Yolov3-v5正负样本匹配机制
本文来自公众号“AI大道理”。
什么是正负样本?
正负样本是在训练过程中计算损失用的,而在预测过程和验证过程是没有这个概念的。
正样本并不是手动标注的GT。
正负样本都是针对于算法经过处理生成的框而言,而非原始的GT数据。
正例是用来使预测结果更靠近真实值的,负例是用来使预测结果更远离除了真实值之外的值的。
训练的时候为什么需要进行正负样本筛选?
在目标检测中不能将所有的预测框都进入损失函数进行计算,主要原因是框太多,参数量太大,因此需要先将正负样本选择出来,再进行损失函数的计算。
对于正样本,是回归与分类都进行,而负样本由于没有回归的对象,不进行回归,只进行分类(分类为背景)。
为什么要训练负样本?
训练负样本的目的是为了降低误检测率、误识别率,提高网络模型的泛化能力。通俗地讲就是告诉检测器,这些“不是你要检测的目标”。
正负样本的比例最好为1:1到1:2左右,数量差距不能太悬殊,特别是正样本数量本来就不太多的情况下。
如果负样本远多于正样本,则负样本会淹没正样本的损失,从而降低网络收敛的效率与检测精度。这就是目标检测中常见的正负样本不均衡问题,解决方案之一是增加正样本数。

 编辑
编辑
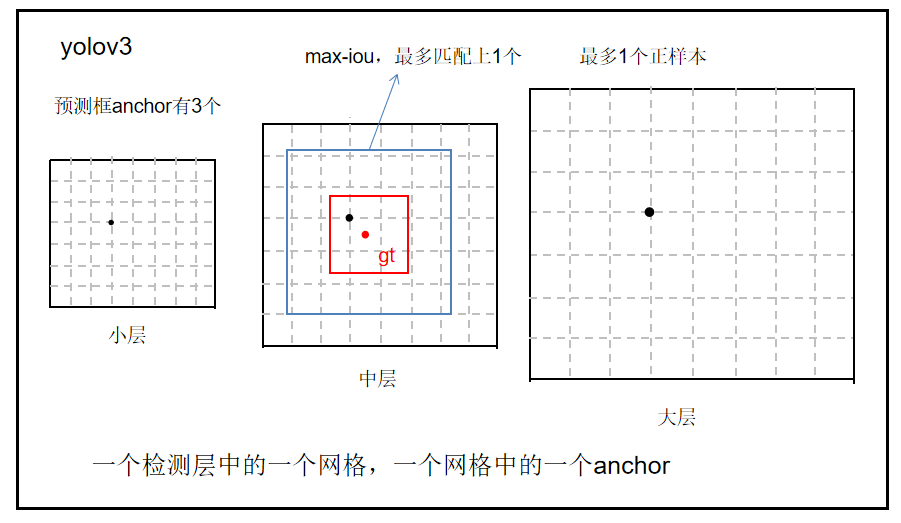
1、YOLOv3正负样本定义
yolov3是基于anchor和GT的IOU进行分配正负样本的。
步骤如下:
步骤1:每一个目标都只有一个正样本,max-iou matching策略,匹配规则为IOU最大(没有阈值),选取出来的即为正样本;
(每个目标只有一个正样本,就是这个目标先选择大中小三层中的一层,再在这层中选择一个网格,在网格上选择三个anchor中的一个)
步骤2:IOU<0.2(人为设定阈值)的作为负样本;
步骤3:除了正负样本,其余的全部为忽略样本
比如drbox(drbox就是anchor调整后的预测框)与gtbox的IOU最大为0.9,设置IOU小于0.2的为负样本。
那么有一个IOU为0.8的box,那么这个box就是忽略样本,有一个box的IOU为0.1,那么就是负样本。
步骤4:正anchor用于分类和回归的学习,正负anchor用于置信度confidence的学习,忽略样本不考虑。
编辑

编辑
2、YOLOv4正负样本定义
然而,在训练中,若只取一个IOU最大为正样本,则可能导致正样本太少,而负样本太多的正负样本不均衡问题,这样会大大降低模型的精确度。
因此,yolov4为了增加正样本,采用了multi anchor策略,即只要大于IoU阈值的anchor box,都统统视作正样本。
那些原本在YOLOv3中会被忽略掉的样本,在YOLOv4中则统统成为了正样本,这样YOLOv4的正样本会多于YOLOv3,对性能的提升也有一些帮助。
yolov4的GT需要利用max iou原则分配到不同的预测层yolo-head上去,然后在每个层上单独计算正负样本和忽略样本。不存在某个GT会分配到多个层进行预测的可能性,而是一定是某一层负责的。

编辑

编辑
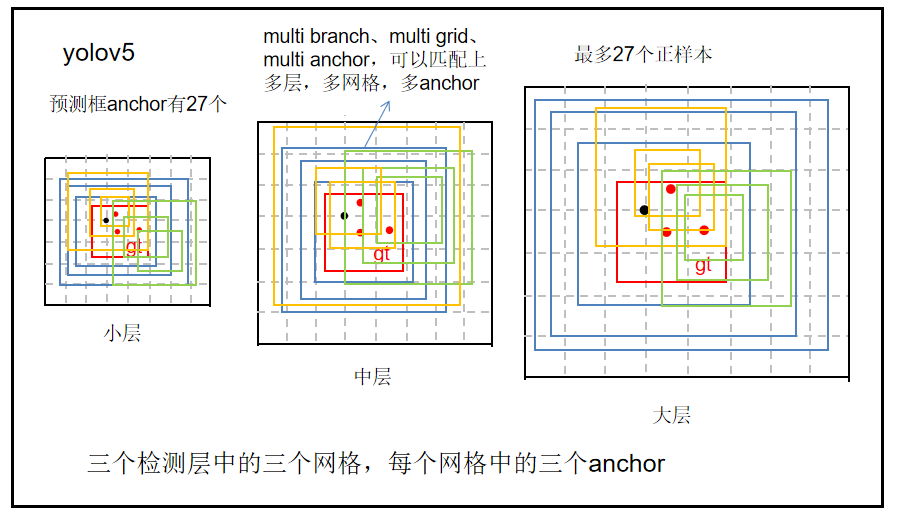
3、YOLOv5正负样本定义
yolov3的做法是一个gt标签框只能匹配到大中小三层中的某一层(a),某一层中某一个网格(b),某个网格中三个anchor中的某一个(c)。这个anchor就是训练输出的,是先验框经过调整参数的anchor,这个框与标签gt匹配上为正样本,匹配不上为负样本。
yolov4仅仅是这个框与标签gt匹配上的量变多了,从1个变成多个。
yolov5觉得yolov4的做法正样本还是太少了,于是继续增加正样本的数量。
如何增加?有三大方法,这三种方法分别对应yolov3的abc三个地方。
(1) 跨分支预测(a)
跨分支预测就是一个GT框可以由多个预测分支来预测,重复anchor匹配和grid匹配的步骤,可以得到某个GT 匹配到的所有正样本。

编辑
即这个gt可以由大中小中的几个分支负责与训练输出进行匹配。最多三个。
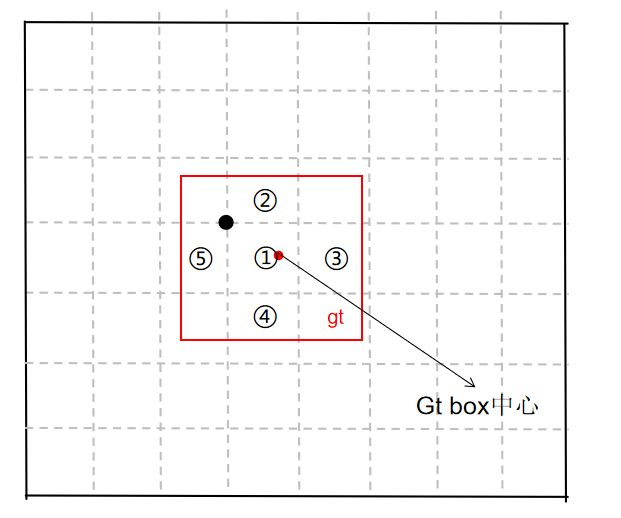
(2) 跨grid预测(b)
假设一个GT框落在了某个预测分支的某个网格内,则该网格有左、上、右、下4个邻域网格,根据GT框的中心位置,将最近的2个邻域网格也作为预测网格,也即一个GT框可以由3个网格来预测。
例子:
GT box中心点处于grid1中,grid1被选中,为了增加增样本,grid1的上下左右grid为候选网格,因为GT中心点更靠近grid2和grid3,grid2和grid3也作为匹配到的网格。
GT再与grid2和grid3上的三个anchor进行匹配。
编辑
即这个gt可以由大中小中的几个分支负责,各个分支可以由多个网格负责,这些网格上的anchor通过训练即可调整参数,形成输出的anchor,这个anchor再与gt进行匹配。最多三个网格。加上3分支,总共9个。
(3) 跨anchor预测(c)
每个层级每个格子有三个anchor,yolov3、yolov4只能匹配上三个中的一个,而yolov5可以多个匹配上。
具体方法:
不同于IOU匹配,yolov5采用基于宽高比例的匹配策略,GT的宽高与anchors的宽高对应相除得到ratio1,anchors的宽高与GT的宽高对应相除得到ratio2,取ratio1和ratio2的最大值作为最后的宽高比,该宽高比和设定阈值(默认为4)比较,小于设定阈值的anchor则为匹配到的anchor。

编辑
即一个gt可以由多个分支中的多个网格中的多个anchor同时负责。
总共有3*3*3=27个anchor负责一个gt,这样正样本的数量将大大提升。
yolov3是一个目标最多1个正样本,yolov4是一个目标最多3个正样本,yolov5一个目标最多可以有27个正样本。
编辑
yolov5正负样本分配步骤:
步骤1:对每一个GT框,分别计算它与9种anchor的宽与宽的比值、高与高的比值;
步骤2:在宽比值、高比值这2个比值中,取最极端的一个比值,作为GT框和anchor的比值;
步骤3:得到GT框和anchor的比值后,若这个比值小于设定的比值阈值,那么这个anchor就负责预测GT框,这个anchor的预测框就被称为正样本,所有其它的预测框都是负样本。

编辑
4、总结
问题1:为什么是基于anchor和gt真实标签呢?不是应该是网络输出框和gt的匹配程度吗?
答:训练输出什么呢?训练输出和预测输出是类似的。
预测输出很多检测框,这些检测框经过了nms,所以只剩下一些。
而训练的时候没有经过nms,所以训练的输出框有很多。
这些框到底是什么呢?这些框其实就是anchor。
就是设置的9个先验框anchor通过调节参数得到的预测框。
所以说,anchor和gt的真实标签匹配不是先验框和真实标签的匹配,而是经过参数调节后的预测框和真实标签的匹配。
(确定gt属于哪个anchor负责预测的时候用的是先验框,确定正负样本的时候用的是先验框经过调整后的预测框)

编辑
——————
浅谈则止,细致入微AI大道理
扫描下方“AI大道理”,选择“关注”公众号
—————————————————————
—————————————————————
Yolov3-v5正负样本匹配机制的更多相关文章
- 正负样本比率失衡SMOTE
正负样本比率失衡SMOTE [TOC] 背景 这几天测试天池的优惠券预测数据在dnn上面会不会比集成树有较好的效果,但是正负样本差距太大,而处理这种情况的一般有欠抽样和过抽样,这里主要讲过抽样,过抽样 ...
- DDBNet:Anchor-free新训练方法,边粒度IoU计算以及更准确的正负样本 | ECCV 2020
论文针对当前anchor-free目标检测算法的问题提出了DDBNet,该算法对预测框进行更准确地评估,包括正负样本以及IoU的判断.DDBNet的创新点主要在于box分解和重组模块(D&R) ...
- SpringBoot + WebSocket 实现答题对战匹配机制
概要设计 类似竞技问答游戏:用户随机匹配一名对手,双方同时开始答题,直到双方都完成答题,对局结束.基本的逻辑就是这样,如果有其他需求,可以在其基础上进行扩展 明确了这一点,下面介绍开发思路.为每个用户 ...
- 从零開始学习制作H5应用——V5.0:懊悔机制,整理文件夹,压缩,模板化
经过前面四个版本号的迭代.我们已经制作了一个从视觉和听觉上都非常舒服的H5微场景应用,没有看过的请戳以下: V1.0--简单页面滑动切换 V2.0--多页切换.透明过渡及交互指示 V3.0--增加lo ...
- ASP.NET Core MVC的路由参数中:exists后缀有什么作用,顺便谈谈路由匹配机制
我们在ASP.NET Core MVC中如果要启用Area功能,那么会看到在Startup类的Configure方法中是这么定义Area的路由的: app.UseMvc(routes => { ...
- gluoncv rpn 正负样本
https://github.com/dmlc/gluon-cv/blob/master/gluoncv/model_zoo/rpn/rpn_target.py def forward(self, i ...
- YOLO系列梳理(一)YOLOv1-YOLOv3
前言 本文是YOLO系列专栏的第一篇,该专栏将会介绍YOLO系列文章的算法原理.代码解析.模型部署等一系列内容.本文系公众号读者投稿,欢迎想写任何系列文章的读者给我们投稿,共同打造一个计算机视觉技 ...
- AI佳作解读系列(二)——目标检测AI算法集杂谈:R-CNN,faster R-CNN,yolo,SSD,yoloV2,yoloV3
1 引言 深度学习目前已经应用到了各个领域,应用场景大体分为三类:物体识别,目标检测,自然语言处理.本文着重与分析目标检测领域的深度学习方法,对其中的经典模型框架进行深入分析. 目标检测可以理解为是物 ...
- 检测算法简介及其原理——fast R-CNN,faster R-CNN,YOLO,SSD,YOLOv2,YOLOv3
1 引言 深度学习目前已经应用到了各个领域,应用场景大体分为三类:物体识别,目标检测,自然语言处理.本文着重与分析目标检测领域的深度学习方法,对其中的经典模型框架进行深入分析. 目标检测可以理解为是物 ...
- 如何使用 pytorch 实现 yolov3
前言 看了 Yolov3 的论文之后,发现这论文写的真的是很简短,神经网络的具体结构和损失函数的公式都没有给出.所以这里参考了许多前人的博客和代码,下面进入正题. 网络结构 Yolov3 将主干网络换 ...
随机推荐
- wen文章表设计
- 自定义view,用来测试屏幕
public class BezierGestureTrackView extends View { private Bitmap mBufferBitmap; private Canvas mBuf ...
- Oracle 11g 单机服务器ASM部署
Oracle oracle,相比都有所了解,是一家企业级的数据库公司(收费),上图是oracle官网,也是对外的服务平台 oracle有自己独特的安装方式:ASM : 自动存储管理(ASM,Au ...
- DOM04~
事件对象及属性 事件对象 事件流 事件委托 综合案例 事件对象 获取事件对象 事件对象常用属性 什么是事件对象? 1.1 也是个对象,这个对象里有事件触发时的相关信息 1.2 例如鼠标点击事件中,事件 ...
- gcc 内联汇编简介
啊 啊 在内联汇编中,标识寄存器的一个%变成了两个% 啊 如图是内联汇编的模板 assembler template 是汇编代码 output operands TODO input operands ...
- 性能提升 40 倍!我们用 Rust 重写了自己的项目
前言 Rust 已经悄然成为了最受欢迎的编程语言之一.作为一门新兴底层系统语言,Rust 拥有着内存安全性机制.接近于 C/C++ 语言的性能优势.出色的开发者社区和体验出色的文档.工具链和IDE 等 ...
- mfc拷贝到我的电脑出现的问题
拿到工程解压打开,霍,挺好 往下面翻了翻看到了这个 再怎么错误,怎么会没有string呢?看了看头文件,包含的有,所以 我去找了一下string.h的位置 项目->属性->VC++目录-& ...
- 20192326杨沥凯 实验一《Linux基础与Java开发环境》实验报告
20192326杨沥凯 2020-2021-1 <数据结构与面向对象程序设计>实验一报告 课程:<程序设计与数据结构> 班级: 1923 姓名: 杨沥凯 学号:20192326 ...
- SSM项目集成Redis
1. 加入依赖 <!--redis--> <dependency> <groupId>redis.clients</groupId> <artif ...
- Chrome浏览器崩溃
1.使用Win+R打开运行对话框,输入regedit,点击确定打开注册表: 2.找到"HKEY_LOCAL_MACHINE\SOFTWARE\Policies\Google\Chrome&q ...