构建api gateway之 负载均衡
什么是负载均衡
负载均衡,英文名称为Load Balance,其含义就是指将负载(工作任务)进行平衡、分摊到多个操作单元上进行运行
以下为几种负载均衡策略介绍
1.随机(Random)
大家很多时候说到随机的负载均衡都会想到 Round Robin, 其实 Round Robin并非随机,
Random 这种是真正意义上随机,根据随机算法随意分配请求到服务器。
优点:
- 有了负载能力
缺点:
- 受随机算法影响,并不能均衡各个服务器的负载,
- 也不能根据服务器的负载情况进行自我调节 所以基本很少有如此单纯的真随机策略了
2.轮循(Round Robin)
如上述,其实轮询是平均策略,并非随机策略,
它的具体策略内容如下:
负载均衡负责者有一份 服务器列表,
它会将其做排序,形成固定的 1 到 N 的顺序列表排队,
每次请求都会队列依次选择一位没有轮到的服务器同志接受 请求任务,
当整个队列都接受过任务后,就会从头开始新一轮的任务排队。
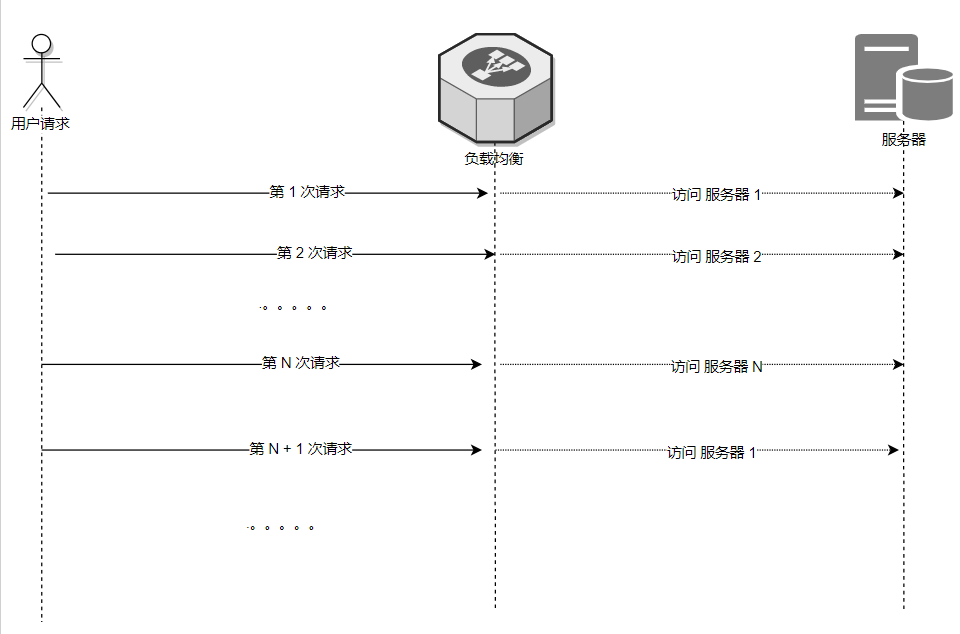
而大家为什么很多时候又说它是随机策略呢?
主要是对请求的client 来说, 这一次和下一次请求的服务器并不一定是同一个服务器,所以像是随机。
优点:
- 负载非常平均
缺点:
- 不能根据服务器差异(比如性能)调配负载情况
- 由于是顺序 1 开始, 如果一开始就是瞬间大并发流量大的情况,第一台存在被击垮的风险
3.最少连接 (Least Connection)
从名字我们就能很轻松明白了,
它的策略非常简单: 就是每次取连接计数最小的那个服务器使用
优点:
- 能根据连接数变化动态平衡资源情况
- 长连接多的场景(比如 ftp),资源调配很合理
缺点:
- 但在服务器资源差异情况下,连接数并不能平衡这种差异
- 动态增删服务器列表的场景,请求都会命中新加入的服务器,大流量易击垮这台服务器 (一般会通过 缓启动策略减低对应负载,降低风险)
4.Hash
其他的负载均衡策略都适合于无状态服务,
只有 Hash 是专门解决有状态服务的负载均衡问题的。
它的具体策略就以其中简单的做法作为说明:
比如 ip 或者 url hash, 会用 ip 或者 url 的string 根据 hash 算法 算出固定的整型数值,
然后用该整型数值 根据 服务器数量 取模运算 得出对应哪一台机器,
从而形成 粘机 的效果
优点:
- 解决了有状态服务无法负载均衡的问题
缺点:
- 服务器下线,可能导致 部分粘机的访问仍然访问失效的机器 (一般会通过health check 识别下线,然后重新hash 粘机)
- 如采用有重新 hash 粘机的算法策略,需要业务方处理上规避其带来的影响,比如不能将数据只放在粘机的服务器上
5. EWMA
印象中好像该方式最早见于 Finagle(Twitter的客户端RPC库) 中。
理论上来说服务器 在cpu 算力不足,网卡负荷过大,端口不足等等各种情况下,响应的时间都会存在明显变长的情况
那么响应的延迟变化就可以一定程度上用来评价服务器的负载以及服务器自身情况,
EWMA 的思想就是衡量请求延迟变化来动态优化负载均衡效果。
简单来说,EWMA就是 保持每个服务器请求的往返时间的移动平均值,以未完成请求的数量加权,并将流量分配给成本函数最小的服务器。
一般来说,还会使用P2C策略结合 EWMA使用,以避免同一时间集中命中同一台服务器。 (P2C 就是随机选取两台服务器,比较他们俩的EWMA值,取最小的那一个)
linkerd 做过一个负载均衡的测验,其结果 (当然并不一定代表实际效果)
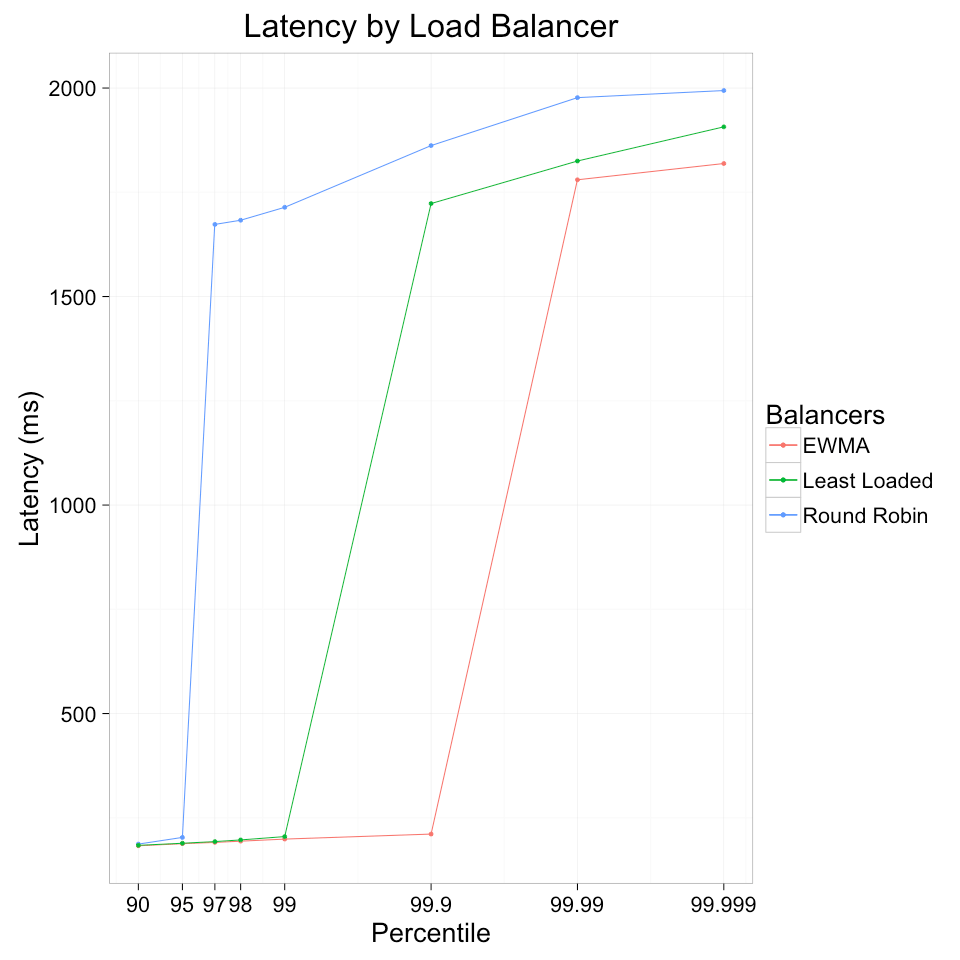
优点:
- 算法能更好根据变化情况动态调整负载情况
缺点:
- 业务场景本身就是高延迟的情况,比如长轮询,该算法就不能衡量出服务器的负载情况
权重的特殊说明
严格来说,权重很少作为单独的负载均衡策略,
一般都是与上述各种负载均衡策略进行组合。
权重的目的主要是解决 我们在已知或者能预估出服务器的负载能力的情况下, 我们如何更好的预设资源的分配。
所以现在一般这些负载均衡算法都会提供 权重参数以便大家预设负载比例,
甚至一些还尝试用机器学习等手段动态调整权重参数等,以便更快调整资源负载情况
轮循(Round Robin) 简单实现
篇幅关系,这里不解释每一个怎么实现了,只介绍 轮循(Round Robin)
以下内容更新到 openresty-dev-1.rockspec
-- 依赖包
dependencies = {
"lua-resty-balancer >= 0.04",
}然后执行
luarocks install openresty-dev-1.rockspec --tree=deps --only-deps --local具体demo 代码如下:
worker_processes 1; #nginx worker 数量
error_log logs/error.log; #指定错误日志文件路径
events {
worker_connections 1024;
}
http {
log_format main '$remote_addr [$time_local] $status $request_time $upstream_status $upstream_addr $upstream_response_time';
access_log logs/access.log main buffer=16384 flush=3; #access_log 文件配置
lua_package_path "$prefix/deps/share/lua/5.1/?.lua;$prefix/deps/share/lua/5.1/?/init.lua;$prefix/?.lua;$prefix/?/init.lua;;./?.lua;/usr/local/openresty/luajit/share/luajit-2.1.0-beta3/?.lua;/usr/local/share/lua/5.1/?.lua;/usr/local/share/lua/5.1/?/init.lua;/usr/local/openresty/luajit/share/lua/5.1/?.lua;/usr/local/openresty/luajit/share/lua/5.1/?/init.lua;";
lua_package_cpath "$prefix/deps/lib64/lua/5.1/?.so;$prefix/deps/lib/lua/5.1/?.so;;./?.so;/usr/local/lib/lua/5.1/?.so;/usr/local/openresty/luajit/lib/lua/5.1/?.so;/usr/local/lib/lua/5.1/loadall.so;";
# 开启 lua code 缓存
lua_code_cache on;
upstream nature_upstream {
server 127.0.0.1:6699; #upstream 配置为 hello world 服务
# 一样的balancer
balancer_by_lua_block {
local balancer = require "ngx.balancer"
local upstream = ngx.ctx.api_ctx.upstream
local ok, err = balancer.set_current_peer(upstream.host, upstream.port)
if not ok then
ngx.log(ngx.ERR, "failed to set the current peer: ", err)
return ngx.exit(ngx.ERROR)
end
}
}
init_by_lua_block {
-- 初始化 lb
local roundrobin = require("resty.roundrobin")
local nodes = {k1 = {host = '127.0.0.1', port = 6698}, k2 = {host = '127.0.0.1', port = 6699}}
local ns = {}
for k, v in pairs(nodes) do
-- 初始化 weight
ns[k] = 1
end
local picker = roundrobin:new(ns)
-- 初始化路由
local radix = require("resty.radixtree")
local r = radix.new({
{paths = {'/aa/d'}, metadata = picker},
})
-- 匹配路由
router_match = function()
local p, err = r:match(ngx.var.uri, {})
if err then
log.error(err)
end
-- 执行 roundrobin lb 选择
local k, err = p:find()
if not k then
return nil, err
end
return nodes[k]
end
}
server {
#监听端口,若你的8699端口已经被占用,则需要修改
listen 8699 reuseport;
location / {
# 在access阶段匹配路由
access_by_lua_block {
local upstream = router_match()
if upstream then
ngx.ctx.api_ctx = { upstream = upstream }
else
ngx.exit(404)
end
}
proxy_http_version 1.1;
proxy_pass http://nature_upstream; #转发到 upstream
}
}
#为了大家方便理解和测试,我们引入一个hello world 服务
server {
#监听端口,若你的6699端口已经被占用,则需要修改
listen 6699;
location / {
default_type text/html;
content_by_lua_block {
ngx.say("HelloWorld")
}
}
}
}启动服务并测试
$ openresty -p ~/openresty-test -c openresty.conf #启动
$ curl --request GET 'http://127.0.0.1:8699/aa/d' #第一次
<html>
<head><title>502 Bad Gateway</title></head>
<body>
<center><h1>502 Bad Gateway</h1></center>
</body>
</html>
$ curl --request GET 'http://127.0.0.1:8699/aa/d' #第二次
HelloWorld
$ curl --request GET 'http://127.0.0.1:8699/aa/d' #第三次
<html>
<head><title>502 Bad Gateway</title></head>
<body>
<center><h1>502 Bad Gateway</h1></center>
</body>
</html>
$ curl --request GET 'http://127.0.0.1:8699/aa/d' #第四次
HelloWorld可以看到 一次失败一次成功轮着来,证明 lb 起效
所有这里介绍的lb实现都可以参考 nature 中的例子
目录
构建api gateway之 负载均衡的更多相关文章
- RabbitMQ(四):使用Docker构建RabbitMQ高可用负载均衡集群
本文使用Docker搭建RabbitMQ集群,然后使用HAProxy做负载均衡,最后使用KeepAlived实现集群高可用,从而搭建起来一个完成了RabbitMQ高可用负载均衡集群.受限于自身条件,本 ...
- API网关spring cloud gateway和负载均衡框架ribbon实战
通常我们如果有一个服务,会部署到多台服务器上,这些微服务如果都暴露给客户,是非常难以管理的,我们系统需要有一个唯一的出口,API网关是一个服务,是系统的唯一出口.API网关封装了系统内部的微服务,为客 ...
- [项目构建 十三]babasport Nginx负载均衡的详细配置及使用案例详解.
在这里再次说明下, 这个项目是从网上 找到的一套学习资料, 自己在 空闲时间学习了这些东西. 这里面的code当然会有很多不完善的地方, 但是确实也能学到很多新东西.感谢看过这一些列博文和评论的小伙伴 ...
- Azure上七层负载均衡APP Gateway
Azure的SLB和ILB是最常用的4层负载均衡工具.但有些场景是7层的负载均衡,SLB和ILB就无能为力了. Azure上已经推出了APP Gateway的服务,就是7层负载均衡的负载均衡器. 如上 ...
- 【SpringCloud微服务实战学习系列】客户端负载均衡Spring Cloud Ribbon
Spring Cloud Ribbon是一个基于HTTP和TCP的客户端负载均衡工具,它基于Netflix Ribbon实现.通过Spring Cloud的封装,可以让我们轻松地将面向服务的RES模板 ...
- Spring Cloud Ribbon负载均衡
目录 一.简介 二.客户端负载均衡 三.RestTemplate详解 GET请求 POST请求 PUT请求 DELETE请求 一.简介 Spring Cloud Ribbon是一个基于HTTP 和 ...
- 负载均衡之Ocelot
Ocelot 负载均衡: 背景知识,ocelot是基于 webapi 的网关框架,要使用ocelot来做路由转发和负载均衡,需要创建一个webapi,然后以这个webapi来做gateway. ...
- Spring Cloud微服务开发笔记5——Ribbon负载均衡策略规则定制
上一篇文章单独介绍了Ribbon框架的使用,及其如何实现客户端对服务访问的负载均衡,但只是单独从Ribbon框架实现,没有涉及spring cloud.本文着力介绍Ribbon的负载均衡机制,下一篇文 ...
- apache + tomcat 负载均衡分布式集群配置
Tomcat集群配置学习篇-----分布式应用 现目前基于javaWeb开发的应用系统已经比比皆是,尤其是电子商务网站,要想网站发展壮大,那么必然就得能够承受住庞大的网站访问量:大家知道如果服务器访问 ...
- 详解API Gateway流控实现,揭开ROMA平台高性能秒级流控的技术细节
摘要:ROMA平台的核心系统ROMA Connect源自华为流程IT的集成平台,在华为内部有超过15年的企业业务集成经验. 本文分享自华为云社区<ROMA集成关键技术(1)-API流控技术详解& ...
随机推荐
- 如何通过Java导出带格式的 Excel 数据到 Word 表格
在Word中制作报表时,我们经常需要将Excel中的数据复制粘贴到Word中,这样则可以直接在Word文档中查看数据而无需打开另一个Excel文件.但是如果表格比较长,内容就会存在一定程度的丢失,无法 ...
- vue 数组更新(push【可用】,$set,slice,filter,map【都属于浅拷贝】)问题
this.$axios.post('https://....php',this.$qs.stringify({ user: 'suess' })) .then(res => { this.dat ...
- mysql 基础明细
1.mysql 没有 TOP,用limit实现 2.mysql having 聚合之后,对组操作,和GROUP By搭配 mysql where 聚合之前,对表和视图操作 3.where 子句的作用 ...
- nginx rewrite参数 以及 $1、$2参数解析(附有生产配置实例)
在nginx的配置中,是否对rewrite的配置模糊不清,还有令人迷惑的$1.$2...参数,(其实$1.$2参数在shell脚本中经常用到,用来承接传递的参数).本篇从反向代理配置的角度帮助理解一下 ...
- Seata 1.5.2 源码学习(事务执行)
关于全局事务的执行,虽然之前的文章中也有所涉及,但不够细致,今天再深入的看一下事务的整个执行过程是怎样的. 1. TransactionManager io.seata.core.model.Tran ...
- @responseBody 返回更多数据
@responseBody:注解的作用是将controller的方法返回的对象通过适当的转换器转换为指定的格式之后,写入到response对象的body区,通常用来返回JSON数据或者是XML数据,需 ...
- WEB入门——信息搜集1-20
WEB1--查看源码 查看源码即可得flag. WEB2--JS前端禁用 查看源码即可得flag. JavaScript实现禁用的方法简单来说就是当用户使用键盘执行某一命令是返回的一种状态,而这种状态 ...
- @Transactional注解事务失效的几种场景及原因
1. 介紹 在业务开发的许多场景中,我们会使用到通过事务去控制多个操作的一致性.比较多的就是通过声明式事务,即使用 @Transactional 注解修饰方法的形式.但在使用过程中,要足够了解事务失效 ...
- Azure DevOps 中自定义控件的开发
Azure DevOps 插件: Field Unique Control https://github.com/smallidea/azure-devops-extension-custom-con ...
- MySQL进阶实战7,查询的执行过程
@ 目录 一.拆分查询 二.分解关联查询 三.查询的执行过程 四.优化器的一些优化手段 1.重新定义关联表的顺序 2.将外连接转化为内连接 3.使用增加变换规则 4.优化count().max().m ...