[转帖]TIKV扩容之刨坑填坑
01
背景
某tidb集群收到告警,TIKV 节点磁盘使用率85%以上,联系业务无法快速删除数据,于是想到扩容TIKV 节点,原先TIKV 节点机器都是6TB的硬盘,目前只有3TB的机器可扩,也担心region 均衡后会不会打满3TB的盘,PD 调度策略来看应该是会根据不同存储机器的资源配置和使用情况进行打分,region balance 优先根据leader score 和region score 往分低的机器均衡数据来让不同节点机器的数据处于一种均衡状态,但是PD 有时候也不是智能的,会出现偏差,导致某个节点磁盘打满也未可知,这时候就需要人为干预了,我就遇到了在不同存储节点扩容tikv导致小存储容量节点磁盘差点打满的情况,所以一般建议优先相同存储容量的盘进行扩容。
02
集群环境
Tidb:5节点
PD:3节点
TIKV:10节点 6TB 硬盘
集群总量:45TB ,每个TIKV 4.5TB
03
实施分析过程
由于业务不断增长,整个集群使用率接近80%,业务无法删除数据,于是决定扩容tikv节点,没有6TB的大盘机器,所以扩容了1个3TB的TIKV节点,可以考虑调整 PD 调度参数 region-schedule-limit 以及 leader-schedule-limit 来控制调度速度,调大可加快均衡速度,但是对业务会产生一定影响,过小速度会慢点,不着急的话默认值就行。
扩容TIKV
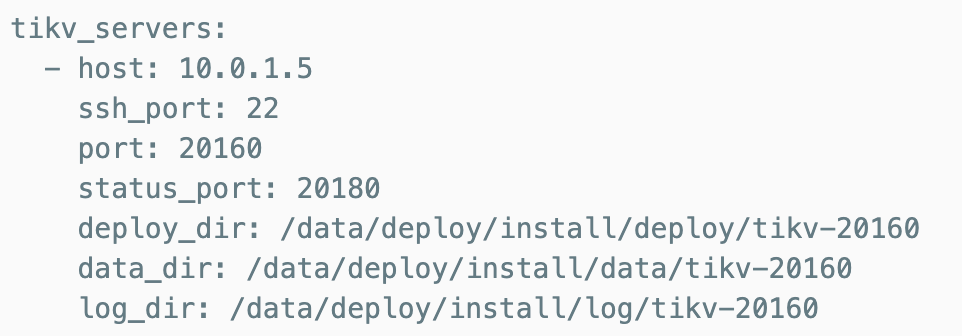
tiup cluster scale-out <cluster-name> scale-out.yaml
扩容完成后,经过一天一夜,收到告警,新扩容的机器磁盘已经90%,并基本维持在这个量级,比较纳闷,难道是错怪PD了,可能PD有参数限制智能使用磁盘的90%就不往该节点均衡数据了。
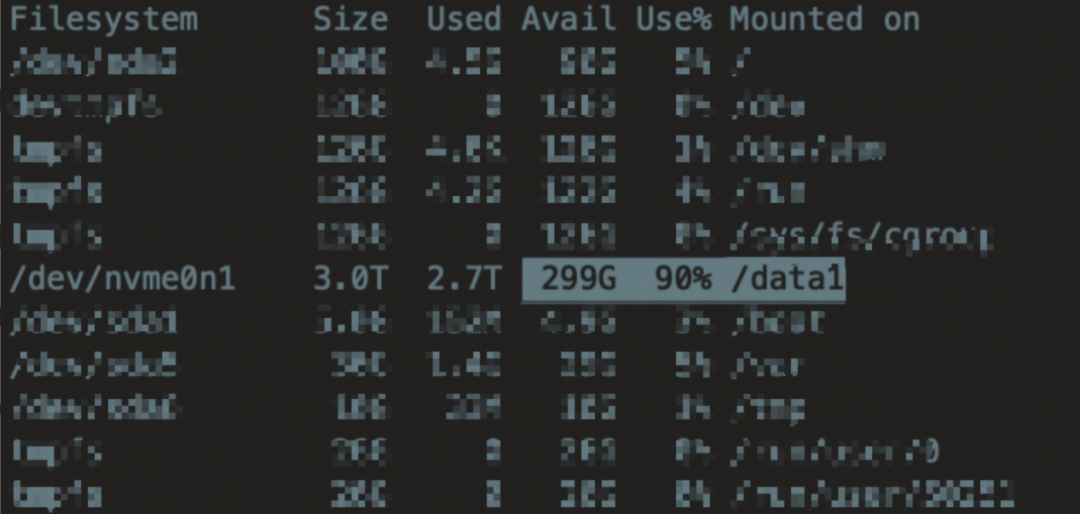
查阅官方文档发现下面参数low-space-ratio,确实是可以设置每个节点tikv的磁盘最大使用率。
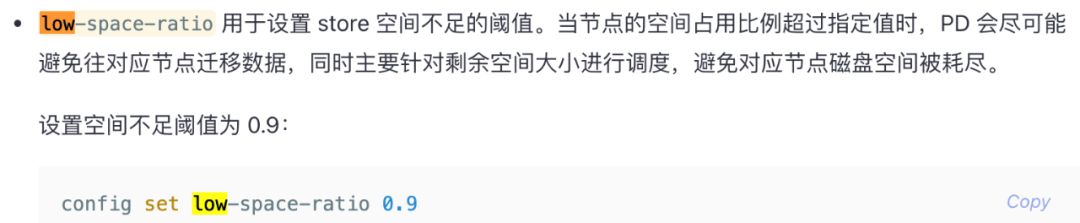
确实是错怪PD了,以为它调度策略出现了偏差,回过头来看这个参数不能针对某个节点进行设置,生效的是所有节点,因为该集群6TB盘使用率在80%左右,所以也不好设置低于80%的参数,对我来说意义不大了,那就得需要寻找其它策略去均衡迁移数据了。
查看PD 监控

Store Region score 差不多是6TB 盘的一半左右,那三个163w的是相隔1天扩容的3个节点,看的出score 更低。
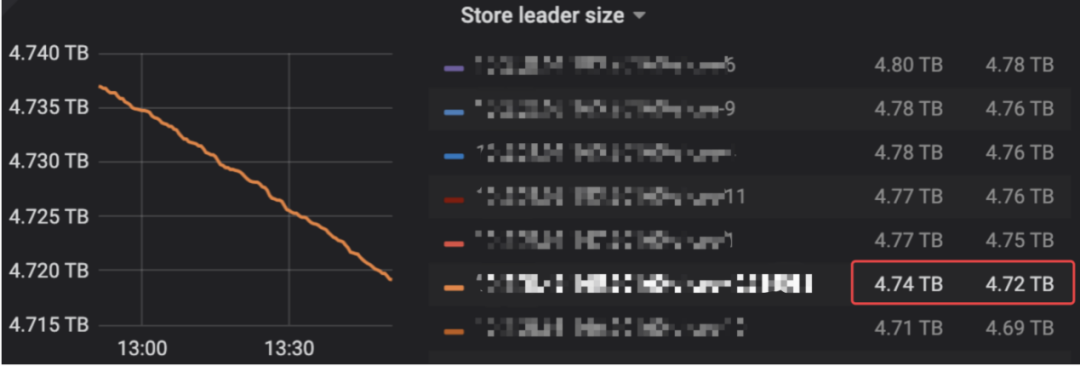
这里leader size 显示大小和原先6TB 盘接近,显示超过本身3TB 盘大小。
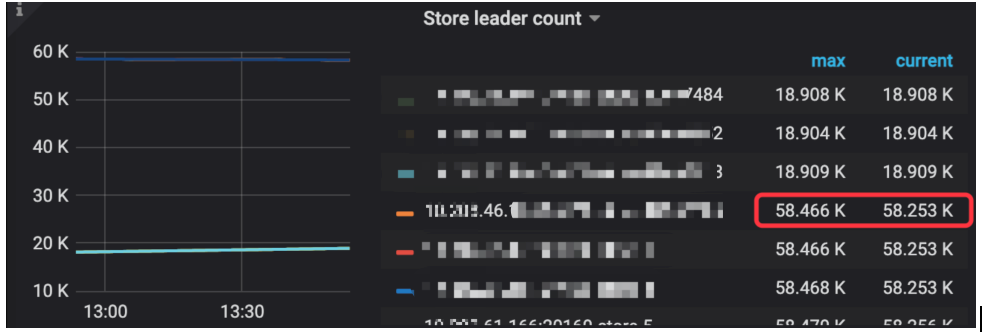
Store leader count 显示大小和原先存在的6TB TIKV 节点一样大。

显示Store Region size 是6.89TB ,实际硬盘使用在2.7TB 左右,为啥差距这么大呢?
监控指标store region zize 和 leader region size 大小取值的计算方式,由于多版本和 TiKV会压缩数据导致实际落盘存储大小和监控显示指标差距比较大,当超过500GB 数据采用zstd高压缩方式,压缩比大约3倍。
摘录 tidb-in-action的一段 :

至此就明白了上面监控数值显示大小和实际硬盘存储大小区别了,数据写入首先写入到rocksdb,然后由rocksdb进行落盘操作的。
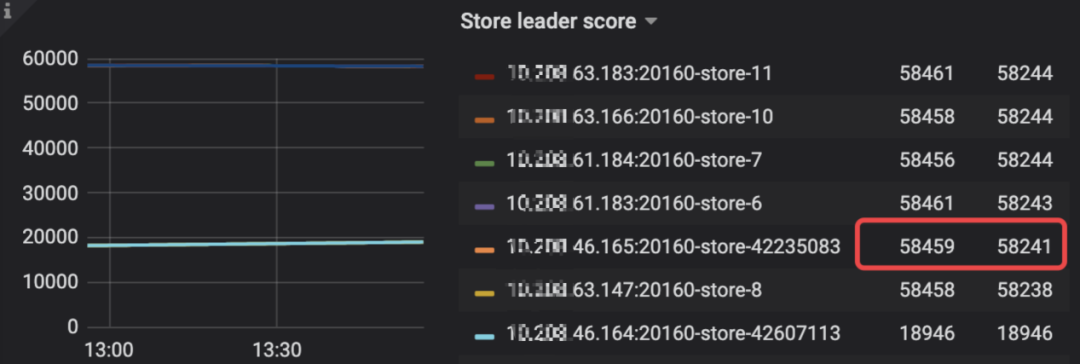
Store leader score 分数已和原先的Tikv 节点近似,说明store leader 已均衡,但是region score 还偏低,还会持续有其它节点数据balance 过来,于是开始调整PD region_weight,leader_weight 参数来控制每个tikv 节点的分数,比如分别调整为0.5。
pd-ctl -i-u http://ip:2379
》store
》
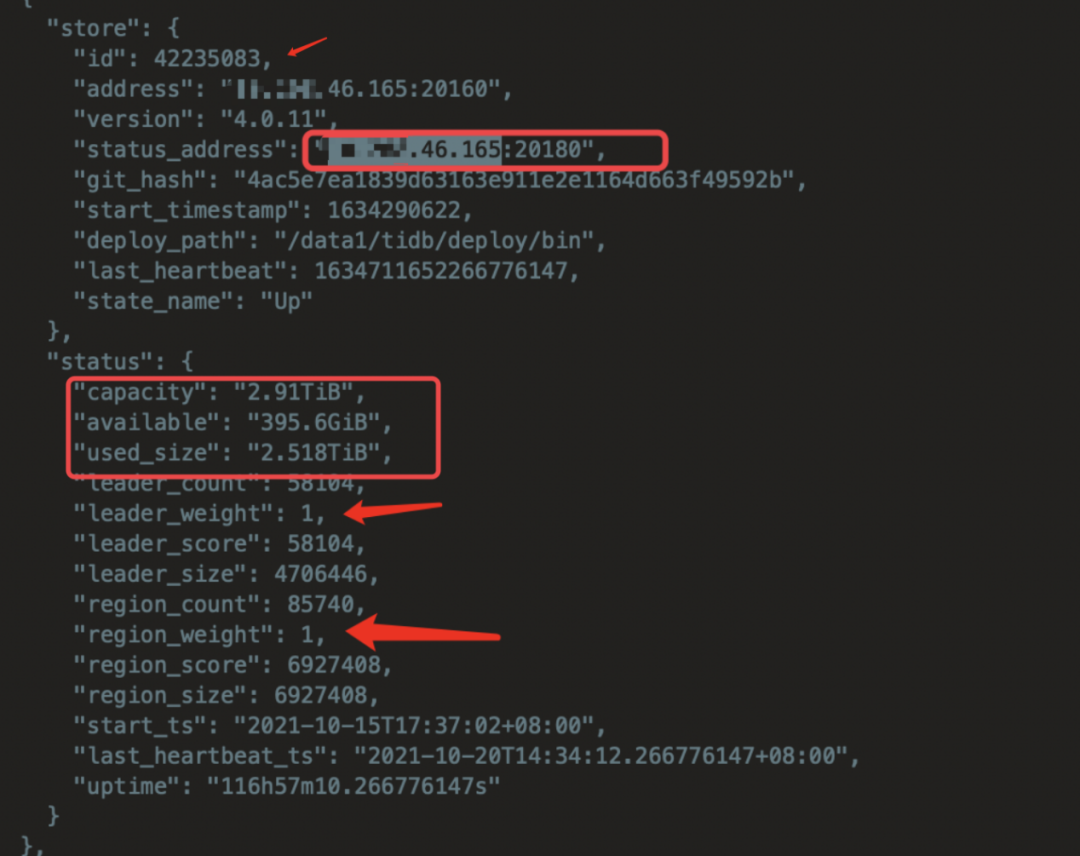
》store weight 42607484 0.5 0.5

官方文档也给出说明了,因为新扩容磁盘容量大约为旧TIKV 节点的一半,所以我暂时通过调整权重来让新扩容的节点来存储旧集群数据量的一半。

调整后过12小时后再看,发现磁盘使用率已经降低到70%左右,说明参数起作用了,再逐步把region 转移到其它机器上。

04
总结
日常运维中还需要加强对Tidb 各个组件内部调度原理的学习,仔细研读官方文档,不然出事难免慌张,不知所措,感谢PingCap提供asktug 这个平台让我们可以搜索到很多实践运维案例,少走很多弯路。
[转帖]TIKV扩容之刨坑填坑的更多相关文章
- Cloudera Manager 5.9 和 CDH 5.9 离线安装指南及个人采坑填坑记
公司的CDH早就装好了,一直想自己装一个玩玩,最近组了台电脑,笔记本就淘汰下来了,加上之前的,一共3台,就在X宝上买了CPU和内存升级了下笔记本,就自己组了个集群. 话说,好想去捡垃圾,捡台8核16线 ...
- Phoenix踩坑填坑记录
Phoenix踩坑填坑记录 Phoenix建表语句 如何添加二级索引 判断某表是否存在 判断索引是否存在 Date类型日期,条件判断 杂项 记录Phoenix开发过程中的填坑记录. 部分原文地址:ph ...
- Spark踩坑填坑-聚合函数-序列化异常
Spark踩坑填坑-聚合函数-序列化异常 一.Spark聚合函数特殊场景 二.spark sql group by 三.Spark Caused by: java.io.NotSerializable ...
- Kafka踩坑填坑记录
Kafka踩坑填坑记录 一.kafka通过Java客户端,消费者无法接收消息,生产者发送失败消息 二. 一.kafka通过Java客户端,消费者无法接收消息,生产者发送失败消息 在虚拟机上,搭建了3台 ...
- Linux踩坑填坑记录
Linux踩坑填坑记录 yum安装失败[Errno 14] PYCURL ERROR 6 - "Couldn't resolve host 'mirrors.aliyun.com'" ...
- 自制Amiibo 踩坑/填坑 指南
去年买了台老版NS,后来得知有Amiibo这种东西的存在,但是学校附近都买不到. 再后来网上看见有人在X宝卖自制卡片,就寻思着是否能自己 DIY一套,于是掉坑里. 要想使用自制Amiibo,一共要做两 ...
- FreeSWITCH 安装配置的 各种坑, 填坑
个人安装环境: OS:CentOS6.7 64位 FreeSWITCH Ver:1.6.17 一. 编译出错 安装 之前, 最好 先安装 这几个东西(如果有, 请忽略): yasm (有nasm的话 ...
- IdentityServer4结合AspNetCore.Identity实现登录认证踩坑填坑记录
也可以自定义实现,不使用IdentityServer4.AspNetIdentity这个包,当然还要实现其他接口IResourceOwnerPasswordValidator. IProfileSer ...
- React Native填坑之旅--与Native通信之iOS篇
终于开始新一篇的填坑之旅了.RN厉害的一个地方就是RN可以和Native组件通信.这个Native组件包括native的库和自定义视图,我们今天主要设计的内容是native库方面的只是.自定义视图的使 ...
- https填坑之旅
Boss说,我们买了个权威证书,不如做全站式的https吧,让用户打开主页就能看到受信任的绿标.于是我们就开始了填坑之旅. [只上主域好不好?] 不好...console会报出一大堆warning因为 ...
随机推荐
- 斯坦福 UE4 C++ ActionRoguelike游戏实例教程 14. 使用GameplayTag实现防守反击技能
斯坦福课程 UE4 C++ ActionRoguelike游戏实例教程 0.绪论 概述 本篇文章对应Lecture 17 - GameplayTags, 70节.本文将会结合前几节课使用的能力系统和G ...
- 26、Flutter中命名路由
Flutter 中的命名路由 main.dart中配置路由 void main() { runApp(MaterialApp( theme: ThemeData( appBarTheme: const ...
- maven系列:POM文件总体配置说明
<project xmlns="http://maven.apache.org/POM/4.0.0" xmlns:xsi="http://www.w3.org/20 ...
- Git使用经验总结1
目录 1. 概述 2. 界面化工具 3. 远端覆盖本地 4. 设置代理 1. 概述 就不去介绍一些Git最常规的命令了,这些命令一般的教程都有,这里更多的总结自己的一些使用经验.当然作为初学者,常规的 ...
- C# 将Excel转为OFD、UOS
本文以C#及VB.NET代码为例展示如何将Excel工作簿转换为OFD和UOS格式.通过workbook.LoadFromFile(string fileName)方法加载Excel源文档后,然后调用 ...
- 火山引擎DataLeap一站式数据治理解决方案及平台架构
更多技术交流.求职机会,欢迎关注字节跳动数据平台微信公众号,回复[1]进入官方交流群 在字节跳动内部,DataLeap数据平台数据治理团队致力于建立一站式.全链路的数据治理解决方案平台. 数据治理的概 ...
- 如何构建面向海量数据、高实时要求的企业级OLAP数据引擎?
在字节跳动各产品线飞速成长的过程中,对数据分析能力也提出了更高的要求,现有的主流数据分析产品都没办法完全满足业务要求.因此,字节跳动在ClickHouse引擎基础上重构了技术架构,实现了云原生环境的部 ...
- 性能提升-如何设置Windows操作系统TIME_WAIT状态的TCP连接快速回收时间?
大规模Windows环境下,采用Nginx反向代理服务后,操作系统会产生较多TIME_WAIT的TCP(Transmission Control Protocol)连接,操作系统默认TIME_WAIT ...
- 【Git】git多分支开发 git远程仓库 ssh链接远程仓库 协同开发 冲突解决 线上分支合并 pycharm操作git 远程仓库回滚
目录 昨日回顾 1 git多分支开发 分支操作 合并分支 2 git远程仓库 2.1 把路飞项目传到远程仓库(非空的) 3 ssh链接远程仓库,协同开发 4 协同开发 5 冲突解决 5.1 多人同一分 ...
- Windows下的Linux子系统(WSL)
什么是WSLWSL:Windows subsystem for Linux,是用于Windows上的Linux的子系统作用很简单,可以在Windows系统中获取Linux系统环境,并完全直连计算机硬件 ...