Training loop Run Builder和namedtuple()函数
namedtuple()函数见:https://www.runoob.com/note/25726和https://www.cnblogs.com/os-python/p/6809467.html
namedtuple:
namedtuple类位于collections模块,有了namedtuple后通过属性访问数据能够让我们的代码更加的直观更好维护。
namedtuple能够用来创建类似于元祖的数据类型,除了能够用索引来访问数据,能够迭代,还能够方便的通过属性名来访问数据。
在python中,传统的tuple类似于数组,只能通过下表来访问各个元素,我们还需要注释每个下表代表什么数据。通过使用namedtuple,每哥元素有了自己的名字。类似于C语言中的struct,这样数据的意义就可以一目了然。
生命namedtuple是非常简单方便的。
from collections import namedtuple
Friend = namedtuple("Friend", ['name', 'age', 'email'])
f1 = Friend('xiaowang', 33, 'xiaowang@163.com')
print(f1)
print(f1.name)
print(f1.age)
print(f1.email)
f2 = Friend(name='xiaozhang', email='xiaozhang@sina.com', age=30)
print(f2)
name, age, email = f2
print(name, age, email)
输出为:
Friend(name='xiaowang', age=33, email='xiaowang@163.com')
xiaowang
33
xiaowang@163.com
Friend(name='xiaozhang', age=30, email='xiaozhang@sina.com')
xiaozhang 30 xiaozhang@sina.com
以下参考:https://www.runoob.com/note/25726,并加上自己的一部分理解。
Python元组的升级版本 -- namedtuple(具名元组)
因为元组的局限性:不能为元组内部的数据进行命名,所以往往我们并不知道一个元组所要表达的意义,所以在这里引入了 collections.namedtuple 这个工厂函数,来构造一个带字段名的元组。
具名元组的实例和普通元组消耗的内存一样多,因为字段名都被存在对应的类里面。这个类跟普通的对象实例比起来也要小一些,因为 Python 不会用 __dict__ 来存放这些实例的属性。
namedtuple 对象的定义如以下格式:
collections.namedtuple(typename, field_names, verbose=False, rename=False)
返回一个具名元组子类 typename,其中参数的意义如下:
- typename:元组名称
- field_names: 元组中元素的名称
- rename: 如果元素名称中含有 python 的关键字,则必须设置为 rename=True
- verbose: 默认就好
例:
import collections
# 两种方法来给 namedtuple 定义方法名
User = collections.namedtuple('User', ['name', 'age', 'id'])
# User = collections.namedtuple('User', 'name age id')
user = User('tester', '22', '464643123') print(user) 输出为:
User(name='tester', age='22', id='464643123') import collections
# 两种方法来给 namedtuple 定义方法名
# User = collections.namedtuple('User', ['name', 'age', 'id'])
User = collections.namedtuple('User', 'name age id')
user = User('tester', '22', '464643123')
print(user) 输出为:
User(name='tester', age='22', id='464643123')
collections.namedtuple('User', 'name age id') 创建一个具名元组,需要两个参数,一个是类名,另一个是类的各个字段名。
后者可以是有多个字符串组成的可迭代对象,或者是有空格分隔开的字段名组成的字符串(比如本示例)。
具名元组可以通过字段名或者位置来获取一个字段的信息。
输出结果:
User(name='tester', age='22', id='464643123')
具名元组的特有属性:
类属性 _fields:包含这个类所有字段名的元组 类方法 _make(iterable):接受一个可迭代对象来生产这个类的实例 实例方法 _asdict():把具名元组以 collections.OrdereDict 的形式返回,可以利用它来把元组里的信息友好的展示出来.
from collections import namedtuple # 定义一个namedtuple类型User,并包含name,sex和age属性。
User = namedtuple('User', ['name', 'sex', 'age']) # 创建一个User对象
user = User(name='Runoob', sex='male', age=12) # 获取所有字段名
print( user._fields ) 输出为:
('name', 'sex', 'age')
from collections import namedtuple # 定义一个namedtuple类型User,并包含name,sex和age属性。
User = namedtuple('User', ['name', 'sex', 'age'])
user = User._make(['Runoob', 'male', 12])
print(user)
# User(name='user1', sex='male', age=12)
# 获取用户的属性
print(user.name)
print(user.sex)
print(user.age)
输出结果为:
User(name='Runoob', sex='male', age=12)
Runoob
male
12
from collections import namedtuple # 定义一个namedtuple类型User,并包含name,sex和age属性。
User = namedtuple('User', ['name', 'sex', 'age'])
user = User._make(['Runoob', 'male', 12])
# 修改对象属性,注意要使用"_replace"方法
user = user._replace(age=22)
print(user)
输出结果为:
User(name='Runoob', sex='male', age=22)
from collections import namedtuple # 定义一个namedtuple类型User,并包含name,sex和age属性。
User = namedtuple('User', ['name', 'sex', 'age'])
user = User._make(['Runoob', 'male', 12])
# 修改对象属性,注意要使用"_replace"方法
# user = user._replace(age=22)
# print(user)
# User(name='user1', sex='male', age=21)
# 将User对象转换成字典,注意要使用"_asdict"
print(user._asdict()) 输出结果为:
{'name': 'Runoob', 'sex': 'male', 'age': 12}
from collections import namedtuple
from collections import OrderedDict
# 定义一个namedtuple类型User,并包含name,sex和age属性。
# User = namedtuple('User', ['name', 'sex', 'age'])
# user = User._make(['Runoob', 'male', 12])
# 修改对象属性,注意要使用"_replace"方法
# user = user._replace(age=22)
# print(user)
# User(name='user1', sex='male', age=21)
# 将User对象转换成字典,注意要使用"_asdict"
# print(user._asdict())
orderdict=OrderedDict([('name', 'Runoob'), ('sex', 'male'), ('age', 22)])
print(orderdict)
for key,value in orderdict.items():
print(key,value) 输出结果为:
OrderedDict([('name', 'Runoob'), ('sex', 'male'), ('age', 22)])
name Runoob
sex male
age 22
以下内容来自deeplizard pyorch_P31


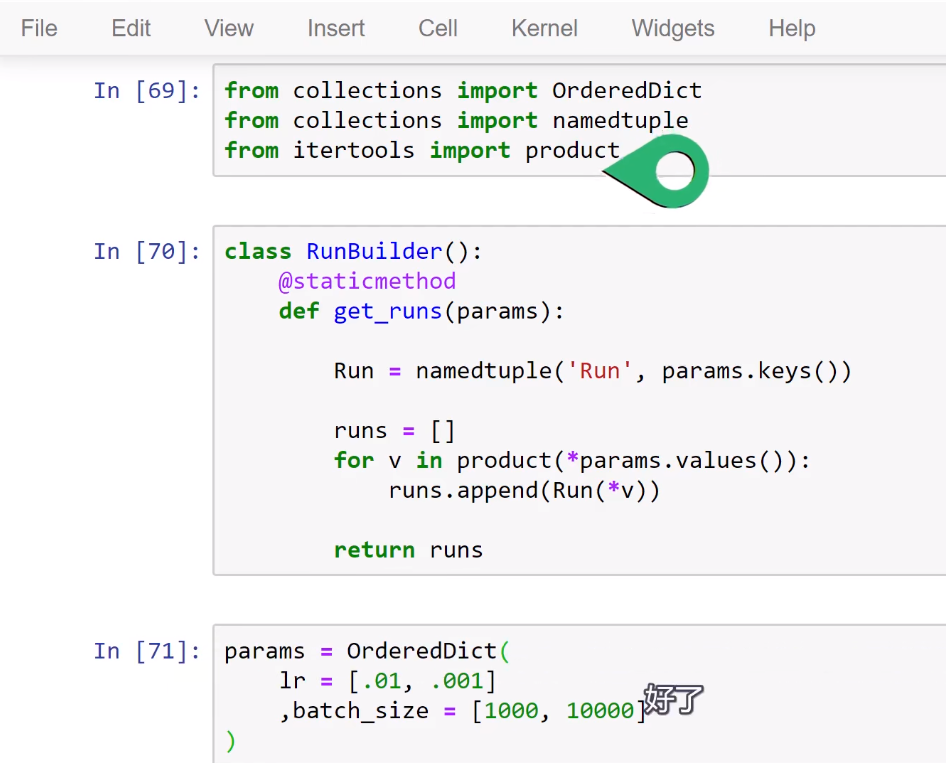
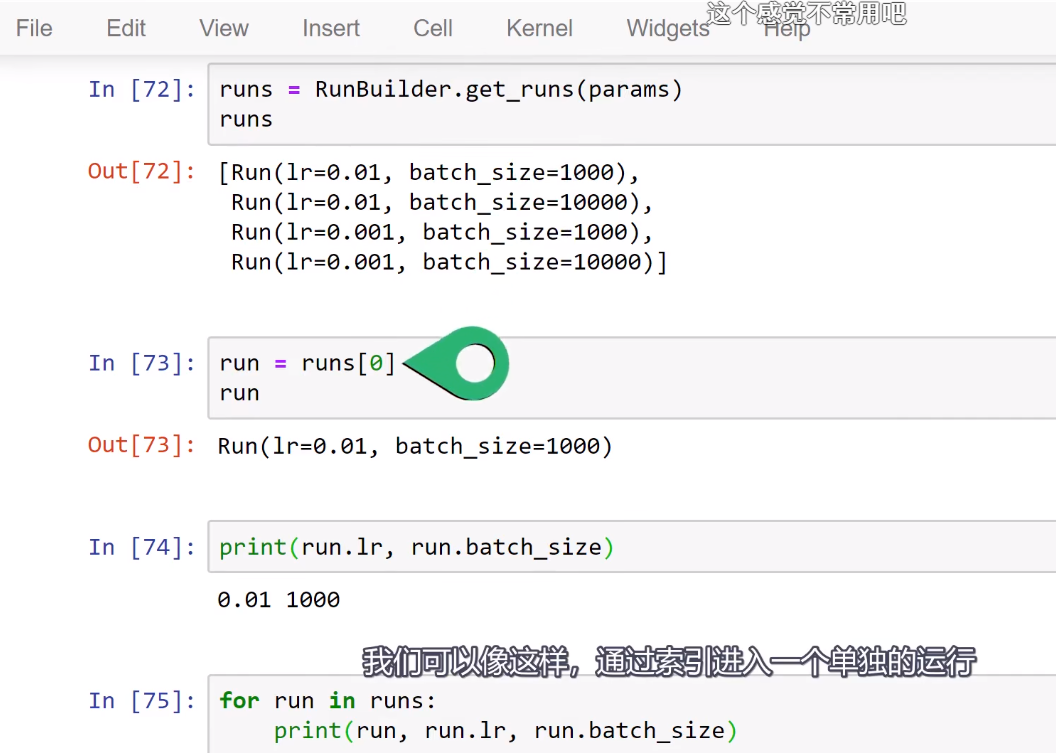

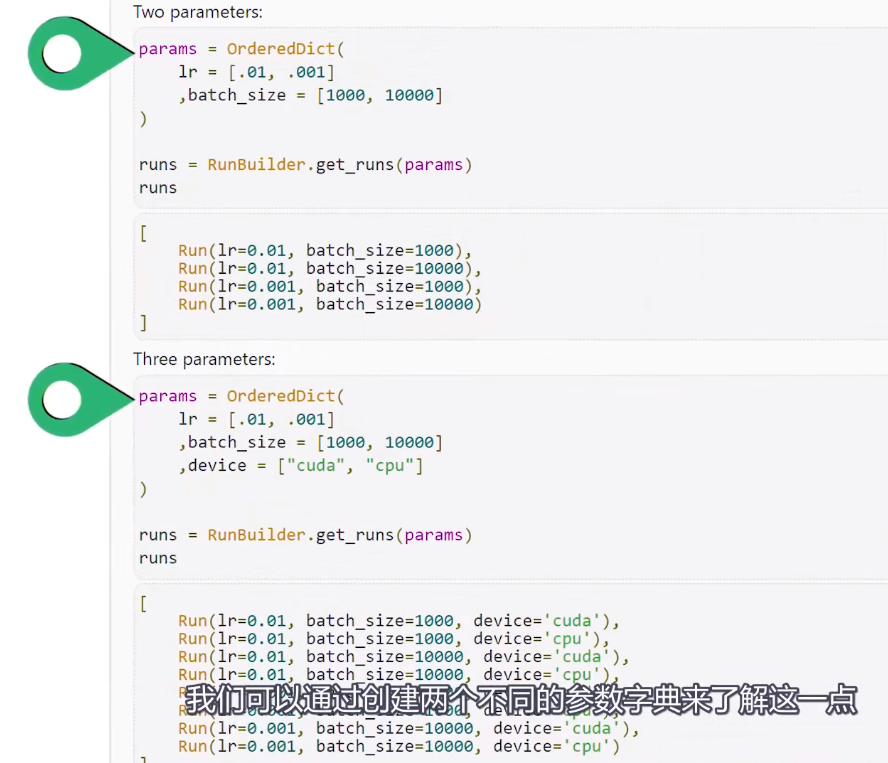





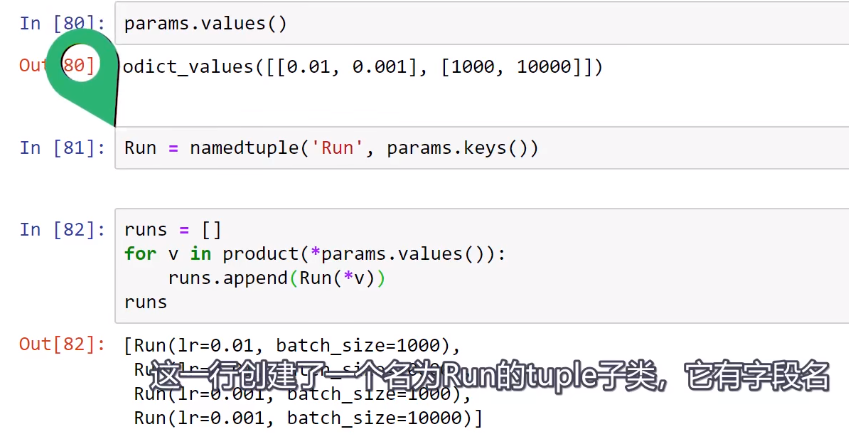




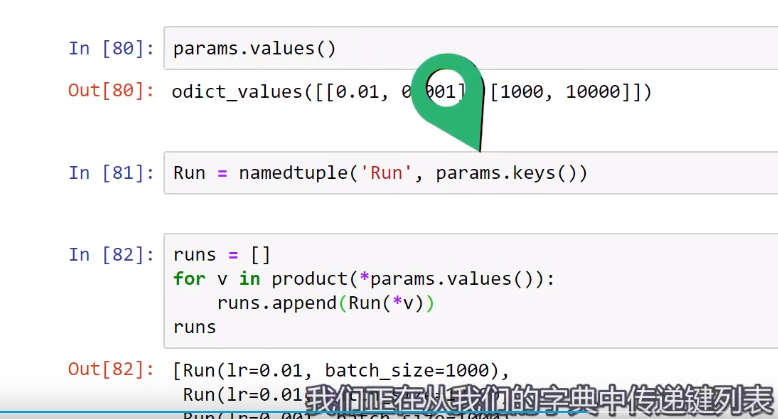
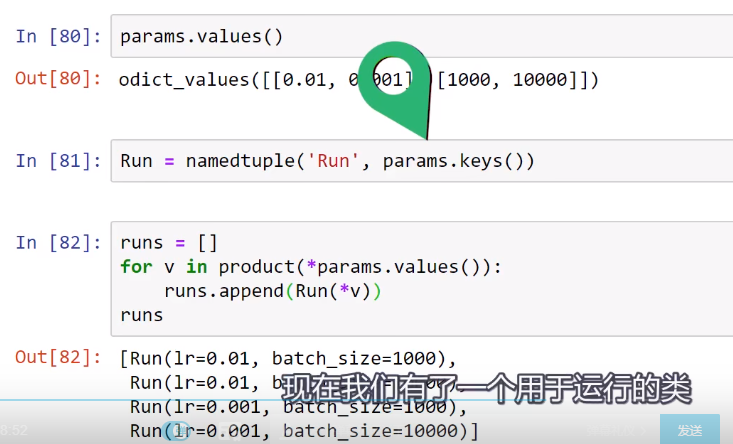
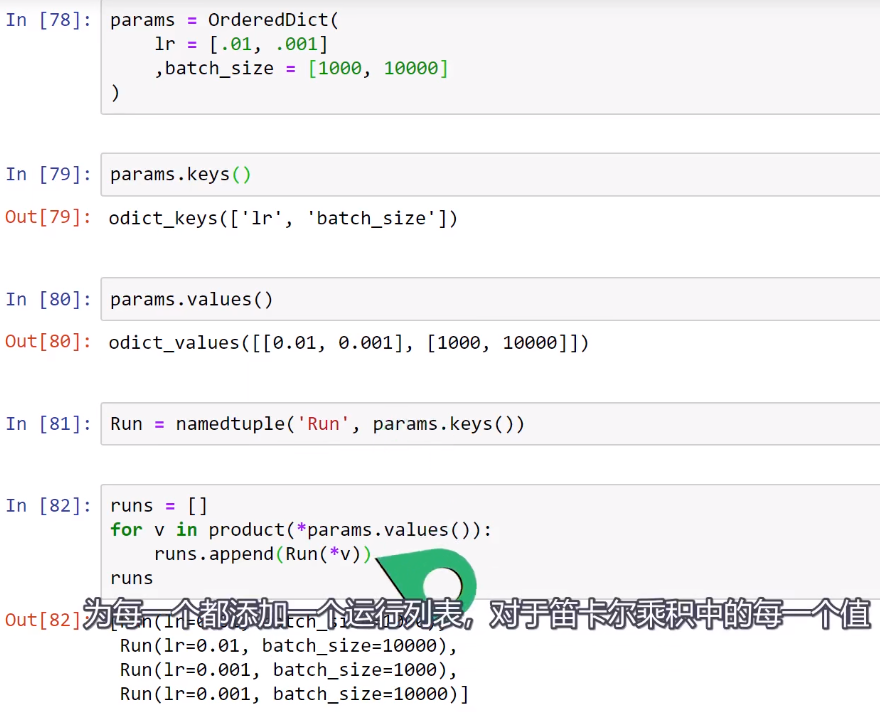







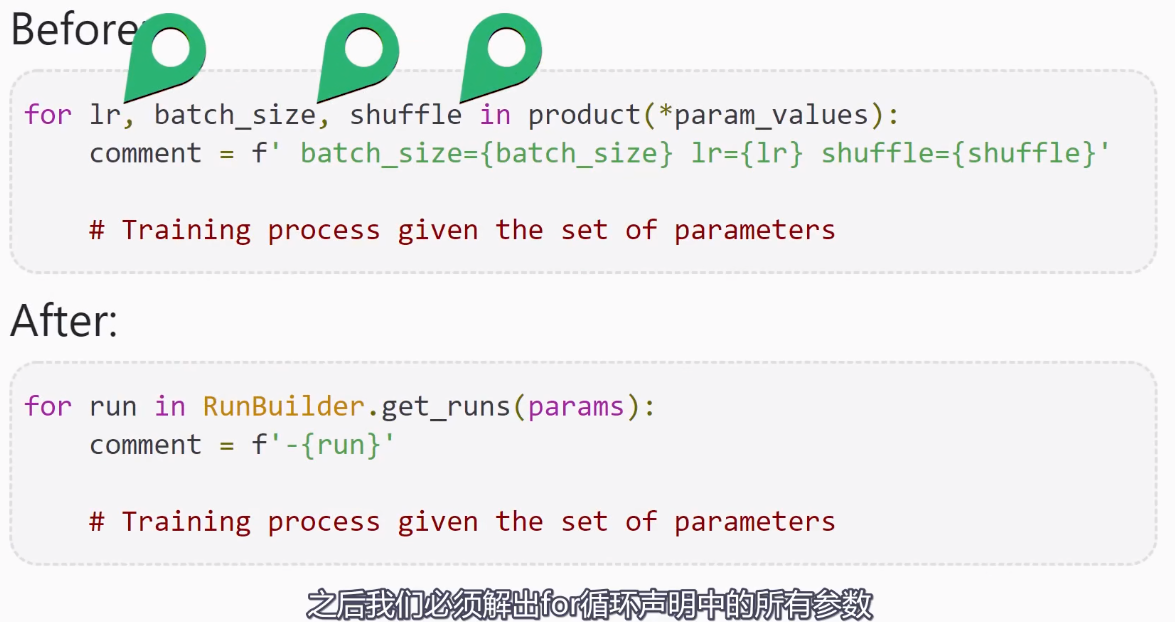



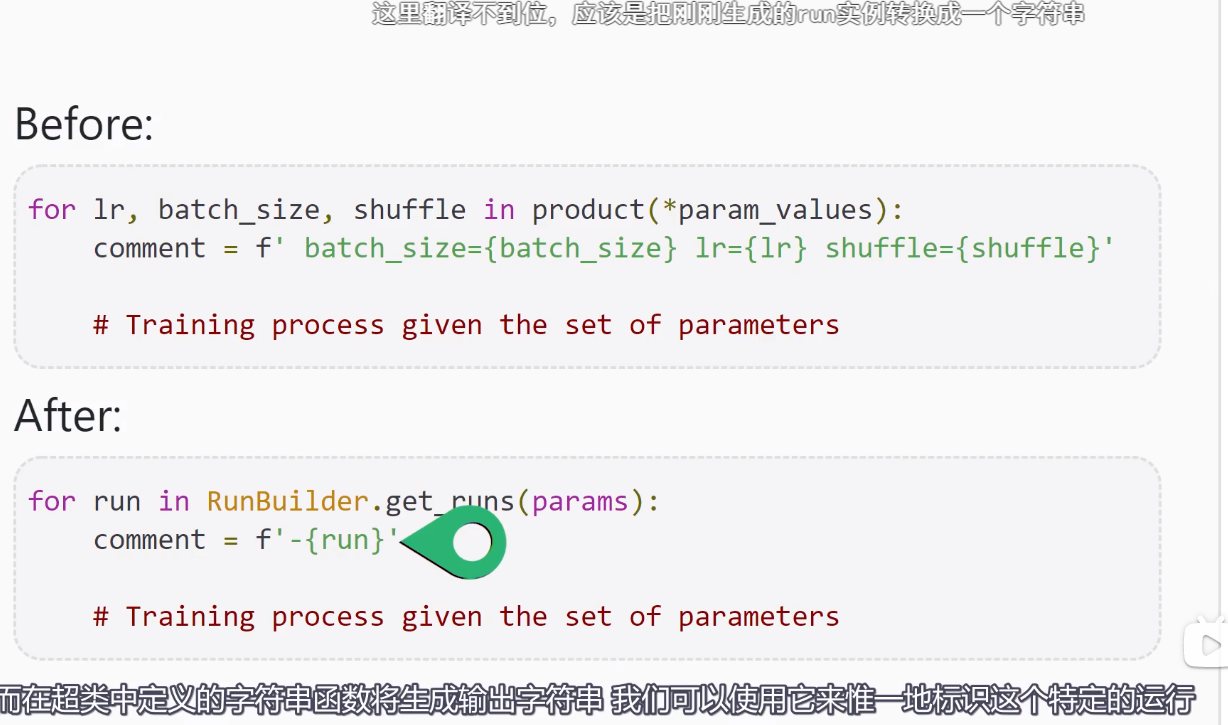
Training loop Run Builder和namedtuple()函数的更多相关文章
- Training loop Run Builder
以下内容来自deeplizard pyorch_P31
- [Form Builder]内置函数execute_trigger、do_key详解
转:http://yedward.net/?id=82 1.execute_trigger:用来运行一个指定的触发器,常用来运行用户自定义的触发器. 语法:procedure execute_trig ...
- /var/run/utmp文件操作函数
相关函数:getutent, getutid, getutline, setutent, endutent, pututline, utmpname utmp 结构定义如下:struct utmp{ ...
- CNN Training Loop Refactoring Simultaneous Hyperameter Testing
上例中, 尝试两个不同的值 为此: alt+shift可以有多个光标,再jupyter notebook中. alt+d,alt+shift,ctrl+鼠标左键多点几个,都可以同时选择多个目标,并进行 ...
- Tensorflow的基本概念与常用函数
Tensorflow一些常用基本概念与函数(一) 1.tensorflow的基本运作 为了快速的熟悉TensorFlow编程,下面从一段简单的代码开始: import tensorflow as tf ...
- [Tensorflow] Cookbook - The Tensorflow Way
本章介绍tf基础知识,主要包括cookbook的第一.二章节. 方针:先会用,后定制 Ref: TensorFlow 如何入门? Ref: 如何高效的学习 TensorFlow 代码? 顺便推荐该领域 ...
- iOS多线程编程Part 1/3 - NSThread & Run Loop
前言 多线程的价值无需赘述,对于App性能和用户体验都有着至关重要的意义,在iOS开发中,Apple提供了不同的技术支持多线程编程,除了跨平台的pthread之外,还提供了NSThread.NSOpe ...
- 格而知之5:我所理解的Run Loop
1.什么是Run Loop? (1).Run Loop是线程的一项基础配备,它的主要作用是来让某一条线程在有任务的时候工作.没有任务的时候休眠. (2).线程和 Run Loop 之间的关系是一一对应 ...
- iOS RUN LOOP 是个什么东西?
RUN Loop是什么? 1.runloop是事件接收和分发机制的一个实现. 2.什么时候使用runloop 当需要和该线程进行交互的时候.主线程默认有runloop.当自己启动一个线程,如果只是 ...
随机推荐
- 集合框架基础三——Map
Map接口 * 将键映射到值的对象 * 一个映射不能包含重复的键 * 每个键最多只能映射到一个值 Map接口和Collection接口的不同 * Map是双列的,Collection是单列的 * ...
- 使用Socket实现HttpServer(一)
使用Socket实现HttpServer(一) Socket 编程 socket 翻译过来叫插槽,一张图你就明白 socket 就插在 TCP 也就是传输层上,对用户的请求和服务器的响应进行处理. 下 ...
- NLP---word2vec的python实现
import logging from gensim.models import word2vec import multiprocessing # 配置日志 logging.basicConfig( ...
- 测试开发【Mock平台】04实战:前后端项目初始化与登录鉴权实现
[Mock平台]为系列测试开发教程,从0到1编码带你一步步使用Spring Boot 和 Antd React 框架完成搭建一个测试工具平台,希望作为一个实战项目能为你的测试开发学习有帮助. 一.后端 ...
- git远程建立仓库后,将本地项目推到远程报错 fatal: refusing to merge unrelated histories
出现这个问题的最主要原因还是在于本地仓库和远程仓库实际上是独立的两个仓库,假如之前是直接clone的方式在本地仓库就不会有这个问题了. 解决方式是在命令后紧跟 --allow-unrelated-hi ...
- docker基础_Dockerfile
Dockerfile []: https://docs.docker.com/language/python/build-images/ "docker官方文档" 以python为 ...
- Vue_transition动画
1 <!DOCTYPE html> 2 <html lang="en" xmlns:v-on="http://www.w3.org/1999/xhtml ...
- JavaWeb和WebGIS学习笔记(六)——使用ArcGIS for Server发布地图服务
系列链接: Java web与web gis学习笔记(一)--Tomcat环境搭建 Java web与web gis学习笔记(二)--百度地图API调用 JavaWeb和WebGIS学习笔记(三)-- ...
- Navicat导出结果显示科学计数法(PostgreSQL)
原因:在EXCEL录入数超过11位,就会变成科学记数法 解决方案: 在postgresql需要导出的列中加入制表符 示例: SELECT 6280920221390000000061:: TEXT | ...
- C++的三种继承方式详解以及区别
目录 目录 C++的三种继承方式详解以及区别 前言 一.public继承 二.protected继承 三.private继承 四.三者区别 五.总结 后话 C++的三种继承方式详解以及区别 前言 我发 ...