析的数据集,是Spider任务的上下文交互版本。SParC由4298个对话(12k+个单独的问题,每个对话平均4-5个子问题,由14个耶鲁学生标注)组成,这些问题通过用户与138个领域的200个复杂数据库进行交互获得。 |
| CHASE | 微软亚研院和北航、西安交大联合提出的首个大规模上下文依赖的Text-to-SQL中文数据集。 内容分为CHASE-C和CHASE-T两部分,CHASE-C从头标注实现,CHASE-T将Sparc从英文翻译为中; 相比以往数据集,CHASE大幅增加了hard类型的数据规模,减少了上下文独立样本的数据量,弥补了Text2SQL多轮交互任务中文数据集的空白。 |
三、Text2SQL使用:
我们在Text2SQL上面的应用主要包括两个阶段,第一阶段是利用LLM理解你的请求,通过请求去生成结构化的SQL;下一个阶段是在生成的SQL上自动化的查询数据库,返回结果,然后利用LLM对结果生成总结,提供分析。
3.1 第一阶段:
利用LLM理解文本信息,生成SQL,目前通过spider数据集来评测,GPT家族还是笑傲群雄。但是这里我们如果只借助GPT来做的话,就会出现之前说的数据隐私问题。
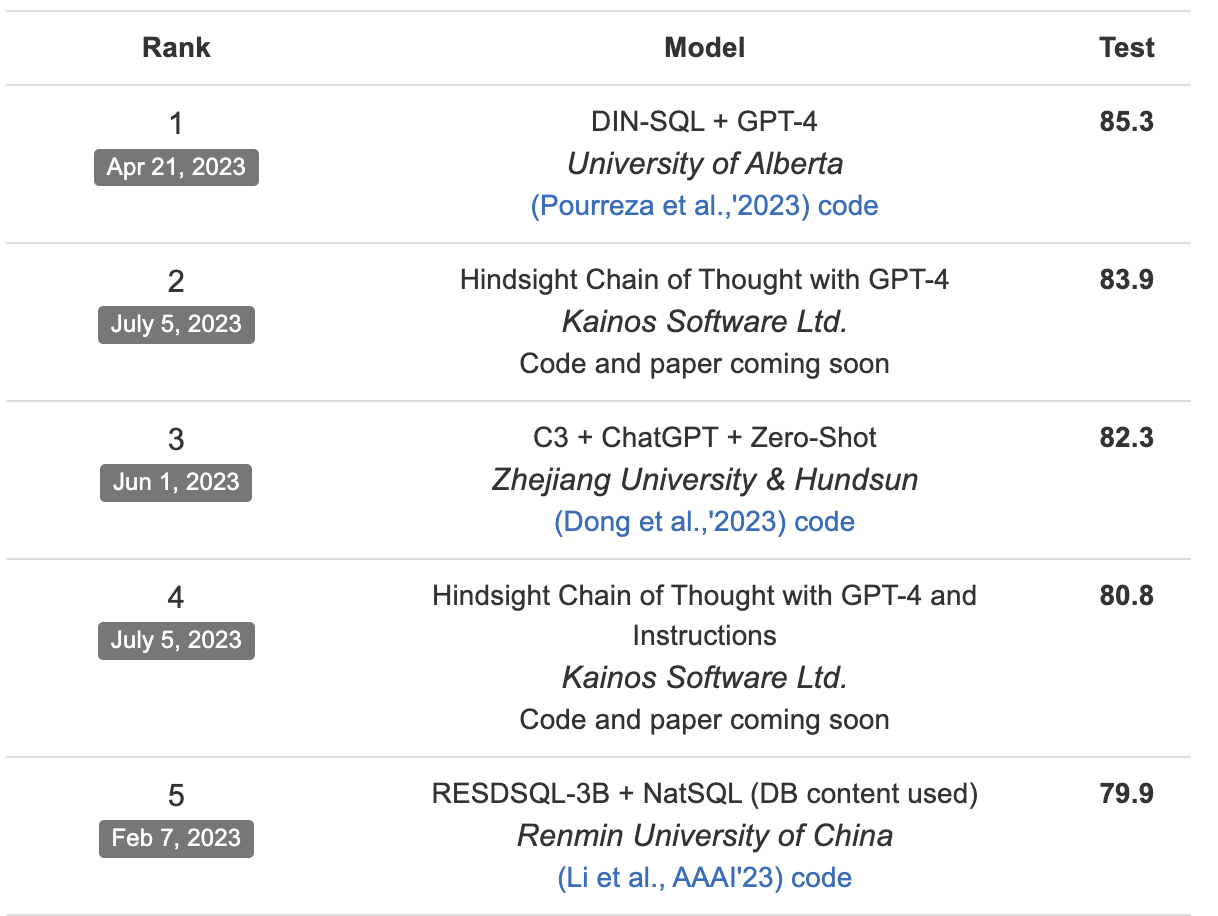
这里我们通过两部分来提升LLM对文本的理解,生成更符合我们要求的结果。
1. 构建数据信息表的schema,利用LLM生成embedding
由于我们从离线评测效果来看,开源模型chatglm2-6b直接生成的SQL和GPT对比,还是有比较大的差距,所以无法直接使用。这里我们根据用户描述的text,让预训练的chatglm2-6b生成embedding,通过embedding检索的方式,选出top1数据表,这个过程属于先验过滤阶段。
数据表的schema设计非常重要,需要描述清楚这个表它的主体信息以及表中重要字段和字段含义。
例:
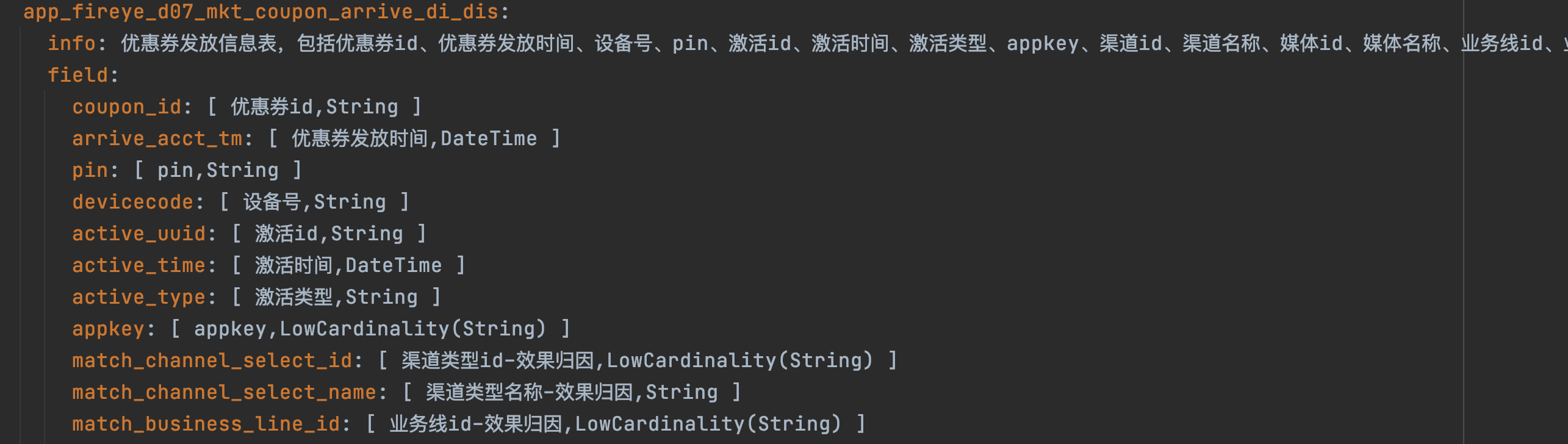
数据表的embedding可以提前计算保存,这样利用后期检索效率。
2. prompt构建,生成SQL
这部分我认为最重要的还是如何去合理构建prompt,让LLM去理解你的真实意图,生成标准的SQL。
一是prompt的开头需要定义构建,二是prompt整体结构以及结构中数据表的信息也需要涵盖进去,这里我们prompt的开头首先定义LLM的工作目的是生成SQL,通过我们根据第一部分返回的top1数据表,解析数据表中的信息,加入到prompt中,以此来构建完成的prompt。
1)开头prompt定义:

2)数据表prompt定义:

3)In-context-prompt:如果想强化prompt,可以增加一些正样本“问答”式的结构,让LLM去学习理解,最终生成更理想的结果

prompt的构建对最终结果的影响非常重要,构建一个完美的prompt可能已经成功了一半。
通过以上的prompt构建,我们就可以给LLM让模型生成最终的SQL结果。

3.2 第二阶段:
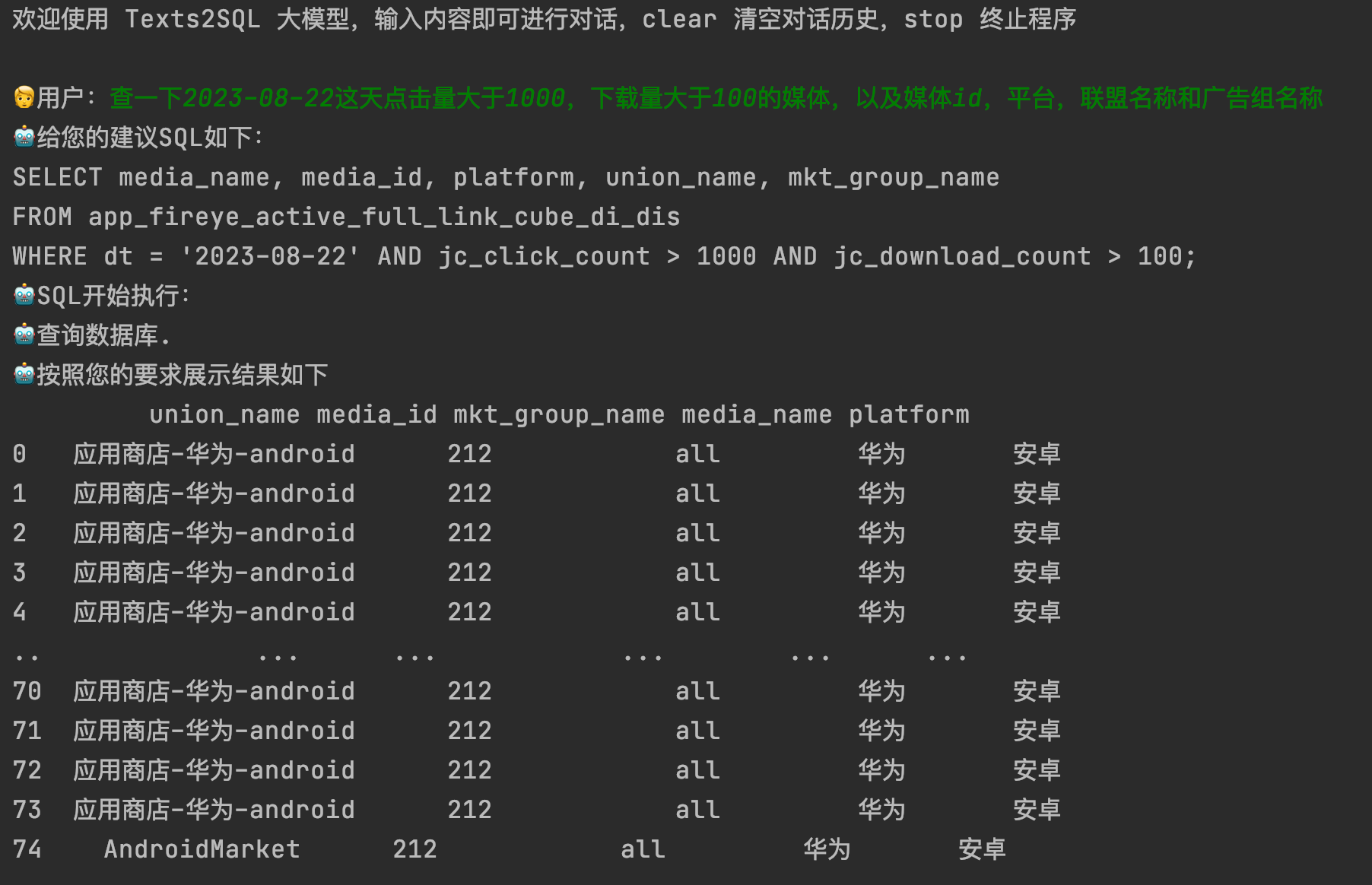
其实很多场景上一阶段生成SQL就已经达到我们想要的结果,但这里我们还想进一步根据SQL生成最终的数据,所以需要连接数据库,SQL运行返回结果。这里我们通过连接集团CK数据库,以接口的形式进行部署,我们在运行SQL的时候,其实就是调用接口,这样方便简洁,对接口返回的结果进行结构化的输出就可以。
通过接口访问结构化输出:

四、结果:
以上就是目前我们根据LLM来生成SQL,同时让SQL自动运行产生结果。前期我们利用GPT模型去跑通整个pipeline,同时生成一些训练数据集,来提供chatglm2-6b微调,后期我们还会对产出的结果进行数据分析,这个阶段也是利用LLM来完成,通过这种方式给用户一些指导性的意见或总结。
以下是整个pipeline的流程:
作者:京东零售 郑少强
来源:京东云开发者社区 转载请注明来源
LLM在text2sql上的应用的更多相关文章
- 🤗 PEFT: 在低资源硬件上对十亿规模模型进行参数高效微调
动机 基于 Transformers 架构的大型语言模型 (LLM),如 GPT.T5 和 BERT,已经在各种自然语言处理 (NLP) 任务中取得了最先进的结果.此外,还开始涉足其他领域,例如计算机 ...
- Hugging Face 每周速递: Chatbot Hackathon;FLAN-T5 XL 微调;构建更安全的 LLM
每一周,我们的同事都会向社区的成员们发布一些关于 Hugging Face 相关的更新,包括我们的产品和平台更新.社区活动.学习资源和内容更新.开源库和模型更新等,我们将其称之为「Hugging Ne ...
- 在一张 24 GB 的消费级显卡上用 RLHF 微调 20B LLMs
我们很高兴正式发布 trl 与 peft 的集成,使任何人都可以更轻松地使用强化学习进行大型语言模型 (LLM) 微调!在这篇文章中,我们解释了为什么这是现有微调方法的有竞争力的替代方案. 请注意, ...
- 微软开源了一个 助力开发LLM 加持的应用的 工具包 semantic-kernel
在首席执行官萨蒂亚·纳德拉(Satya Nadella)的支持下,微软似乎正在迅速转变为一家以人工智能为中心的公司.最近微软的众多产品线都采用GPT-4加持,从Microsoft 365等商业产品到& ...
- 大语言模型快速推理: 在 Habana Gaudi2 上推理 BLOOMZ
本文将展示如何在 Habana Gaudi2 上使用 Optimum Habana.Optimum Habana 是 Gaudi2 和 Transformers 库之间的桥梁.本文设计并实现了一个大模 ...
- Semantic Kernel 入门系列:🪄LLM的魔法
ChatGPT 只是LLM 的小试牛刀,让人类能够看到的是机器智能对于语言系统的理解和掌握. 如果只是用来闲聊,而且只不过是将OpenAI的接口封装一下,那么市面上所有的ChatGPT的换皮应用都差不 ...
- 道德与社会问题简报 #3: Hugging Face 上的道德开放性
使命: 开放和优秀的机器学习 在我们的使命中,我们致力于推动机器学习 (ML) 的民主化,我们在研究如何支持 ML 社区工作并有助于检查危害和防止可能的危害发生.开放式的发展和科学可以分散力量,让许多 ...
- Asp.Net Mvc 使用WebUploader 多图片上传
来博客园有一个月了,哈哈.在这里学到了很多东西.今天也来试着分享一下学到的东西.希望能和大家做朋友共同进步. 最近由于项目需要上传多张图片,对于我这只菜鸟来说,以前上传图片都是直接拖得控件啊,而且还是 ...
- [APUE]进程控制(上)
一.进程标识 进程ID 0是调度进程,常常被称为交换进程(swapper).该进程并不执行任何磁盘上的程序--它是内核的一部分,因此也被称为系统进程.进程ID 1是init进程,在自举(bootstr ...
- 关于解决python线上问题的几种有效技术
工作后好久没上博客园了,虽然不是很忙,但也没学生时代闲了.今天上博客园,发现好多的文章都是年终总结,想想是不是自己也应该总结下,不过现在还没想好,等想好了再写吧.今天写写自己在工作后用到的技术干货,争 ...
随机推荐
- GO web学习(三)
跟着b站https://space.bilibili.com/361469957 杨旭老师学习做的笔记 路由 Controller / Router 角色 main():设置类工作 controlle ...
- RabbitMQ 多消费者 使用单信道和多信道区别
RabbitMQ 多个消费者共用一个信道实例 与 每个消费者使用不同的信道实例 区别: 1. 多个消费者共用一个信道实例:这种方式下,多个消费者共享同一个信道实例来进行消息的消费. 优点:这样可以减少 ...
- 关于ChatGPT与机器时代的展望
关于 ChatGPT 与机器时代的展望 机器人这一概念,最初不是出自计算机科学家或工程师之手,而是来自于捷克的戏剧家卡雷尔·恰佩克(Karl Capek)在 1920 年编排的一出名为"罗森 ...
- linux内核编译体验篇(一)
文章目录 一. 准备环境 二. 获取内核源码 三. 交叉编译工具链的配置 1. 博友们常用安装方法链接 2. 公司常用的交叉工具链使用方法 四. 内核解压以及如何打补丁 五. 内核基本配置 1. 编译 ...
- 2021-3-13 xml的增删改查
public void XmlAdd(string filename, List<People> pList) { try { List<People> peoples = X ...
- 并发编程-CompletableFuture解析
1.CompletableFuture介绍 CompletableFuture对象是JDK1.8版本新引入的类,这个类实现了两个接口,一个是Future接口,一个是CompletionStage接口. ...
- 渗透-02:HTTPS主干-分支和HTTPS传输过程
一.HTTPS主干-分支 第一层 第一层,是主干的主干,加密通信就是双方都持有一个对称加密的秘钥,然后就可以安全通信了. 问题就是,无论这个最初的秘钥是由客户端传给服务端,还是服务端传给客户端,都是明 ...
- OpenCV实战:从图像处理到深度学习的全面指南
本文深入浅出地探讨了OpenCV库在图像处理和深度学习中的应用.从基本概念和操作,到复杂的图像变换和深度学习模型的使用,文章以详尽的代码和解释,带领大家步入OpenCV的实战世界. 1. OpenCV ...
- 聊聊自然语言处理NLP
概述 自然语言处理(NLP)的正式定义:是一个使用计算机科学.人工智能(AI)和形式语言学概念来分析自然语言的研究领域.不太正式的定义表明:它是一组工具,用于从自然语言源(如web页面和文本文档)获取 ...
- go-zero 是如何实现令牌桶限流的?
原文链接: 上一篇文章介绍了 如何实现计数器限流?主要有两种实现方式,分别是固定窗口和滑动窗口,并且分析了 go-zero 采用固定窗口方式实现的源码. 但是采用固定窗口实现的限流器会有两个问题: 会 ...