pytorch学习笔记二之自动差分引擎
自动差分引擎¶
torch.autograd是 PyTorch 的自动差分引擎,可为神经网络训练提供支持。
1. 背景¶
神经网络(NN)是在某些输入数据上执行的嵌套函数的集合。 这些函数由参数(由权重和偏差组成)定义,这些参数在 PyTorch 中存储在张量中。
训练 NN 分为两个步骤:
正向传播:在正向传播中,NN 对正确的输出进行最佳猜测。 它通过其每个函数运行输入数据以进行猜测。
反向传播:在反向传播中,NN 根据其猜测中的误差调整其参数。 它通过从输出向后遍历,收集有关函数参数(梯度)的误差导数并使用梯度下降来优化参数来实现。
2. 在PyTorch中的用法¶
从torchvision加载了经过预训练的 resnet18 模型。 我们创建一个随机数据张量来表示具有 3 个通道的单个图像,高度&宽度为 64,其对应的label初始化为一些随机值。
import torch, torchvision
model = torchvision.models.resnet18(pretrained=True)
data = torch.rand(1, 3, 64, 64)
labels = torch.rand(1, 1000)
data
tensor([[[[0.0421, 0.5498, 0.7633, ..., 0.2027, 0.8481, 0.4255],
[0.0836, 0.1886, 0.6250, ..., 0.7480, 0.9735, 0.9916],
[0.5927, 0.5473, 0.0020, ..., 0.0484, 0.4672, 0.3397],
...,
[0.0417, 0.1756, 0.4057, ..., 0.6818, 0.5592, 0.0416],
[0.5929, 0.5567, 0.4616, ..., 0.7430, 0.3945, 0.5043],
[0.0605, 0.1436, 0.4877, ..., 0.3241, 0.3844, 0.1287]],
[[0.8837, 0.8610, 0.0051, ..., 0.5536, 0.8028, 0.9089],
[0.2953, 0.7259, 0.1958, ..., 0.4079, 0.2951, 0.0619],
[0.7267, 0.6365, 0.2589, ..., 0.3394, 0.7242, 0.0889],
...,
[0.8844, 0.3406, 0.3673, ..., 0.5602, 0.8214, 0.5659],
[0.0224, 0.1693, 0.6389, ..., 0.7752, 0.6179, 0.7025],
[0.0381, 0.5284, 0.7387, ..., 0.0622, 0.8492, 0.6335]],
[[0.1731, 0.2461, 0.3651, ..., 0.5243, 0.4385, 0.5899],
[0.8973, 0.8928, 0.1662, ..., 0.8957, 0.8555, 0.4384],
[0.7018, 0.5639, 0.9140, ..., 0.1942, 0.8108, 0.3777],
...,
[0.5671, 0.1807, 0.6835, ..., 0.5997, 0.3520, 0.7260],
[0.4286, 0.2101, 0.6863, ..., 0.5068, 0.8704, 0.2469],
[0.6926, 0.3865, 0.5115, ..., 0.7462, 0.6604, 0.4729]]]])接下来,我们通过模型的每一层运行输入数据以进行预测。 这是正向传播。
prediction = model(data) # forward pass
我们使用模型的预测和相应的标签来计算误差(loss)。 下一步是通过网络反向传播此误差。 当我们在误差张量上调用.backward()时,开始反向传播。 然后,Autograd 会为每个模型参数计算梯度并将其存储在参数的.grad属性中。
loss = (prediction - labels).sum()
loss.backward() # backward pass
接下来,我们加载一个优化器,在本例中为 SGD,学习率为 0.01,动量为 0.9。 我们在优化器中注册模型的所有参数。
optim = torch.optim.SGD(model.parameters(), lr=1e-2, momentum=0.9)
最后,我们调用.step()启动梯度下降。 优化器通过.grad中存储的梯度来调整每个参数。
optim.step() #gradient descent
optim
SGD (
Parameter Group 0
dampening: 0
lr: 0.01
momentum: 0.9
nesterov: False
weight_decay: 0
)3. autograd的微分¶
我们用requires_grad=True创建两个张量a和b。 这向autograd发出信号,应跟踪对它们的所有操作。
import torch
a = torch.tensor([2., 3.], requires_grad=True)
b = torch.tensor([6., 4.], requires_grad=True)
我们从a和b创建另一个张量Q。
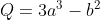
Q = 3*a**3 - b**2
假设a和b是神经网络的参数,Q是误差。 在 NN 训练中,我们想要相对于参数的误差,即
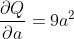
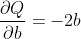
当我们在Q上调用.backward()时,Autograd 将计算这些梯度并将其存储在各个张量的.grad属性中。
我们需要在Q.backward()中显式传递gradient参数,因为它是向量。 gradient是与Q形状相同的张量,它表示Q相对于本身的梯度,即
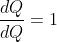
同样,我们也可以将Q聚合为一个标量,然后隐式地向后调用,例如Q.sum().backward()。
external_grad = torch.tensor([1., 1.])
Q.backward(gradient=external_grad)
梯度现在沉积在a.grad和b.grad中
a.grad
tensor([36., 81.])a
tensor([2., 3.], requires_grad=True)9*a**2
tensor([36., 81.], grad_fn=<MulBackward0>)# check if collected gradients are correct
print(9*a**2 == a.grad)
print(-2*b == b.grad)
tensor([True, True])
tensor([True, True])
pytorch学习笔记二之自动差分引擎的更多相关文章
- 莫烦pytorch学习笔记(二)——variable
.简介 torch.autograd.Variable是Autograd的核心类,它封装了Tensor,并整合了反向传播的相关实现 Variable和tensor的区别和联系 Variable是篮子, ...
- 莫烦 - Pytorch学习笔记 [ 二 ] CNN ( 1 )
CNN原理和结构 观点提出 关于照片的三种观点引出了CNN的作用. 局部性:某一特征只出现在一张image的局部位置中. 相同性: 同一特征重复出现.例如鸟的羽毛. 不变性:subsampling下图 ...
- InterSystems Ensemble学习笔记(二) Ensemble创建镜像, 实现自动故障转移
系列目录 InterSystems Ensemble学习笔记(一) Ensemble介绍及安装InterSystems Ensemble学习笔记(二) Ensemble创建镜像, 实现自动故障转移 一 ...
- [Firefly引擎][学习笔记二][已完结]卡牌游戏开发模型的设计
源地址:http://bbs.9miao.com/thread-44603-1-1.html 在此补充一下Socket的验证机制:socket登陆验证.会采用session会话超时的机制做心跳接口验证 ...
- java之jvm学习笔记二(类装载器的体系结构)
java的class只在需要的时候才内转载入内存,并由java虚拟机的执行引擎来执行,而执行引擎从总的来说主要的执行方式分为四种, 第一种,一次性解释代码,也就是当字节码转载到内存后,每次需要都会重新 ...
- Java IO学习笔记二
Java IO学习笔记二 流的概念 在程序中所有的数据都是以流的方式进行传输或保存的,程序需要数据的时候要使用输入流读取数据,而当程序需要将一些数据保存起来的时候,就要使用输出流完成. 程序中的输入输 ...
- Django学习笔记二
Django学习笔记二 模型类,字段,选项,查询,关联,聚合函数,管理器, 一 字段属性和选项 1.1 模型类属性命名限制 1)不能是python的保留关键字. 2)不允许使用连续的下划线,这是由dj ...
- ES6学习笔记<二>arrow functions 箭头函数、template string、destructuring
接着上一篇的说. arrow functions 箭头函数 => 更便捷的函数声明 document.getElementById("click_1").onclick = ...
- ArcGIS案例学习笔记-CAD数据自动拓扑检查
ArcGIS案例学习笔记-CAD数据自动拓扑检查 联系方式:谢老师,135-4855-4328,xiexiaokui#qq.com 功能:针对CAD数据,自动进行拓扑检查 优点:类别:地理建模项目实例 ...
- python3.4学习笔记(二) 类型判断,异常处理,终止程序
python3.4学习笔记(二) 类型判断,异常处理,终止程序,实例代码: #idle中按F5可以运行代码 #引入外部模块 import xxx #random模块,randint(开始数,结束数) ...
随机推荐
- 用 Java?试试国产框架 Solon v1.11.5(带视频)
一个更现代感的 Java 应用开发框架:更快.更小.更自由.没有 Spring,没有 Servlet,没有 JavaEE:独立的轻量生态.主框架仅 0.1 MB. @Controller public ...
- HTTP协议图文简述--HTTP/HTTPS/HTTP2
01.准备 1.1.先了解下网络模型/TCP HTTP 连接是建立在 TCP* 协议之上的,其数据传输功能是由TCP完成的,那TCP又是什么呢? TCP 是一个单纯用来建立通信连接,并传输数据的基础协 ...
- 过debugger的几种方法+案例
受益匪浅 https://mp.weixin.qq.com/s/559so0RheeiQdA670J23yghttps://blog.csdn.net/weixin_43834227/article/ ...
- vue 组件之间传值(父传子,子传父)
1.父传子 基本就用一个方式,props Father.vue(用v-bind(简写 : ) 将父组件传的值绑定到子组件上) <template> <div> 我是爸爸:{{ ...
- vite+ts+vue3+router4+Pinia+ElmPlus+axios+mock项目基本配置
1.vite+TS+Vue3 npm create vite Project name:... yourProjectName Select a framework:>>Vue Selec ...
- [seaborn] seaborn学习笔记11-绘图实例(3) Drawing example(3)
11 绘图实例(3) Drawing example(3)(代码下载) 本文主要讲述seaborn官网相关函数绘图实例.具体内容有: Plotting a diagonal correlation m ...
- [OpenCV实战]37 图像质量评价BRISQUE
摄影是全世界数百万人最喜爱的爱好.毕竟,这有多难啊!用美国著名摄影师阿巴斯•黛安娜的话来说: 拍照就像深夜踮着脚尖走进厨房,偷奥利奥饼干. 拍照很容易,但是拍一张高质量的照片却很难.它需要良好的组成和 ...
- JAVA中使用最广泛的本地缓存?Ehcache的自信从何而来3 —— 本地缓存变身分布式集群缓存,打破本地缓存天花板
大家好,又见面了. 本文是笔者作为掘金技术社区签约作者的身份输出的缓存专栏系列内容,将会通过系列专题,讲清楚缓存的方方面面.如果感兴趣,欢迎关注以获取后续更新. 上一篇文章中,我们知晓了如何在项目中通 ...
- python数据分析与可视化【思维导图】
python数据分析与可视化常用库 numpy+matplotlib+pandas 思维导图 图中难免有错误,后期随着学习与应用的深入,会不断修改更新. 当前版本号:1.0 numpy介绍 NumPy ...
- 单向绑定vs双向绑定、单向数据流vs双向数据流
参考文章:http://www.qb5200.com/article/482839.html 单双向绑定指的是View层跟Model层之间的映射关系 单向绑定vs双向绑定 react采用单向绑定,vu ...