【高并发】通过ThreadPoolExecutor类的源码深度解析线程池执行任务的核心流程
核心逻辑概述
ThreadPoolExecutor是Java线程池中最核心的类之一,它能够保证线程池按照正常的业务逻辑执行任务,并通过原子方式更新线程池每个阶段的状态。
ThreadPoolExecutor类中存在一个workers工作线程集合,用户可以向线程池中添加需要执行的任务,workers集合中的工作线程可以直接执行任务,或者从任务队列中获取任务后执行。ThreadPoolExecutor类中提供了整个线程池从创建到执行任务,再到消亡的整个流程方法。本文,就结合ThreadPoolExecutor类的源码深度分析线程池执行任务的整体流程。
在ThreadPoolExecutor类中,线程池的逻辑主要体现在execute(Runnable)方法,addWorker(Runnable, boolean)方法,addWorkerFailed(Worker)方法和拒绝策略上,接下来,我们就深入分析这几个核心方法。
execute(Runnable)方法
execute(Runnable)方法的作用是提交Runnable类型的任务到线程池中。我们先看下execute(Runnable)方法的源码,如下所示。
public void execute(Runnable command) {
//如果提交的任务为空,则抛出空指针异常
if (command == null)
throw new NullPointerException();
//获取线程池的状态和线程池中线程的数量
int c = ctl.get();
//线程池中的线程数量小于corePoolSize的值
if (workerCountOf(c) < corePoolSize) {
//重新开启线程执行任务
if (addWorker(command, true))
return;
c = ctl.get();
}
//如果线程池处于RUNNING状态,则将任务添加到阻塞队列中
if (isRunning(c) && workQueue.offer(command)) {
//再次获取线程池的状态和线程池中线程的数量,用于二次检查
int recheck = ctl.get();
//如果线程池没有未处于RUNNING状态,从队列中删除任务
if (! isRunning(recheck) && remove(command))
//执行拒绝策略
reject(command);
//如果线程池为空,则向线程池中添加一个线程
else if (workerCountOf(recheck) == 0)
addWorker(null, false);
}
//任务队列已满,则新增worker线程,如果新增线程失败,则执行拒绝策略
else if (!addWorker(command, false))
reject(command);
}
整个任务的执行流程,我们可以简化成下图所示。
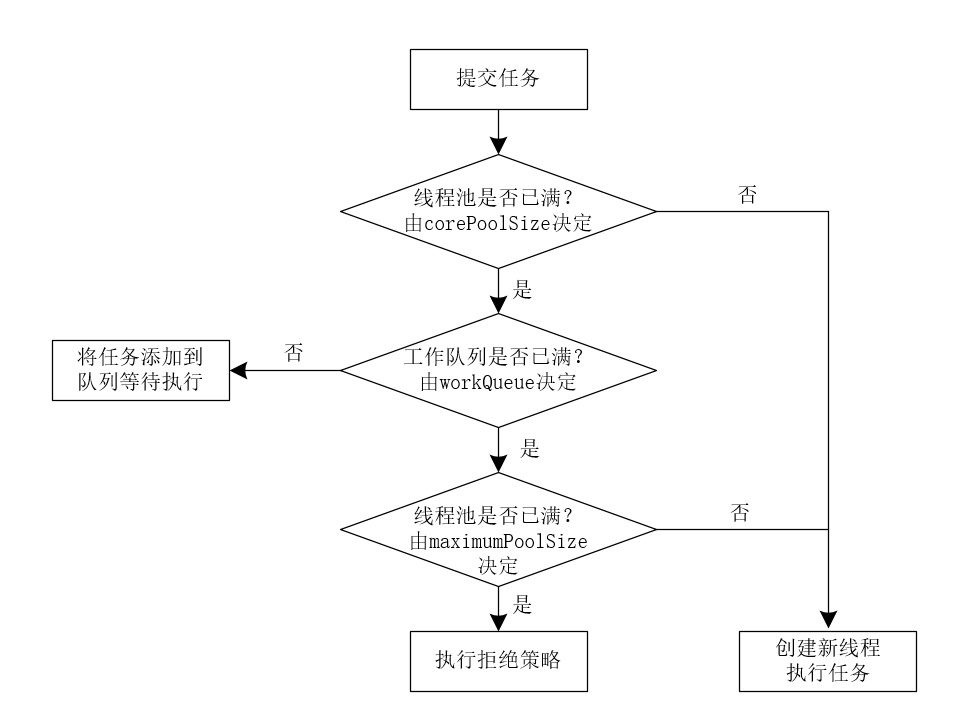
接下来,我们拆解execute(Runnable)方法,具体分析execute(Runnable)方法的执行逻辑。
(1)线程池中的线程数是否小于corePoolSize核心线程数,如果小于corePoolSize核心线程数,则向workers工作线程集合中添加一个核心线程执行任务。代码如下所示。
//线程池中的线程数量小于corePoolSize的值
if (workerCountOf(c) < corePoolSize) {
//重新开启线程执行任务
if (addWorker(command, true))
return;
c = ctl.get();
}
(2)如果线程池中的线程数量大于corePoolSize核心线程数,则判断当前线程池是否处于RUNNING状态,如果处于RUNNING状态,则添加任务到待执行的任务队列中。注意:这里向任务队列添加任务时,需要判断线程池是否处于RUNNING状态,只有线程池处于RUNNING状态时,才能向任务队列添加新任务。否则,会执行拒绝策略。代码如下所示。
if (isRunning(c) && workQueue.offer(command))
(3)向任务队列中添加任务成功,由于其他线程可能会修改线程池的状态,所以这里需要对线程池进行二次检查,如果当前线程池的状态不再是RUNNING状态,则需要将添加的任务从任务队列中移除,执行后续的拒绝策略。如果当前线程池仍然处于RUNNING状态,则判断线程池是否为空,如果线程池中不存在任何线程,则新建一个线程添加到线程池中,如下所示。
//再次获取线程池的状态和线程池中线程的数量,用于二次检查
int recheck = ctl.get();
//如果线程池没有未处于RUNNING状态,从队列中删除任务
if (! isRunning(recheck) && remove(command))
//执行拒绝策略
reject(command);
//如果线程池为空,则向线程池中添加一个线程
else if (workerCountOf(recheck) == 0)
addWorker(null, false);
(4)如果在步骤(3)中向任务队列中添加任务失败,则尝试开启新的线程执行任务。此时,如果线程池中的线程数量已经大于线程池中的最大线程数maximumPoolSize,则不能再启动新线程。此时,表示线程池中的任务队列已满,并且线程池中的线程已满,需要执行拒绝策略,代码如下所示。
//任务队列已满,则新增worker线程,如果新增线程失败,则执行拒绝策略
else if (!addWorker(command, false))
reject(command);
这里,我们将execute(Runnable)方法拆解,结合流程图来理解线程池中任务的执行流程就比较简单了。可以这么说,execute(Runnable)方法的逻辑基本上就是一般线程池的执行逻辑,理解了execute(Runnable)方法,就基本理解了线程池的执行逻辑。
注意:有关ScheduledThreadPoolExecutor类和ForkJoinPool类执行线程池的逻辑,在【高并发专题】系列文章中的后文中会详细说明,理解了这些类的执行逻辑,就基本全面掌握了线程池的执行流程。
在分析execute(Runnable)方法的源码时,我们发现execute(Runnable)方法中多处调用了addWorker(Runnable, boolean)方法,接下来,我们就一起分析下addWorker(Runnable, boolean)方法的逻辑。
addWorker(Runnable, boolean)方法
总体上,addWorker(Runnable, boolean)方法可以分为三部分,第一部分是使用CAS安全的向线程池中添加工作线程;第二部分是创建新的工作线程;第三部分则是将任务通过安全的并发方式添加到workers中,并启动工作线程执行任务。
接下来,我们看下addWorker(Runnable, boolean)方法的源码,如下所示。
private boolean addWorker(Runnable firstTask, boolean core) {
//标记重试的标识
retry:
for (;;) {
int c = ctl.get();
int rs = runStateOf(c);
// 检查队列是否在某些特定的条件下为空
if (rs >= SHUTDOWN &&
! (rs == SHUTDOWN &&
firstTask == null &&
! workQueue.isEmpty()))
return false;
//下面循环的主要作用为通过CAS方式增加线程的个数
for (;;) {
//获取线程池中的线程数量
int wc = workerCountOf(c);
//如果线程池中的线程数量超出限制,直接返回false
if (wc >= CAPACITY ||
wc >= (core ? corePoolSize : maximumPoolSize))
return false;
//通过CAS方式向线程池新增线程数量
if (compareAndIncrementWorkerCount(c))
//通过CAS方式保证只有一个线程执行成功,跳出最外层循环
break retry;
//重新获取ctl的值
c = ctl.get();
//如果CAS操作失败了,则需要在内循环中重新尝试通过CAS新增线程数量
if (runStateOf(c) != rs)
continue retry;
}
}
//跳出最外层for循环,说明通过CAS新增线程数量成功
//此时创建新的工作线程
boolean workerStarted = false;
boolean workerAdded = false;
Worker w = null;
try {
//将执行的任务封装成worker
w = new Worker(firstTask);
final Thread t = w.thread;
if (t != null) {
//独占锁,保证操作workers时的同步
final ReentrantLock mainLock = this.mainLock;
mainLock.lock();
try {
//此处需要重新检查线程池状态
//原因是在获得锁之前可能其他的线程改变了线程池的状态
int rs = runStateOf(ctl.get());
if (rs < SHUTDOWN ||
(rs == SHUTDOWN && firstTask == null)) {
if (t.isAlive())
throw new IllegalThreadStateException();
//向worker中添加新任务
workers.add(w);
int s = workers.size();
if (s > largestPoolSize)
largestPoolSize = s;
//将是否添加了新任务的标识设置为true
workerAdded = true;
}
} finally {
//释放独占锁
mainLock.unlock();
}
//添加新任成功,则启动线程执行任务
if (workerAdded) {
t.start();
//将任务是否已经启动的标识设置为true
workerStarted = true;
}
}
} finally {
//如果任务未启动或启动失败,则调用addWorkerFailed(Worker)方法
if (! workerStarted)
addWorkerFailed(w);
}
//返回是否启动任务的标识
return workerStarted;
}
乍一看,addWorker(Runnable, boolean)方法还蛮长的,这里,我们还是将addWorker(Runnable, boolean)方法进行拆解。
(1)检查任务队列是否在某些特定的条件下为空,代码如下所示。
// 检查队列是否在某些特定的条件下为空
if (rs >= SHUTDOWN &&
! (rs == SHUTDOWN &&
firstTask == null &&
! workQueue.isEmpty()))
return false;
(2)在通过步骤(1)的校验后,则进入内层for循环,在内层for循环中通过CAS来增加线程池中的线程数量,如果CAS操作成功,则直接退出双重for循环。如果CAS操作失败,则查看当前线程池的状态是否发生了变化,如果线程池的状态发生了变化,则通过continue关键字重新通过外层for循环校验任务队列,检验通过再次执行内层for循环的CAS操作。如果线程池的状态没有发生变化,此时上一次CAS操作失败了,则继续尝试CAS操作。代码如下所示。
for (;;) {
//获取线程池中的线程数量
int wc = workerCountOf(c);
//如果线程池中的线程数量超出限制,直接返回false
if (wc >= CAPACITY ||
wc >= (core ? corePoolSize : maximumPoolSize))
return false;
//通过CAS方式向线程池新增线程数量
if (compareAndIncrementWorkerCount(c))
//通过CAS方式保证只有一个线程执行成功,跳出最外层循环
break retry;
//重新获取ctl的值
c = ctl.get();
//如果CAS操作失败了,则需要在内循环中重新尝试通过CAS新增线程数量
if (runStateOf(c) != rs)
continue retry;
}
(3)CAS操作成功后,表示向线程池中成功添加了工作线程,此时,还没有线程去执行任务。使用全局的独占锁mainLock来将新增的工作线程Worker对象安全的添加到workers中。
总体逻辑就是:创建新的Worker对象,并获取Worker对象中的执行线程,如果线程不为空,则获取独占锁,获取锁成功后,再次检查线线程的状态,这是避免在获取独占锁之前其他线程修改了线程池的状态,或者关闭了线程池。如果线程池关闭,则需要释放锁。否则将新增加的线程添加到工作集合中,释放锁并启动线程执行任务。将是否启动线程的标识设置为true。最后,判断线程是否启动,如果没有启动,则调用addWorkerFailed(Worker)方法。最终返回线程是否起送的标识。
//跳出最外层for循环,说明通过CAS新增线程数量成功
//此时创建新的工作线程
boolean workerStarted = false;
boolean workerAdded = false;
Worker w = null;
try {
//将执行的任务封装成worker
w = new Worker(firstTask);
final Thread t = w.thread;
if (t != null) {
//独占锁,保证操作workers时的同步
final ReentrantLock mainLock = this.mainLock;
mainLock.lock();
try {
//此处需要重新检查线程池状态
//原因是在获得锁之前可能其他的线程改变了线程池的状态
int rs = runStateOf(ctl.get());
if (rs < SHUTDOWN ||
(rs == SHUTDOWN && firstTask == null)) {
if (t.isAlive())
throw new IllegalThreadStateException();
//向worker中添加新任务
workers.add(w);
int s = workers.size();
if (s > largestPoolSize)
largestPoolSize = s;
//将是否添加了新任务的标识设置为true
workerAdded = true;
}
} finally {
//释放独占锁
mainLock.unlock();
}
//添加新任成功,则启动线程执行任务
if (workerAdded) {
t.start();
//将任务是否已经启动的标识设置为true
workerStarted = true;
}
}
} finally {
//如果任务未启动或启动失败,则调用addWorkerFailed(Worker)方法
if (! workerStarted)
addWorkerFailed(w);
}
//返回是否启动任务的标识
return workerStarted;
addWorkerFailed(Worker)方法
在addWorker(Runnable, boolean)方法中,如果添加工作线程失败或者工作线程启动失败时,则会调用addWorkerFailed(Worker)方法,下面我们就来看看addWorkerFailed(Worker)方法的实现,如下所示。
private void addWorkerFailed(Worker w) {
//获取独占锁
final ReentrantLock mainLock = this.mainLock;
mainLock.lock();
try {
//如果Worker任务不为空
if (w != null)
//将任务从workers集合中移除
workers.remove(w);
//通过CAS将任务数量减1
decrementWorkerCount();
tryTerminate();
} finally {
//释放锁
mainLock.unlock();
}
}
addWorkerFailed(Worker)方法的逻辑就比较简单了,获取独占锁,将任务从workers中移除,并且通过CAS将任务的数量减1,最后释放锁。
拒绝策略
我们在分析execute(Runnable)方法时,线程池会在适当的时候调用reject(Runnable)方法来执行相应的拒绝策略,我们看下reject(Runnable)方法的实现,如下所示。
final void reject(Runnable command) {
handler.rejectedExecution(command, this);
}
通过代码,我们发现调用的是handler的rejectedExecution方法,handler又是个什么鬼,我们继续跟进代码,如下所示。
private volatile RejectedExecutionHandler handler;
再看看RejectedExecutionHandler是个啥类型,如下所示。
package java.util.concurrent;
public interface RejectedExecutionHandler {
void rejectedExecution(Runnable r, ThreadPoolExecutor executor);
}
可以发现RejectedExecutionHandler是个接口,定义了一个rejectedExecution(Runnable, ThreadPoolExecutor)方法。既然RejectedExecutionHandler是个接口,那我们就看看有哪些类实现了RejectedExecutionHandler接口。
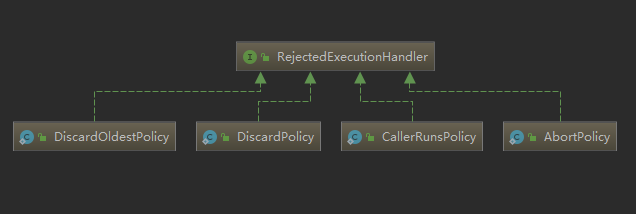
看到这里,我们发现RejectedExecutionHandler接口的实现类正是线程池默认提供的四种拒绝策略的实现类。
至于reject(Runnable)方法中具体会执行哪个类的拒绝策略,是根据创建线程池时传递的参数决定的。如果没有传递拒绝策略,则默认会执行AbortPolicy类的拒绝策略。否则会执行传递的类的拒绝策略。
在创建线程池时,除了能够传递JDK默认提供的拒绝策略外,还可以传递自定义的拒绝策略。如果想使用自定义的拒绝策略,则只需要实现RejectedExecutionHandler接口,并重写rejectedExecution(Runnable, ThreadPoolExecutor)方法即可。例如,下面的代码。
public class CustomPolicy implements RejectedExecutionHandler {
public CustomPolicy() { }
public void rejectedExecution(Runnable r, ThreadPoolExecutor e) {
if (!e.isShutdown()) {
System.out.println("使用调用者所在的线程来执行任务")
r.run();
}
}
}
使用如下方式创建线程池。
new ThreadPoolExecutor(0, Integer.MAX_VALUE,
60L, TimeUnit.SECONDS,
new SynchronousQueue<Runnable>(),
Executors.defaultThreadFactory(),
new CustomPolicy());
至此,线程池执行任务的整体核心逻辑分析结束。
好了,今天就到这儿吧,我是冰河,我们下期见~~
【高并发】通过ThreadPoolExecutor类的源码深度解析线程池执行任务的核心流程的更多相关文章
- 通过Thread Pool Executor类解析线程池执行任务的核心流程
摘要:ThreadPoolExecutor是Java线程池中最核心的类之一,它能够保证线程池按照正常的业务逻辑执行任务,并通过原子方式更新线程池每个阶段的状态. 本文分享自华为云社区<[高并发] ...
- 【高并发】通过源码深度分析线程池中Worker线程的执行流程
大家好,我是冰河~~ 在<高并发之--通过ThreadPoolExecutor类的源码深度解析线程池执行任务的核心流程>一文中我们深度分析了线程池执行任务的核心流程,在ThreadPool ...
- 【Spring源码深度解析学习系列】核心类介绍(一)
一.DefaultListableBeanFactory 首先看一下结构 由图可知XmlBeanFactory继承自DefaultListableBeanFactory,而DefaultListabl ...
- 线程池 ThreadPoolExecutor 类的源码解析
线程池 ThreadPoolExecutor 类的源码解析: 1:数据结构的分析: private final BlockingQueue<Runnable> workQueue; // ...
- 并发编程(十五)——定时器 ScheduledThreadPoolExecutor 实现原理与源码深度解析
在上一篇线程池的文章<并发编程(十一)—— Java 线程池 实现原理与源码深度解析(一)>中从ThreadPoolExecutor源码分析了其运行机制.限于篇幅,留下了Scheduled ...
- 并发编程(十二)—— Java 线程池 实现原理与源码深度解析 之 submit 方法 (二)
在上一篇<并发编程(十一)—— Java 线程池 实现原理与源码深度解析(一)>中提到了线程池ThreadPoolExecutor的原理以及它的execute方法.这篇文章是接着上一篇文章 ...
- spring5 源码深度解析----- 被面试官给虐懵了,竟然是因为我不懂@Configuration配置类及@Bean的原理
@Configuration注解提供了全新的bean创建方式.最初spring通过xml配置文件初始化bean并完成依赖注入工作.从spring3.0开始,在spring framework模块中提供 ...
- mybatis 3.x源码深度解析与最佳实践(最完整原创)
mybatis 3.x源码深度解析与最佳实践 1 环境准备 1.1 mybatis介绍以及框架源码的学习目标 1.2 本系列源码解析的方式 1.3 环境搭建 1.4 从Hello World开始 2 ...
- spring源码深度解析— IOC 之 默认标签解析(下)
在spring源码深度解析— IOC 之 默认标签解析(上)中我们已经完成了从xml配置文件到BeanDefinition的转换,转换后的实例是GenericBeanDefinition的实例.本文主 ...
随机推荐
- 面向对象编程-终结篇 es6新增语法
各位,各位,终于把js完成了一个段落了,这次的章节一过我还没确定下面要学的内容可能是vue也可能是前后端交互,但无论是哪个都挺兴奋的,因为面临着终于可以做点看得过去的大点的案例项目了,先憋住激动地情绪 ...
- FreeRTOS+CubeMX编程实践
一.关于FreeRTOS 1.什么是FreeRTOS? FreeRTOS是一个轻量级的操作系统.FreeRTOS提供的功能包括:任务管理.时间管理.信号量.消息队列.内存管理.记录功能等,可基本满足较 ...
- JDBC 4.0 开始Java操作数据库不用再使用 Class.forName加载驱动类了
JDBC 4.0 开始Java操作数据库不用再使用 Class.forName加载驱动类了 代码示例 转自 https://docs.oracle.com/javase/tutorial/jdbc/o ...
- Gitlab图床配置
注意,使用图床,如果文件在外网打开,图片不会正常显示,因为图片存储在内部的Gitlab服务器上 自行搜索Picgo安装配置,需要安装node.js 项目链接:D-W-X/picgo-plugin- ...
- 2021.11.10 fail树
2021.11.10 fail树 https://blog.csdn.net/niiick/article/details/87947160 1. AC自动机与fail树的神奇关系 1.1 AC自动机 ...
- 用 getElementsByTagName() 来获取,父元素指定的子元素
1. html 结构 <ul> <li>知否知否,应是等你好久11</li> <li>知否知否,应是等你好久11</li> <li&g ...
- C#二次开发BIMFACE系列60 File Management文件管理服务及应用场景
系列目录 [已更新最新开发文章,点击查看详细] 在我的博客<C#二次开发BIMFACE系列>教程中详细介绍了如何注册BIMFACE.测试.封装服务器端接口并提供了丰富的Demo.视 ...
- jmeter元件分析
jmeter元件分析 一.脚本通用性 1.性能测试脚本改动一下,加入断言等元件,就可以作为接口测试脚本来使用 2.但是接口测试的脚本不可以作为性能测试脚本来使用 3.原因:因为性能测试考虑更多的性能, ...
- python学习-Day29
目录 今日内容详细 反射实际案例 面向对象的双下方法 __ str __ __ del __ __ getattr __ __ setattr __ __ call __ __ enter __ __ ...
- C# iText 7 切分PDF,处理PDF页面大小
一.itext 我要使用itext做一个pdf的页面大小一致性处理,然后再根据数据切分出需要的pdf. iText的官网有关于它的介绍,https://itextpdf.com/ 然后在官网可以查找a ...