python+pytest接口自动化(15)-日志管理模块loguru简介
python自带日志管理模块logging,使用时可进行模块化配置,详细可参考博文Python日志采集(详细)。
但logging配置起来比较繁琐,且在多进行多线程等场景下使用时,如果不经过特殊处理,则容易出现日志丢失或记录错乱的情况。
python中有一个用起来非常简便的第三方日志管理模块--loguru,不仅可以避免logging的繁琐配置,而且可以很简单地避免在logging中多进程多线程记录日志时出现的问题,甚至还可以自定义控制台输出的日志颜色。
接下来我们来学习怎么使用loguru模块进行日志管理。
安装
第三方模块,需要先安装,安装命令如下:
pip install loguru
简单示例
简单使用示例如下:
from loguru import logger
# 日志写入文件则需使用add()方法,"../log/test.log"即日志文件路径,可自定义。
# 写入文件的日志里有中文的话,需要加上encoding="utf-8",否则会显示乱码。
logger.add("../log/test.log", encoding="utf-8", rotation="500MB",
enqueue=True, retention="7 days")
# 打印不同类型的日志
logger.debug("这是一段debug级别日志")
logger.info("这是一段info级别日志")
logger.warning("这是一段warning级别日志")
logger.critical("这是一段critical级别日志")
上面的示例代码运行之后,会在控制台打印如下日志:

同时也会在 "../log/test.log" 路径中写入日志,如下:

由以上结果可以看出:
loguru中直接提供了一个日志记录对象logger,拿来即用;
loguru默认的输出格式为:时间 | 级别 | 模块名 | 行号 | 日志信息;
不同级别的日志在控制台显示颜色不一样。
当然,在实际项目中我们还需要日志管理器有更丰富的配置,loguru中的add()方法便具有强大的配置功能,接下来介绍add()方法提供的常用配置功能。
add()常用参数说明
loguru模块源码中add()方法的参数如下:
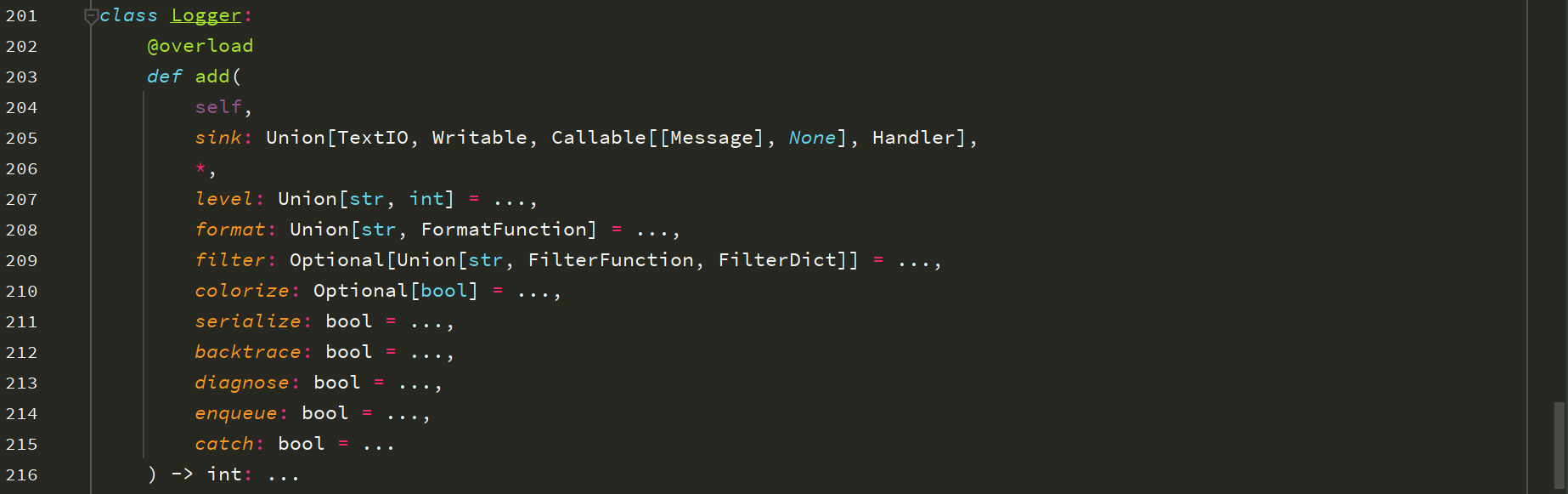
sink(官方文档简单翻译如下):
可以传入类
file对象,如sys.stderr或者open('test.log', 'w')。可以传入文件路径
str或pathlib,如示例代码中的写入日志文件路径。路径可以使用一些附加参数对其进行参数化,如test_{time}.log,{time}即时间参数,创建文件时文件名称中会加入时间。可以传入像
lambda这样的可调用函数的简单函数,如lambda msg:print(msg)。这允许完全由用户偏好和需求定义日志记录过程。还可以是使用
async def语句定义的异步协程函数。该函数返回的协程对象将使用loop.create_task()添加到事件循环中。在使用complete()结束循环之前,应该等待这些任务。也支持传入logging模块的
Handler,如FileHandler、StreamHandler等,Loguru记录会自动转换为日志模块预期的结构。
level:发送到sink的日志消息的最低日志级别,即输出的最低日志级别。
format:定义日志的输出格式。
filter:过滤日志。
colorize:终端日志输出的颜色。
serializer:bool值,输出日志时是否先格式化成JSON数据格式。
backtrace:bool值,是否进行异常跟踪(即backtrace信息记录)。
diagnose:bool值,异常跟踪是否应显示变量值以简化调试。在生产中应将其设置为False,以避免泄漏敏感数据。
enqueue:bool值,日志消息输出之前是否先通过多进程安全队列,多进程多线程运行写入日志时需用到,避免日志记录丢失或混乱。
catch:bool值,是否自动捕获接收器处理日志消息时发生的错误。如果为True,则在sys上显示异常消息。
继续看loguru模块源码,如下:
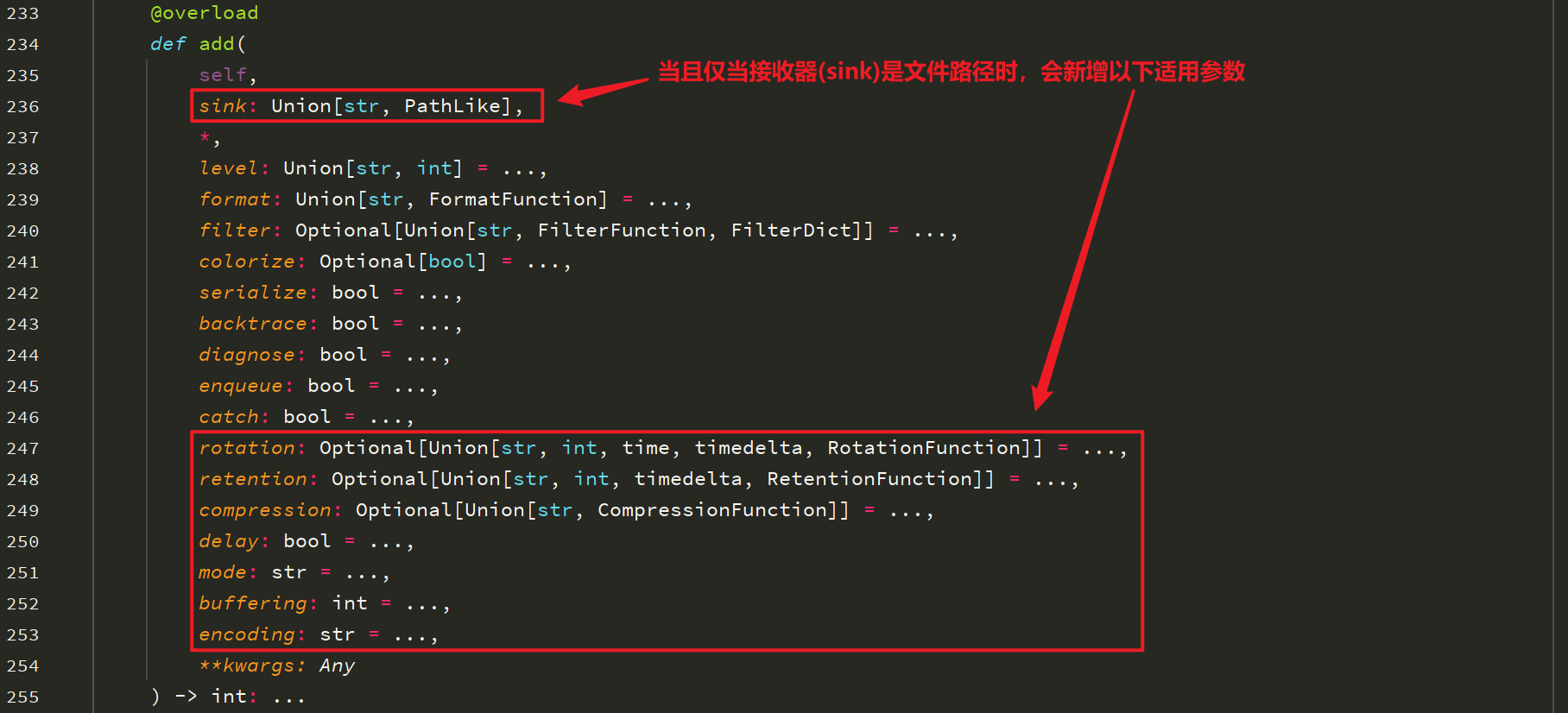
即我们需要将日志写入指定的文件时,可以使用截图中新增的参数。常用的参数说明如下:
rotation:指定日志文件记录条件,日志输出太多需要隔一段时间写入新文件时适用。
# rotation指定日志文件最大为500MB,超过则新建文件记录日志
logger.add("../log/test.log", rotation="500MB")
# 指定每天12:00新建日志记录文件:rotation="12:00"
# 指定每隔10天新建日志记录文件:rotation="10 days"
# 指定每隔一个星期新建日志记录文件:rotation="1 week"
# 指定每隔两个月新建日志记录文件:rotation="2 months"
retention:指定日志保留时长,会清除超过指定时长的数据。
# rotation指定日志保留时长,如"1 week", "3 days", "2 months"
logger.add("../log/test.log", retention="10 days")
compression:配置文件压缩格式。
# rotation指定日志保留时长,如"gz", "bz2", "xz", "lzma", "tar", "tar.gz", "tar.bz2", "tar.xz", "zip"
logger.add("../log/test.log", compression="zip")
encoding:指定写入文件时的编码格式,这在示例代码中已说明。
使用
接下来,我们使用常用的参数来组合定义日志记录方式。
from loguru import logger
import sys
# format建议直接使用默认的格式
logger.add("../log/test_{time}.log", level="INFO", encoding="utf-8", enqueue=True, rotation="500MB", retention="1 week")
# 当然也可以自定义format,如下示例
# logger.add("../log/test_{time}.log",
format="{time:YYYY-MM-DD HH:mm:ss} | {level} | {name} | {line} | {message}", encoding="utf-8", enqueue=True, rotation="500MB", retention="1 week")
# 打印不同类型的日志
logger.debug("这是一段debug级别日志")
logger.info("这是一段info级别日志")
logger.warning("这是一段warning级别日志")
logger.critical("这是一段critical级别日志")
参数说明:
sink="../log/test_{time}.log",即指定日志文件路径,且加入了{time},创建.log文件时名称会加上时间。level="INFO",写入文件时只会写入INFO及以上级别的日志 (需要大写),即INFO、WARNING、CRITICAL。encoding="utf-8",日志写入文件时指定编码格式为"utf-8",否则有中文的话会显示乱码。enqueue=True,支持多线程多进程执行时按照队列写入。rotation="500MB",日志文件最大为500MB,超过则新建。retention="1 week",日志保留一周,过后则清除。format没有指定即使用默认格式,建议直接使用默认的格式,见代码注释。
执行代码后,结果如下:

从结果中可以看出来,输出内容中模块部分显示的是如__main__:<module>:20的形式,而并不是我们想要看到的对应的模块名称,这是因为直接执运行了当前文件的文件,如果是其他模块调用执行便会显示对应的模块名称。
python+pytest接口自动化(15)-日志管理模块loguru简介的更多相关文章
- python+pytest接口自动化(16)-接口自动化项目中日志的使用 (使用loguru模块)
通过上篇文章日志管理模块loguru简介,我们已经知道了loguru日志记录模块的简单使用.在自动化测试项目中,一般都需要通过记录日志的方式来确定项目运行的状态及结果,以方便定位问题. 这篇文章我们使 ...
- python+pytest接口自动化(11)-测试函数、测试类/测试方法的封装
前言 在python+pytest 接口自动化系列中,我们之前的文章基本都没有将代码进行封装,但实际编写自动化测试脚本中,我们都需要将测试代码进行封装,才能被测试框架识别执行. 例如单个接口的请求代码 ...
- python+pytest接口自动化(13)-token关联登录
在PC端登录公司的后台管理系统或在手机上登录某个APP时,经常会发现登录成功后,返回参数中会包含token,它的值为一段较长的字符串,而后续去请求的请求头中都需要带上这个token作为参数,否则就提示 ...
- python+pytest接口自动化(12)-自动化用例编写思路 (使用pytest编写一个测试脚本)
经过之前的学习铺垫,我们尝试着利用pytest框架编写一条接口自动化测试用例,来厘清接口自动化用例编写的思路. 我们在百度搜索天气查询,会出现如下图所示结果: 接下来,我们以该天气查询接口为例,编写接 ...
- python+pytest接口自动化(4)-requests发送get请求
python中用于请求http接口的有自带的urllib和第三方库requests,但 urllib 写法稍微有点繁琐,所以在进行接口自动化测试过程中,一般使用更为简洁且功能强大的 requests ...
- python+pytest接口自动化(6)-请求参数格式的确定
我们在做接口测试之前,先需要根据接口文档或抓包接口数据,搞清楚被测接口的详细内容,其中就包含请求参数的编码格式,从而使用对应的参数格式发送请求.例如某个接口规定的请求主体的编码方式为 applicat ...
- python+pytest接口自动化(9)-cookie绕过登录(保持登录状态)
在编写接口自动化测试用例或其他脚本的过程中,经常会遇到需要绕过用户名/密码或验证码登录,去请求接口的情况,一是因为有时验证码会比较复杂,比如有些图形验证码,难以通过接口的方式去处理:再者,每次请求接口 ...
- python+pytest接口自动化(5)-发送post请求
简介 在HTTP协议中,与get请求把请求参数直接放在url中不同,post请求的请求数据需通过消息主体(request body)中传递. 且协议中并没有规定post请求的请求数据必须使用什么样的编 ...
- python pytest接口自动化框架搭建(一)
1.首先安装pytest pip install pytest 2.编写单测用例 在pytest框架中,有如下约束: 所有的单测文件名都需要满足test_*.py格式或*_test.py格式. 在单测 ...
随机推荐
- Springmvc入门基础(四) ---参数绑定
1.默认支持的参数类型 处理器形参中添加如下类型的参数处理适配器会默认识别并进行赋值. 除了ModelAndView以外,还可以使用Model来向页面传递数据, Model是一个接口,在参数里直接声明 ...
- RocketMQ实现分布式事务
相关文章:http://www.uml.org.cn/zjjs/201810091.asp(深入理解分布式事务,高并发下分布式事务的解决方案) 三种分布式事务: 1.基于XA协议的两阶段提交 2.消息 ...
- 转:为什么数据库选B-tree或B+tree而不是二叉树作为索引结构
转载至:https://blog.csdn.net/sinat_27602945/article/details/80118362 B-Tree就是我们常说的B树,一定不要读成B减树,否则就很丢人了. ...
- 什么是 Callable 和 Future?
Callable 接口类似于 Runnable,从名字就可以看出来了,但是 Runnable 不会返 回结果,并且无法抛出返回结果的异常,而 Callable 功能更强大一些,被线程执 行后,可以返回 ...
- 解释 Java 堆空间及 GC?
当通过 Java 命令启动 Java 进程的时候,会为它分配内存.内存的一部分用于 创建堆空间,当程序中创建对象的时候,就从对空间中分配内存.GC 是 JVM 内 部的一个进程,回收无效对象的内存用于 ...
- IOC 的优点是什么?
IOC 或 依赖注入把应用的代码量降到最低.它使应用容易测试,单元测试不再需 要单例和 JNDI 查找机制.最小的代价和最小的侵入性使松散耦合得以实现.IOC 容器支持加载服务时的饿汉式初始化和懒加载 ...
- Executors 类是什么?
Executors 为 Executor,ExecutorService,ScheduledExecutorService, ThreadFactory 和 Callable 类提供了一些工具方法. ...
- 数据分析之Pandas操作
Pandas pandas需要导入 import pandas as pd from pandas import Series,DataFrame import numpy as np 1 Serie ...
- 断言工具类之"判断条件不为空"
1 Assert.notNull(query, AssertConstants.NOT_NULL_MSG);
- java之String字符串根据指定字符转化为字符串数组
public static void main(String[] args){ String str="护肤,药品,其他"; String temp[]; temp=str.spl ...