word count的reduce过程以及项目打包部署
map过程已经写完了,上面那个流程我们涉及到了泛型以及序列化,我们要知道每个参数代表的含义,这样有助于我们理解整个流程。
下面我们开始reduce,这个过程我们要把map输出的键值对把key值相同的放在一起,具体的流程我们看代码:
package MR.wc;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Reducer;
import java.io.IOException;
/**
* <KEYIN, VALUEIN, KEYOUT, VALUEOUT>
* KEYIN, VALUEIN这两个参数是map段输出的值,就是之前的key,value键值对(Text, IntWritable)
* KEYOUT, VALUEOUT这两个参数是我们要输出的数据格式,比如(“hello",5),("Hadoop",1)等等等等
* Reduce类中有一个迭代器,会循环获取数据
* */
//继承Reducer类
public class wcReduce extends Reducer<Text, IntWritable,Text,IntWritable> {
/**
* 重写reduce方法
* Text key:就是读取进来的每一个单词(比如:hello)
* Iterable<IntWritable> values hello这个key里面所有的value值(1,1,1,1,1)
* */
@Override
protected void reduce(Text key, Iterable<IntWritable> values, Reducer<Text, IntWritable, Text, IntWritable>.Context context) throws IOException, InterruptedException {
int sum=0;
//对values做迭代累加
for (IntWritable value : values) {
//把IntWritable转成int值累加
sum+=value.get();
}
//通过上下文输出
context.write(key,new IntWritable(sum));
}
}
然后我们再写驱动类,这个类基本是一些固定的写法:
package MR.wc;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import java.io.IOException;
public class wcDriver {
public static void main(String[] args) throws IOException, InterruptedException, ClassNotFoundException {
//设置文件输入路径,也是就我们要读取的那个文本文件路径(第一个参数)
//第二个参数是我们的输出路径
String[] path=new String[]{"/word.txt","/output007"};
//设置配置文件
//获取配置文件对象
Configuration conf = new Configuration();
//这里我们可以使用Windows环境里面的hadoop去运行,但是现在我们先把它放到集群上,所以要先配置集群资源
/**
* 配置conf对象,要根据/opt/module/hadoop-2.8.4/etc/hadoop/core-site.xml 这个文件里面的去配置
* <property>
* <name>fs.defaultFS</name>
* <value>hdfs://bigdata101:9000</value>
* </property>
* */
conf.set("fs.defaultFS","hdfs://bigdata101:9000");//设置集群资源地址
//1,加载任务
Job job = Job.getInstance(conf);
//2,设置任务的驱动类(jar加载路径),通过反射获取
job.setJarByClass(wcDriver.class);
//3,设置map程序信息
job.setMapperClass(wcMapper.class);
job.setMapOutputKeyClass(Text.class);//设置输出的key类型,map阶段的输出key类型
job.setMapOutputValueClass(IntWritable.class);//设置输出的value类型,map阶段输出的value类型
//4,设置reduce程序信息
job.setReducerClass(wcReduce.class);
job.setOutputKeyClass(Text.class);//reduce阶段输出的key类型
job.setMapOutputValueClass(IntWritable.class);// reduce阶段的value类型
//5,设置输入路径和输出路径
FileInputFormat.setInputPaths(job,new Path(path[0]));
FileOutputFormat.setOutputPath(job,new Path(path[1]));
// 6,提交任务
boolean res=job.waitForCompletion(true);
System.exit(res?0:1);
System.out.println(res?"执行成功":"执行失败");
}
}
现在整个流程就写完了。写完以后我们先在集群上跑一下试试效果。先打一个jar包:
IDEA 右边:
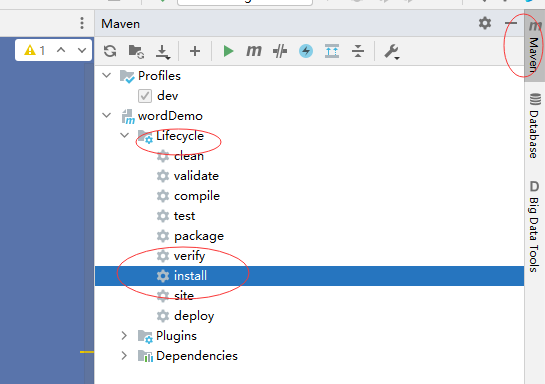
运行完以后我们可以在左边看见打好的jar包:
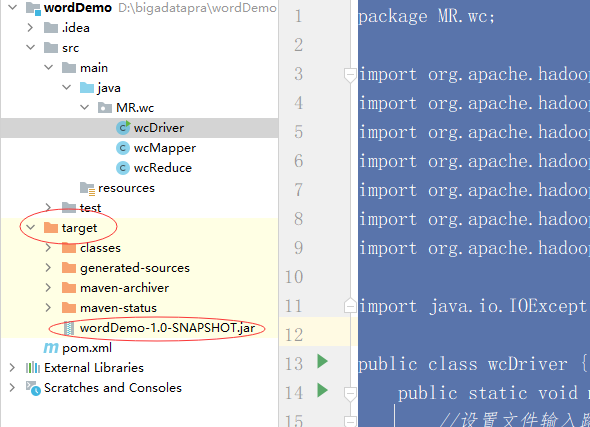
把这个jar包拖到桌面上,改一下名字:wordDemo.jar
然后打开三台虚拟机,在namenode上启动hdfs:start-dfs.sh
在102上启动yarn:start-yarn.sh
启动完毕以后我们先手动建一个文件:vim word.txt
写入数据:
hello world
hello scala
hello spark
hello hadoop
hello mr
保存推出。然后把这个文件放到hdfs根目录上:hdfs dfs -put word.txt /
现在我们把jar包上传到Linux上:
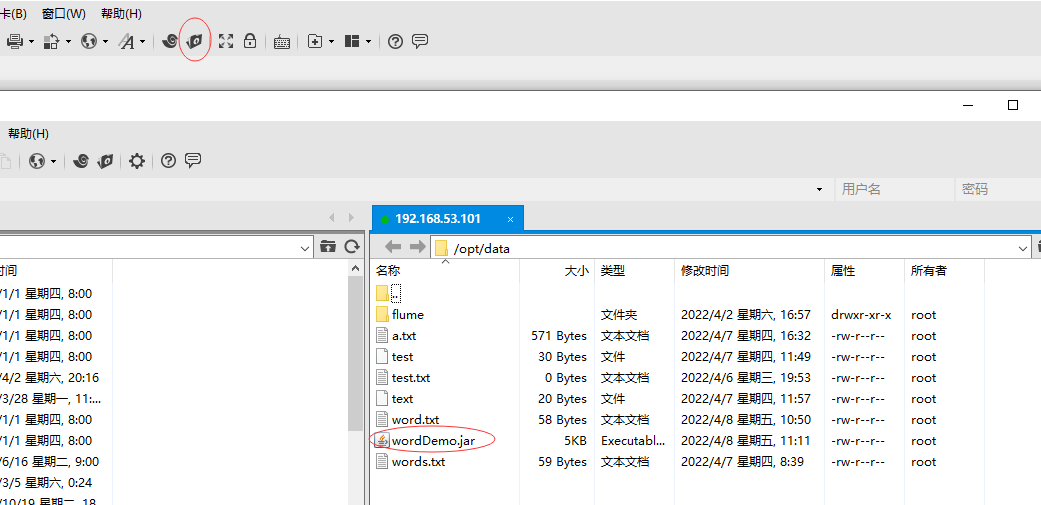
上传完毕以后是这样:
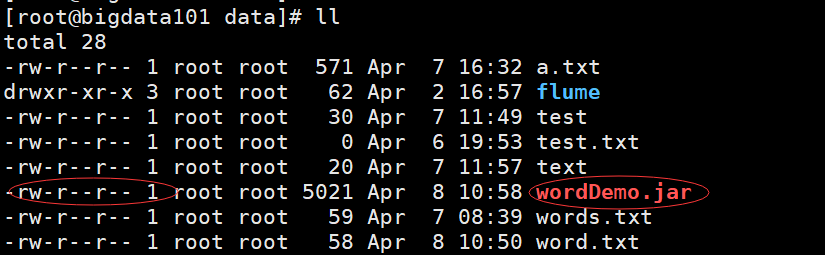
这个文件我们没有执行权限,给他授权:chmod 755 wordDemo.jar
然后就绿了:
绿了以后就可以使用Hadoop命令执行这个文件了,执行的时候我们要用到这个文件驱动的全类名,我们提前把路径复制下来:
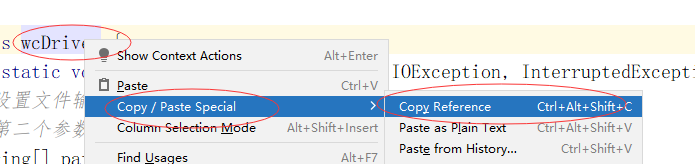
然后执行:hadoop jar wordDemo.jar MR.wc.wcDriver
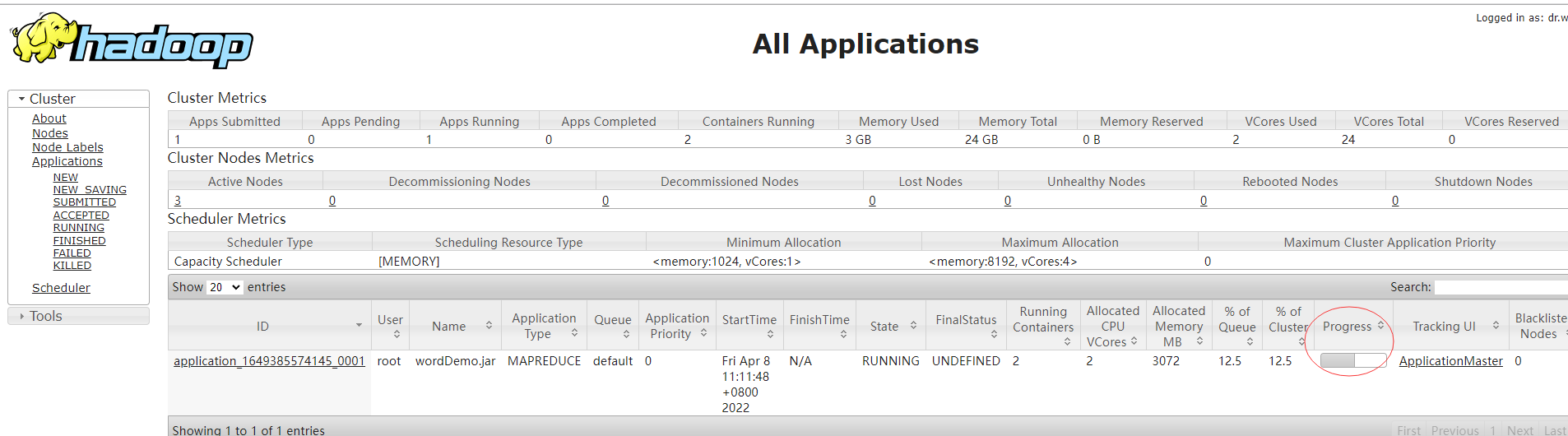
我们打开浏览器,输入yarn的地址:http://192.168.53.102:8088/,可以看见作业运行的信息:
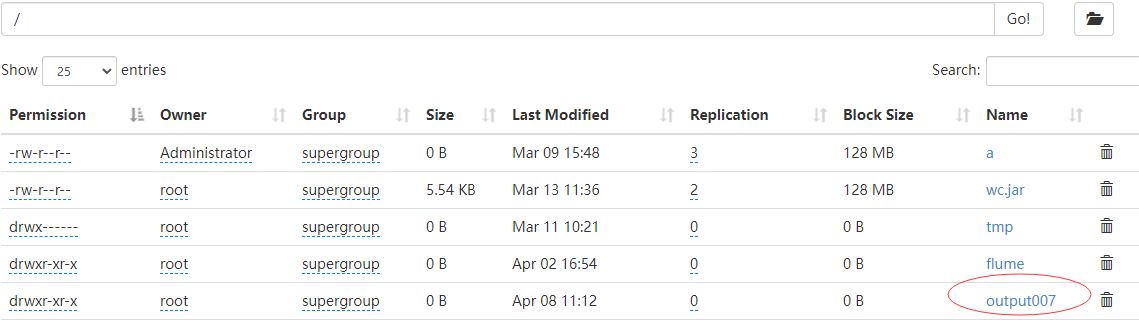
运行完以后,我们再打开一个网页窗口,输入hdfs地址:http://192.168.53.101:50070/,可以看见我们指定的那个文件已经生成了(我们每次运行的时候都会新生成一个文件):
我们给他打开:
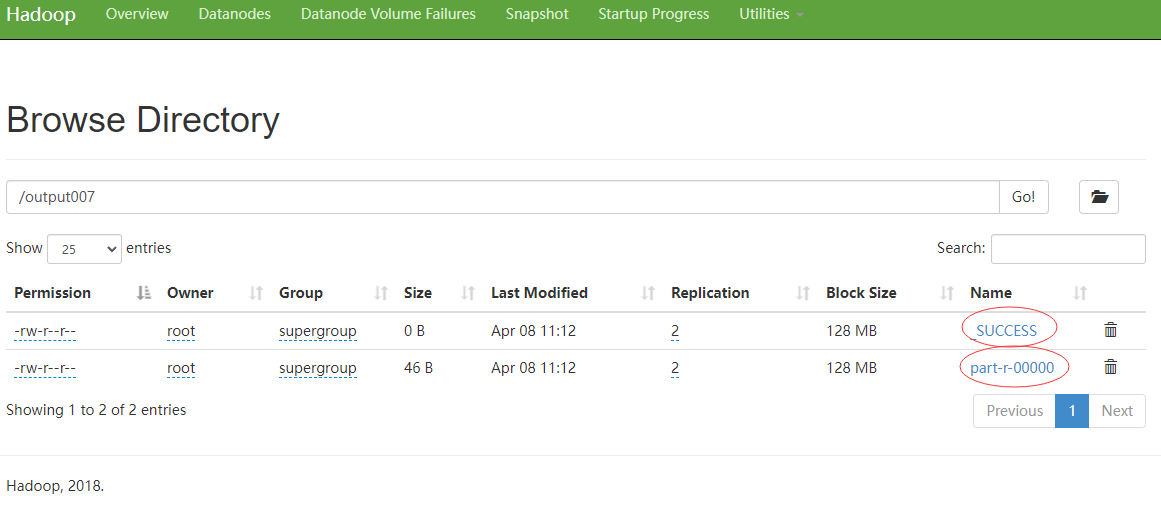
点击part开头的文件:
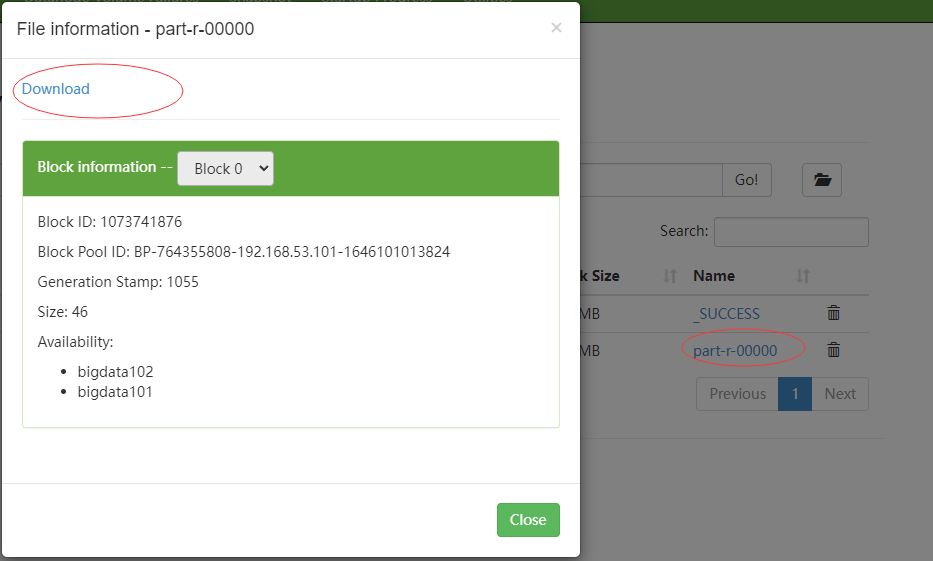
可以把这个文件下载下来,用notepad打开:
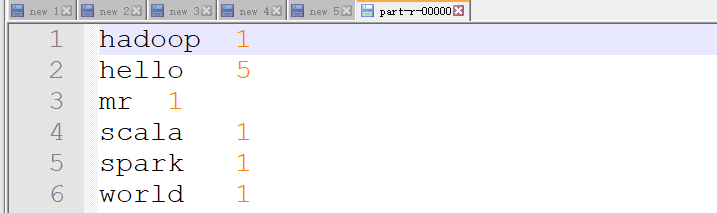
ok,搞定。其实这里就是两个步骤,一个map,一个reduce,当然了,细心的童鞋有可能发现了这个结果还被排序了,我们在代码里面没有看见,不着急,后面会慢慢展开来说。现在对mapreduce过程应该有一个大致的了解了。现在再回去看看那个mapreduce的流程图,会稍微清晰一些。
word count的reduce过程以及项目打包部署的更多相关文章
- Spring Boot + Spring Cloud 实现权限管理系统 后端篇(十四):项目打包部署
项目打包部署 安装MySQL镜像 注意:如果使用docker镜像安装MySQL,也需要在前端部署主机安装MySQL,因为备份还原功能是使用MySQL的本地命令进行操作的. 下载镜像 执行以下命令,拉取 ...
- 【转】vue项目打包部署——nginx代理访问
我又来了,今天部署了下vue项目,使用nginx做了代理,这样可以解决跨域的问题,这里做一个简单讲解. 1.先看vue项目打包(我这里使用的是vscode开发工具) 这里是我的项目结构: 打包之前需要 ...
- vue项目 打包部署上线
1. npm run dev:本地开发的时候做调试用的. 2. npm run build:打包部署上线,生成一个 dist 文件夹. 注意:用 npm run build 时,常遇到因引用路径不对导 ...
- 如何将Spring Boot项目打包部署到外部Tomcat
1.项目打包 项目开发结束后,需要打包部署到外部服务器的Tomcat上,主要有几种方式. (1)生成jar包 cd 项目跟目录(和pom.xml同级)mvn clean package## 或 ...
- java项目打包部署
网上打包的教程很多, 但是自己动手总归出现各种各样的问题,自己总结下: 由于刚刚接触JAVA,做了一个简单的java project 项目, 但是包含第三方的jar包, 结果打包的时候就出现问题了. ...
- vue之项目打包部署到服务器
这是今年的第一篇博客.整理一下vue如何从项目打包到部署服务器,给大家做下分享,希望能给大家带来或多或少的帮助,喜欢的大佬们可以给个小赞,如果有问题也可以一起讨论下. 第一步:这是很关键的一步.打开项 ...
- angular2项目打包部署的坑
1.ng项目打包后,打开index.html,发现页面是空白的,F12查看,发现js和css引入的路径不对 这里要将package.json文件的打包命令改成 ng build --prod --ba ...
- maven项目打包部署到虚拟机测试和生产环境上及查看日志操作
调试通过后提交代码到gitlab,打包部署到相应环境(测试或生产环境)步骤一样1.打包在要打包的项目上右键run as maven clean 清除原来的包,然后run as maven instal ...
- yo angualr-fullstatck 项目打包部署
yoeman使用grunt进行打包部署,直接运行grunt命令即可,期间会对代码进行检查,如果存在不规范的地方jshint会指定出来. grunt会对静态资源进行打包而且对资源文件名进行了MD5作为版 ...
随机推荐
- Flutter网络请求和数据解析
一:前言 - 什么是反射机制,Flutter为什么禁用反射机制? 在Flutter中它的网络请求和数据解析稍微的比较麻烦一点,因为Flutter不支持反射机制.相信大家都看到这么一条,就是Flutte ...
- 好客租房8-React基础阶段总结
React总结 1react是构建用户组件的javascript库 2使用react是,推荐使用脚手架方式 3初始化项目命令:npx create-react-app my-app 4启动项目命令:y ...
- CSP-J游记
祝大家 CSP-J/CSP-S 稳过第一轮 ~(- ∨ -)~ ~~ 建议扩大110%食用 ~~ 中秋快乐鸭(希望大家不会收到损友送的砖头月饼 : − ) :-) :−)) 咳咳,昨天是我们可爱初赛来 ...
- 官方出品,比 mydumper 更快的逻辑备份工具
mysqldump 和 mydumper 是我们常用的两个逻辑备份工具. 无论是 mysqldump 还是 mydumper 都是将备份数据通过 INSERT 的方式写入到备份文件中. 恢复时,myl ...
- MASA Auth - SSO与Identity设计
AAAA AAAA即认证.授权.审计.账号(Authentication.Authorization.Audit.Account).在安全领域我们绕不开的两个问题: 授权过程可靠:让第三方程序能够访问 ...
- JAVA学习之第一个HelloWorld程序
第一个HelloWorld程序 第一步,创建java类型的文件 第二步,在创建文件的目录中打开cmd窗口 第三步,使用javac 命令将java文件编译为.class类型的字节码文件 第四步,使用ja ...
- .NetCore实现图片缩放与裁剪 - 基于ImageSharp
前言 (突然发现断更有段时间了 最近在做博客的时候,需要实现一个类似Lorempixel.LoremPicsum这样的随机图片功能,图片有了,还需要一个根据输入的宽度高度获取图片的功能,由于之前处理图 ...
- 自己封装的tools.js文件
/* * 生成指定范围的随机整数 * @param lower 下限 * @param upper 上限 * @return 返回指定范围的随机整数,上/下限值均可取 */ function rand ...
- weiphp 插件"通用表单"BUG修改
修改文件目录 在类FormsValueController 中添加函数 // 匹配函数 //$value:字符串 //$validate_rule:正则规则 // return true:比配成功,f ...
- idea中enter键不能换行
idea中enter键不能换行 按enter键只能往下移动 如下图 解决办法: 方式一:按住window + Insert 方式二: 按住Fn + Insert 两种方式总有一种可以 之后就可以按en ...