莫烦 - Pytorch学习笔记 [ 二 ] CNN ( 1 )
CNN原理和结构
观点提出
关于照片的三种观点引出了CNN的作用。
- 局部性:某一特征只出现在一张image的局部位置中。
- 相同性: 同一特征重复出现。例如鸟的羽毛。
- 不变性:subsampling下图片性质不变。类似于图片压缩。
相比与Fully Connected,减少了权重数目。
组成结构
卷积层
使用一个集合的滤波器在输入数据上滑动,得到内积,形成K张二维的激活图,作为该层卷积层的输出。
- 每类的滤波器寻找一种特征进行激活。
- 一个滤波器的高度必须与输入数据体的深度一致。
- 卷积层的输出深度是一个超参数,它与使用的滤波器的数量一致。
例如:
一张28 * 28 * 3的照片,\(W_1=28, H_1=28, D_1=3\),故感受野的尺寸可以是 5 * 5 * 3的。
若有16个滤波器同时运算,则输出层数为16。
4个超参数:滤波器数量\(K\),空间尺寸\(F\),滑动步长\(S\),零填充数量\(P\)。
一次过滤后输出体的尺寸 \(W_2 * H_2 * D_2\)
\]
步长必须是整数,零填充数量$ \frac{F - step}{2}$
参数共享:相同的滤波器可以检测出不同位置的相同特征,可以有效减少参数。
小滤波器的有效性:多个卷积层首先与非线性激活层交替的结构,比单一卷积层的结构更能提取出深层的特征;小滤波器组合使用参数更少,但不足的是反向更新参数时,可能会使用更多的内存。
池化层
逐渐降低数据体的空间尺寸,这样能够减少网络中参数的数量。
2个超参数:空间尺寸\(F\),滑动步长\(S\)。
最常用的池化层形式是尺寸为2*2的窗口,滑动步长为2,对图像进行采样,将其中75%的激活信息都丢掉,只选择其中最大的保留,以此去掉一些噪声信息。
平均池化一般放在CNN的最后一层。
CNN模块等
参数列表
卷积层参数:
in_channels: 当图片为RGB时为3,否则为1。对应的是输入数据体的深度。out_channels:输出数据体的深度。kernel_size:滤波器的大小,单位pixel。stride:步长padding:=0表示四周不进行0填充,=1表示进行1个像素点的填充。
池化层参数:
kernel_size:=2表示 2*2的小矩阵中选max。
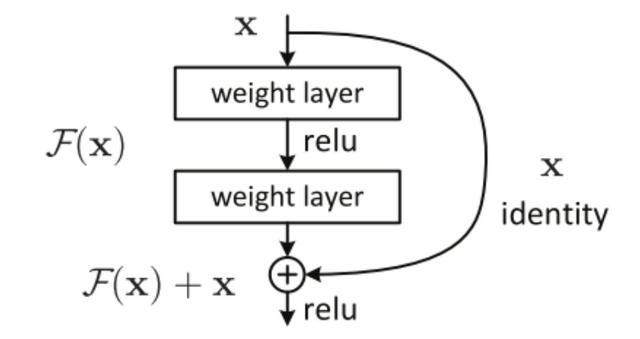
CNN模型:ResNet
若将输入设为X,将某一有参网络层设为H,那么以X为输入的此层的输出将为H(X)。一般的CNN网络如Alexnet/VGG等会直接通过训练学习出参数函数H的表达,从而直接学习X -> H(X)。
而残差学习则是致力于使用多个有参网络层来学习输入、输出之间的参差即H(X) - X即学习X -> (H(X) - X) + X。其中X这一部分为直接的identity mapping,而H(X) - X则为有参网络层要学习的输入输出间残差。
class CNN(nn.Module):
..
def forward(self, x):
residual = x
# 代入层结构
if self.downsample is not None:
residual = self.downsample(x)
out += residual
#...
莫烦 - Pytorch学习笔记 [ 二 ] CNN ( 1 )的更多相关文章
- 莫烦pytorch学习笔记(二)——variable
.简介 torch.autograd.Variable是Autograd的核心类,它封装了Tensor,并整合了反向传播的相关实现 Variable和tensor的区别和联系 Variable是篮子, ...
- 莫烦pytorch学习笔记(八)——卷积神经网络(手写数字识别实现)
莫烦视频网址 这个代码实现了预测和可视化 import os # third-party library import torch import torch.nn as nn import torch ...
- 莫烦pytorch学习笔记(七)——Optimizer优化器
各种优化器的比较 莫烦的对各种优化通俗理解的视频 import torch import torch.utils.data as Data import torch.nn.functional as ...
- 莫烦PyTorch学习笔记(五)——模型的存取
import torch from torch.autograd import Variable import matplotlib.pyplot as plt torch.manual_seed() ...
- 莫烦PyTorch学习笔记(六)——批处理
1.要点 Torch 中提供了一种帮你整理你的数据结构的好东西, 叫做 DataLoader, 我们能用它来包装自己的数据, 进行批训练. 而且批训练可以有很多种途径. 2.DataLoader Da ...
- 莫烦PyTorch学习笔记(三)——激励函数
1. sigmod函数 函数公式和图表如下图 在sigmod函数中我们可以看到,其输出是在(0,1)这个开区间内,这点很有意思,可以联想到概率,但是严格意义上讲,不要当成概率.sigmod函数 ...
- 莫烦 - Pytorch学习笔记 [ 一 ]
1. Numpy VS Torch #相互转换 np_data = torch_data.numpy() torch_data = torch.from_numpy(np_data) #abs dat ...
- 莫烦PyTorch学习笔记(五)——分类
import torch from torch.autograd import Variable import torch.nn.functional as F import matplotlib.p ...
- 莫烦PyTorch学习笔记(四)——回归
下面的代码说明个整个神经网络模拟回归的过程,代码含有详细注释,直接贴下来了 import torch from torch.autograd import Variable import torch. ...
随机推荐
- Java代码三级跳——表达式、语句和代码块
Java代码三级跳—表达式.语句和代码块 表达式(expression):Java中最基本的一个运算.比如一个加法运算表达式.1+2是一个表达式,a+b也是. 语句(statement):类似于平时说 ...
- bm坏字符 , Horspool算法 以及Sunday算法的不同
bm坏字符 , Horspool算法 以及Sunday算法的不同 一.bm中的坏字符规则思想 (1)模式串与主串从后向前匹配 (2)发现坏字符后,如果坏字符不存在于模式串中:将模式串的头字符与坏字符后 ...
- 喵星之旅-狂奔的兔子-docker安装和基本使用
一.前提条件 目前,CentOS 仅发行版本中的内核支持 Docker. 位.系统内核版本为 3.10 以上. 位系统.参考喵星之旅-狂奔的兔子-linux安装 二.CentOS 7下安装 Doc ...
- 攻防世界 robots题
来自攻防世界 robots [原理] robots.txt是搜索引擎中访问网站的时候要查看的第一个文件.当一个搜索蜘蛛访问一个站点时,它会首先检查该站点根目录下是否存在robots.txt,如果存在, ...
- 排序算法大荟萃——希尔(Shell)排序算法
1.基本思想:先取一个小于n的整数d1作为第一个增量,把文件的全部记录分成d1个组.所有距离为d1的倍数的记录放在同一个组中.先再各族中进行直接插入排序,然后取第二个增量d2<d1重复上述的分组 ...
- Android日常debug
获取SD卡文件 File file=new File(Environment.getExternalStorageDirectory().toString()+"/Music", ...
- Javascript中forEach的异步问题
某天尝试了下在 forEach函数中调用 await Promise() 方法,如下: var arr = [1,2,3] arr.forEach(async (v,i,a)=>{ await ...
- Elasticsearch系列---初识mapping
概要 本篇简单介绍一下field数据类型mapping的相关知识. mapping是什么? 前面几篇的实战案例,我们向Elasticsearch索引数据时,只是简单地把JSON文本放在请求体里,至于J ...
- Tensorflow机器学习入门——读取数据
TensorFlow 中可以通过三种方式读取数据: 一.通过feed_dict传递数据: input1 = tf.placeholder(tf.float32) input2 = tf.placeho ...
- springboot~Transactional注解的注意事项
@Transactional注解是为方法添加事务块的意思,使用aop的技术动态为方法添加事务范围,在使用它时可以在类或者方法上添加,但在类上添加时需要注意一下影响的范围. 类中添加Transactio ...