[转帖]Clickhouse单机及集群部署详解
https://www.cnblogs.com/ya-qiang/p/13540016.html
一、ClickHouse简介
ClickHouse是近年来备受关注的开源列式数据库,主要用于数据分析(OLAP)领域。目前国内社区火热,各个大厂纷纷跟进大规模使用:
- 今日头条 内部用ClickHouse来做用户行为分析,内部一共几千个ClickHouse节点,单集群最大1200节点,总数据量几十PB,日增原始数据300TB左右。
- 腾讯内部用ClickHouse做游戏数据分析,并且为之建立了一整套监控运维体系。
- 携程内部从18年7月份开始接入试用,目前80%的业务都跑在ClickHouse上。每天数据增量十多亿,近百万次查询请求。
- 快手内部也在使用ClickHouse,存储总量大约10PB, 每天新增200TB, 90%查询小于3S。
在国外,Yandex内部有数百节点用于做用户点击行为分析,CloudFlare、Spotify等头部公司也在使用。
二、ClickHouse指定版本单机安装与配置
1、查看cpu是否支持sse4
|
1
|
grep -q sse4_2 /proc/cpuinfo && echo "SSE 4.2 supported" || echo "SSE 4.2 not supported" |
2、下载RPM离线安装包
(1)在线下载很慢,可以先下载离线rpm安装包,推荐到https://packagecloud.io/Altinity/clickhouse/下载对应的版本号。
(2)在线下载RPM安装包
sudo wget --content-disposition https://packagecloud.io/Altinity/clickhouse/packages/el/7/clickhouse-client-19.17.4.11-1.el7.x86_64.rpm/download.rpm
sudo wget --content-disposition https://packagecloud.io/Altinity/clickhouse/packages/el/7/clickhouse-server-common-19.17.4.11-1.el7.x86_64.rpm/download.rpm
sudo wget --content-disposition https://packagecloud.io/Altinity/clickhouse/packages/el/7/clickhouse-common-static-19.17.4.11-1.el7.x86_64.rpm/download.rpm
sudo wget --content-disposition https://packagecloud.io/Altinity/clickhouse/packages/el/7/clickhouse-server-19.17.4.11-1.el7.x86_64.rpm/download.rpm
sudo wget --content-disposition https://packagecloud.io/Altinity/clickhouse/packages/el/7/clickhouse-test-19.17.4.11-1.el7.x86_64.rpm/download.rpm
sudo wget --content-disposition https://packagecloud.io/Altinity/clickhouse/packages/el/7/clickhouse-debuginfo-19.17.4.11-1.el7.x86_64.rpm/download.rpm
后面两个RPM安装包可以不用下载
3、使用rpm -ivh ./*.rpm 安装clickhouse,安装中可能会有依赖没有下载导致报错,安装完依赖继续安装,可以使用rpm -e *.rpm 移除已安装的安装包

/etc/clickhouse-server clickhouse服务的配置文件目录,包括:config.xml和users.xml
/etc/clickhouse-client clickhouse客户端的配置文件目录,里面只有一个config.xml并且默认为空
/var/lib/clickhouse clickhouse默认数据目录
/var/log/clickhouse-server clickhouse默认日志目录
/etc/init.d/clickhouse-server clickhouse启动shell脚本,用来方便启动服务的.
/etc/security/limits.d/clickhouse.conf 最大文件打开数的配置,这个在config.xml也可以配置
/etc/cron.d/clickhouse-server clickhouse定时任务配置,默认没有任务,但是如果文件不存在启动会报错.
/usr/bin clickhouse编译好的可执行文件目录,主要有下面几个:
clickhouse clickhouse主程序可执行文件
clickhouse-compressor
clickhouse-client 是一个软链指向clickhouse,主要是客户端连接操作使用
clickhouse-server 是一个软链接指向clickhouse,主要是服务操作使用
4、配置clickhouse配置文件
主要需要配置的文件是/etc/clickhouse-server/config.xml、/etc/clickhouse-server/users.xml
(1)config.xml配置
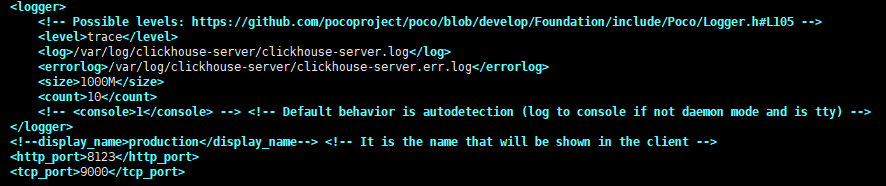
这部分配置clickhouse-server的日志存放目录以及http和tcp请求端口号

配置clickhouse可以被远程ip访问
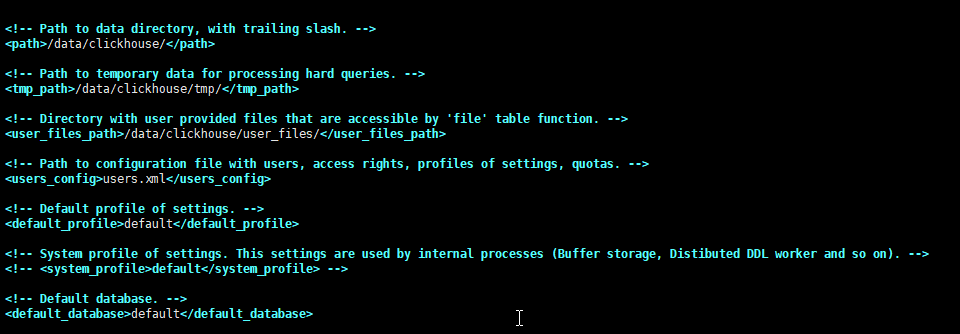
这一部分是分别配置clickhouse的数据存放目录、临时文件存放目录、用户文件路径
(2)users.xml
<users></users>里面默认会有一个用户名为default的用户,密码默认为空,可以配置<password></password>设置用户密码
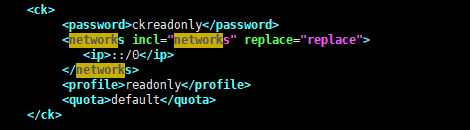
新增加一个用户名为ck,密码为ckreadonly的用户,profile属性为readonly表示该用户是只读用户
三、clickhosue单机在线安装最新版本clickhouse
sudo rpm --import https://repo.clickhouse.tech/CLICKHOUSE-KEY.GPG
sudo yum-config-manager --add-repo https://repo.clickhouse.tech/rpm/clickhouse.repo
sudo yum install clickhouse-server clickhouse-client
sudo /etc/init.d/clickhouse-server start
clickhouse-client
按照上面步骤即可
四、ClickHouse单机版连接与操作
(1)启动clickhouse服务
service clickhouse-server start/service clickhouse-server stop
(2)启动clickhouse-client连接操作clickhouse
clickhouse-client -h 172.16.2.161 -u default – password default
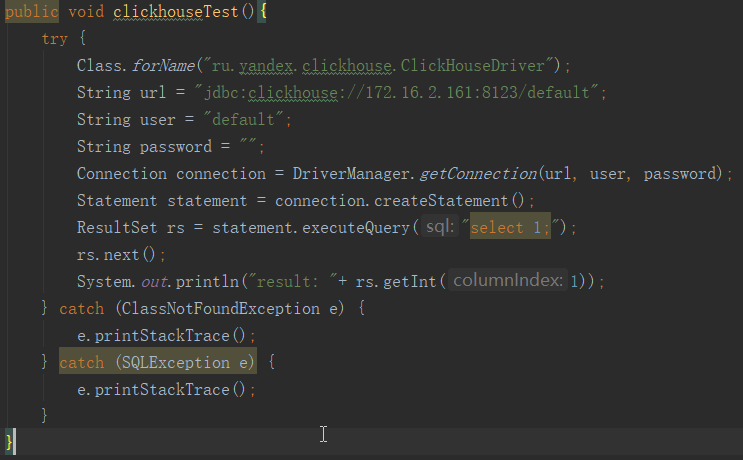
(3)使用java操作clickhouse的jdbc驱动来访问clickhouse
五、ClickHouse集群部署
1、上面的clickhouse单机版安装比较容易,上面是从https://packagecloud.io/Altinity/clickhouse/下载的el7安装包,可能由于时间原因现在访问没有centos6的rpm包,所以在centos6上安装clickhouse的需要el6的rpm的安装包,可以从http://repo.yandex.ru/clickhouse/rpm/stable/x86_64/这里下载指定版本的clickhouse rpm64位包,主要是从该仓库中下载以下安装包:
clickhouse-client-20.6.3.28-2.noarch.rpm
clickhouse-common-static-20.6.3.28-2.x86_64.rpm
clickhouse-server-20.6.3.28-2.noarch.rpm
下载完毕后按照上面步骤二进行各个服务器节点的单机版本安装,对于配置config.xml和users.xml文件在一个节点配置后同步到其他集群节点中即可。
2、部署zookeeper集群,在这里就不说了
3、单机版和集群版的区别就是多了一个配置clickhouse分片和副本规则,创建配置文件/etc/metrika.xml,注意要在/etc目录下面
<?xml version="1.0" encoding="utf-8"?>
<yandex>
<!-- 集群配置 -->
<clickhouse_remote_servers>
<perftest_3shards_1replicas>
<!-- 数据分片1 -->
<shard>
<internal_replication>true</internal_replication>
<replica>
<host>172.16.2.161</host>
<port>9003</port>
<user>default</user>
<password>default</password>
</replica>
</shard>
<!-- 数据分片2 -->
<shard>
<internal_replication>true</internal_replication>
<replica>
<host>172.16.2.165</host>
<port>9003</port>
<user>default</user>
<password>default</password>
</replica>
</shard>
<!-- 数据分片3 -->
<shard>
<internal_replication>true</internal_replication>
<replica>
<host>172.16.2.241</host>
<port>9003</port>
<user>default</user>
<password>default</password>
</replica>
</shard>
</perftest_3shards_1replicas>
</clickhouse_remote_servers> <zookeeper-servers>
<node index="1">
<host>172.16.2.232</host>
<port>2181</port>
</node>
<node index="2">
<host>172.16.2.233</host>
<port>2181</port>
</node>
<node index="3">
<host>172.16.2.234</host>
<port>2181</port>
</node>
<node index="4">
<host>172.16.2.235</host>
<port>2181</port>
</node>
<node index="5">
<host>172.16.2.236</host>
<port>2181</port>
</node>
</zookeeper-servers>
<macros>
<shard>01</shard>
<replica>172.16.2.161</replica>
</macros> <networks>
<ip>::/0</ip>
</networks>
<!-- 数据压缩算法 -->
<clickhouse_compression>
<case>
<min_part_size>10000000000</min_part_size>
<min_part_size_ratio>0.01</min_part_size_ratio>
<method>lz4</method>
</case>
</clickhouse_compression>
</yandex>
配置文件中配置的3分片1副本模式,配置完毕后同步到其他节点即可。
4、按照步骤四里的方式在每一台集群节点上启动clickhouse服务并进入clickhouse-client客户端连接
5、测试集群是否安装成功,使用select * from system.clusters

出现这个说明安装成功,clickhouse tcp端口默认是9000我这因为端口占用所以修改成了9003端口了。
create database jikewang on cluster perftest_3shards_1replicas;
CREATE TABLE log_test ON CLUSTER perftest_3shards_1replicas
(
`ts` DateTime,
`uid` String,
`biz` String
)
ENGINE = ReplicatedMergeTree('/clickhouse/tables/{shard}/log_test', '{replica}')
PARTITION BY toYYYYMMDD(ts)
ORDER BY ts;
以上代码为测试使用
六、集群版clickhouse通过jdbc连接操作
[转帖]Clickhouse单机及集群部署详解的更多相关文章
- Clickhouse单机及集群部署详解
一.ClickHouse简介 ClickHouse是近年来备受关注的开源列式数据库,主要用于数据分析(OLAP)领域.目前国内社区火热,各个大厂纷纷跟进大规模使用: 今日头条 内部用ClickHous ...
- kafka的原理及集群部署详解
kafka原理详解 消息队列概述 消息队列分类 点对点 组成:消息队列(Queue).发送者(Sender).接收者(Receiver) 特点:一个生产者生产的消息只能被一个接受者接收,消息一旦被消费 ...
- [转帖]Application Request Route实现IIS Server Farms集群负载详解
Application Request Route实现IIS Server Farms集群负载详解 https://www.cnblogs.com/knowledgesea/p/5099893.ht ...
- Solr系列二:solr-部署详解(solr两种部署模式介绍、独立服务器模式详解、SolrCloud分布式集群模式详解)
一.solr两种部署模式介绍 Standalone Server 独立服务器模式:适用于数据规模不大的场景 SolrCloud 分布式集群模式:适用于数据规模大,高可靠.高可用.高并发的场景 二.独 ...
- Apache + Tomcat集群配置详解 (1)
一.软件准备 Apache 2.2 : http://httpd.apache.org/download.cgi,下载msi安装程序,选择no ssl版本 Tomcat 6.0 : http://to ...
- MySQL集群搭建详解
概述 MySQL Cluster 是MySQL 适合于分布式计算环境的高实用.可拓展.高性能.高冗余版本,其研发设计的初衷就是要满足许多行业里的最严酷应用要求,这些应用中经常要求数据库运行的可靠性要达 ...
- 关于Linux单机、集群部署FastDFS分布式文件系统的步骤。
集群部署:2台tarcker服务器,2台storage服务器. 192.168.201.86 ---------(trackerd+storage+nginx) 192.168.201.87 ...
- Apache ZooKeeper 单机、集群部署文档
简介: Apache ZooKeeper 是一个分布式应用的高性能协调服务,功能包括:配置维护.统一命名.状态同步.集群管理.仲裁选举等. 下载地址:http://apache.fayea.com/z ...
- Centos7 zookeeper单机/集群安装详解和开机自启
ZooKeeper是一个分布式的,开放源码的分布式应用程序协调服务,是Google的Chubby一个开源的实现,是Hadoop和Hbase的重要组件.它是一个为分布式应用提供一致性服务的软件,提供的功 ...
- Storm集群安装详解
storm有两种操作模式: 本地模式和远程模式. 本地模式:你可以在你的本地机器上开发测试你的topology, 一切都在你的本地机器上模拟出来; 远端模式:你提交的topology会在一个集群的机器 ...
随机推荐
- Go 语言为什么不支持并发读写 map?
大家好,我是 frank ,「 Golang 语言开发栈」公众号作者. 01 介绍 在 Go 语言项目开发中,我们经常会使用哈希表 map,它的时间复杂度是 O(1),Go 语言中的 map 使用开放 ...
- CodeForces 1030E Vasya and Good Sequences 位运算 思维
原题链接 题意 目前我们有一个长为n的序列,我们可以对其中的每一个数进行任意的二进制重排(改变其二进制表示结果的排列),问我们进行若干次操作后得到的序列,最多能有多少对 \(l, r\) 使得 \([ ...
- GaussDB(for MySQL) RegionlessDB发布:全球数据库技术
本文分享自华为云社区<GaussDB(for MySQL) RegionlessDB发布:全球数据库技术>,作者: GaussDB 数据库. 1.技术背景 对于一些典型行业,如跨境电商和大 ...
- 执行计划缓存,Prepared Statement性能跃升的秘密
摘要:一起看一下GaussDB(for MySQL)是如何对执行计划进行缓存并加速Prepared Statement性能的. 本文分享自华为云社区<执行计划缓存,Prepared Statem ...
- 如何在跨平台的环境中创建可以跨平台的后台服务,它就是 Worker Service。
一.简介 最近,有一个项目要使用 Windows 服务,来做为一个软件项目的载体.我想了想,都已经到了跨平台的时代了,会不会有替换 Windows 服务的技术出现呢?于是,在网络上疯狂的搜索了一番,真 ...
- Nginx log 日志文件较大,按日期生成 实现日志的切割
Nginx日志不处理的话,会一直追加,文件会变得很大,所以理想做法是按天对 Nginx日志进行分割 方法1:给日志文件名加上日期 推荐 log_format access-upstream '$tim ...
- SpringBoot Docker 发布
本文是手动模式,可以移步 Intellij IDEA 集成 Docker 发布 使用 Intellij 集成Docker 发布,比较方便 pom 文件 <groupId>com.vipso ...
- VS2019 快速实现 C# 连接 MySQL 数据库并实现基本操作代码
一.工具: Visual Studio 2019 MySQL 数据库 二.添加动态链接: Visual Studio 中选择项目-> 管理NuGet程序包(N) -> 然后在浏览里面搜索 ...
- 技术文档 | 免下载、0配置、多任务并发,在Docker Image中使用OpenSCA
想跳过下载步骤快速使用OpenSCA检测代码风险?想实现多个项目并发扫描? 在Docker Image中使用OpenSCA即可轻松实现.一起来look look 目的 方便用户使用最新版本的 Open ...
- 成都站|阿里云 Serverless 技术实战营邀你来玩!
活动简介 "Serverless 技术实战与创新沙龙 " 是一场以 Serverless 为主题的开发者活动,活动受众以关注Serverless 技术的开发者.企业决策人.云原生领 ...