【SQL进阶】【分步写、联合各自排序、TIMESTAMPDIFF时间比较】Day04:多表查询
〇、内容
时间比较2-2
联合结果各自排序
查询列和GROUP BY
一、嵌套子查询
1、月均完成试卷数不小于3的用户爱作答的类别
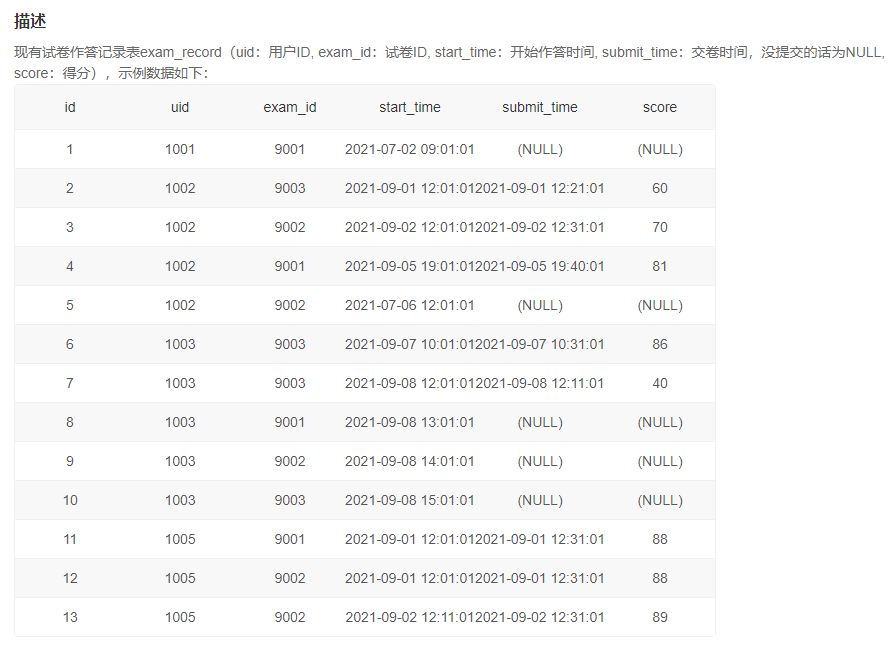
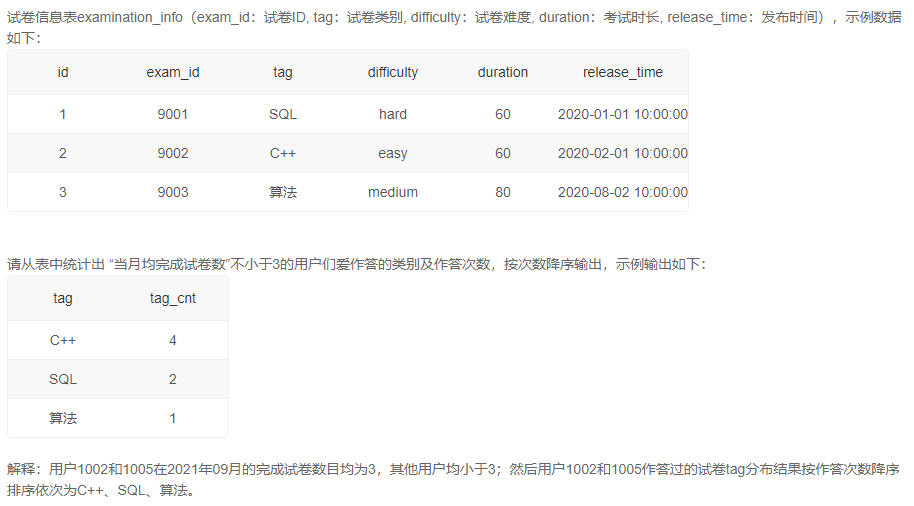
自己的答案【错误】:
SELECT tag,
COUNT(A.start_time) AS tag_cnt
FROM (
-- 查询 “当月均完成试卷数”不小于3的用户们
SELECT *
FROM exam_record
GROUP BY uid
HAVING COUNT(*)>=3
) A
RIGHT JOIN examination_info B
ON A.exam_id=B.exam_id
GROUP BY tag
ORDER BY tag_cnt DESC
答案:【group by的字段一定要出现在查询列中,*不算】
SELECT tag,
COUNT(B.tag) AS tag_cnt
FROM exam_record A
RIGHT JOIN examination_info B
ON A.exam_id=B.exam_id
WHERE uid IN (
SELECT uid
FROM exam_record
GROUP BY uid
-- 统计当前用户完成试卷总数
-- 统计该用户有完成试卷的月份数
HAVING COUNT(submit_time) / COUNT(DISTINCT DATE_FORMAT(submit_time, "%Y%m")) >= 3
)
GROUP BY tag
ORDER BY tag_cnt DESC
2、试卷发布当天作答人数和平均分【☆】
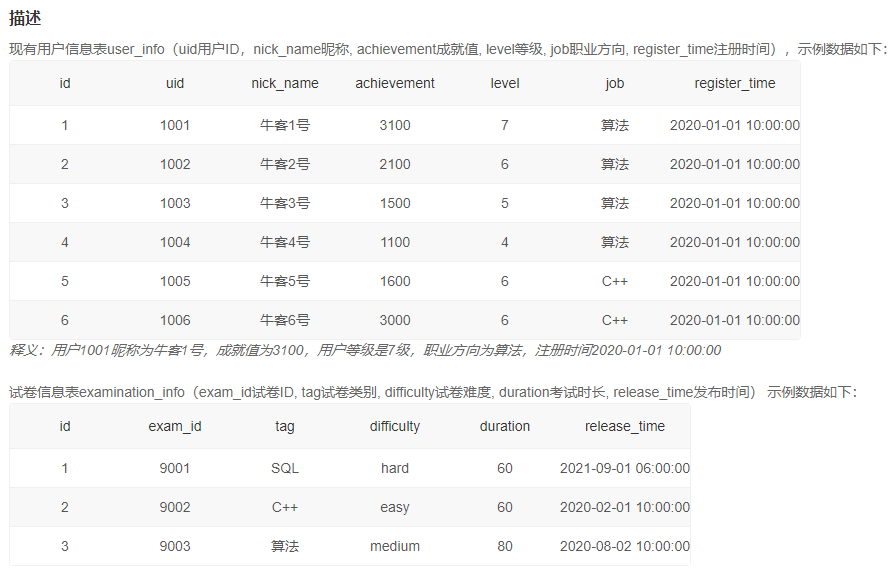
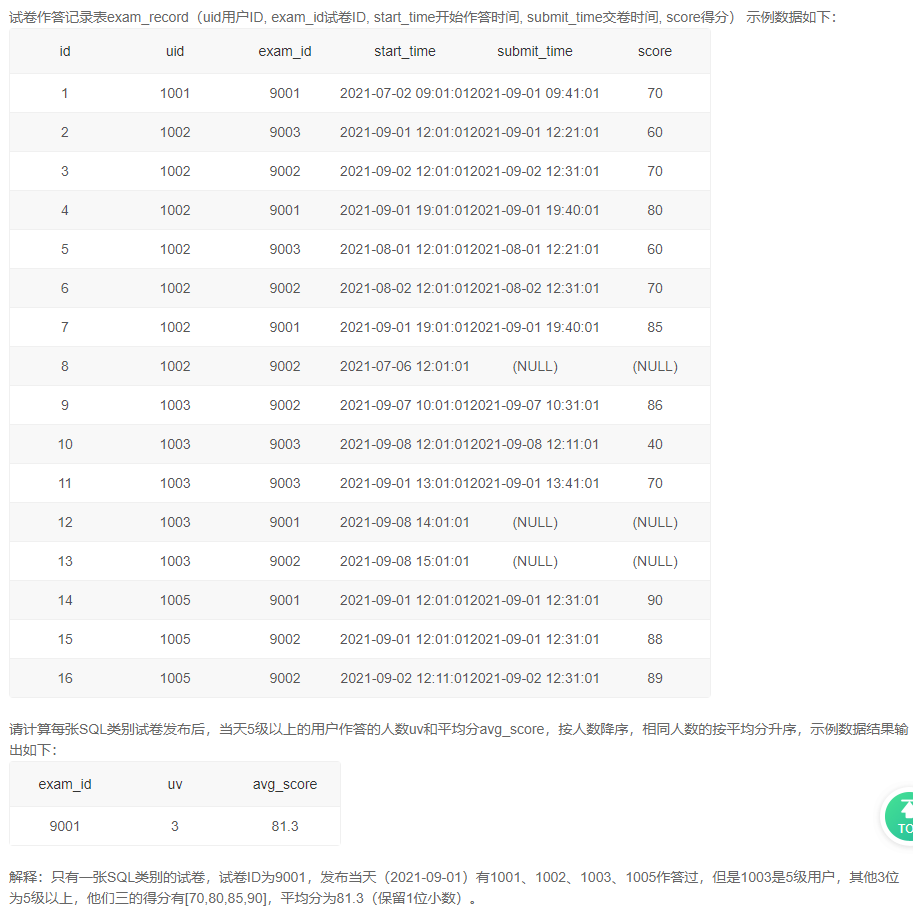
自己的答案【错误】
SELECT
exam_id,
SUM(IF(DATE_FORMAT((submit_time,"%Y%m")==DATE_FORMAT(release_time,"%Y%m") and level>=5,1,0))) AS uv,
ROUND(AVG(score),1) AS avg_score
FROM user_info A
JOIN examination_info
JOIN exam_record
ON
A.uid=C.uid
AND
B.exam_id=C.exam_id
WHERE
tag="SQL"
GROUP BY exam_id
ORDER BY uv DESC,avg_score ASC
正确答案:【判断相等用一个等号】
SELECT
C.exam_id,
COUNT(DISTINCT C.uid) AS uv,
ROUND(AVG(score),1) AS avg_score
FROM user_info A
JOIN examination_info B
JOIN exam_record C
ON
A.uid=C.uid
AND
B.exam_id=C.exam_id
WHERE
tag="SQL"
AND
level>5
AND
DATE(submit_time)=DATE(release_time)
GROUP BY C.exam_id
ORDER BY uv DESC,avg_score ASC
3、作答试卷得分大于过80的人的用户等级分布
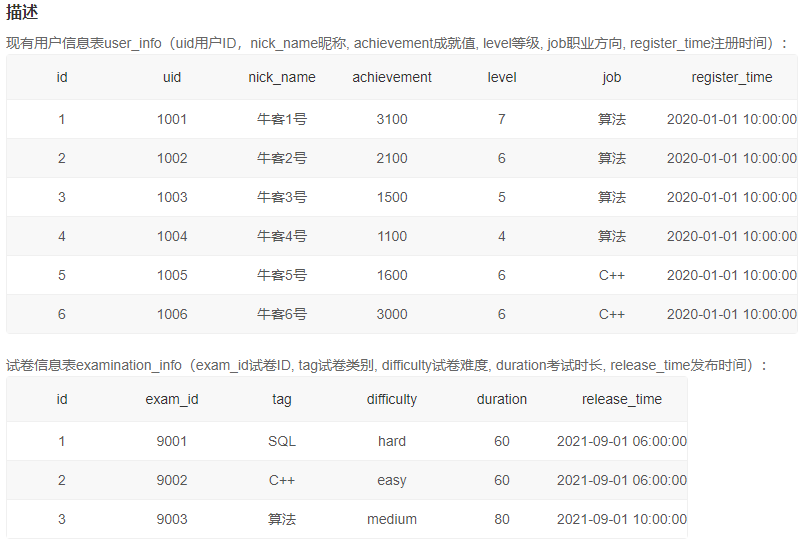
SELECT
level,
COUNT(*) AS level_cnt
FROM user_info A
JOIN examination_info B
JOIN exam_record C
-- NATURAL/FULL/CROSS
ON A.uid=C.uid
AND B.exam_id=C.exam_id
WHERE
tag="SQL"
AND
score>80
GROUP BY level
ORDER BY level_cnt DESC
二、合并查询
1、每个题目和每份试卷被作答的人数和次数
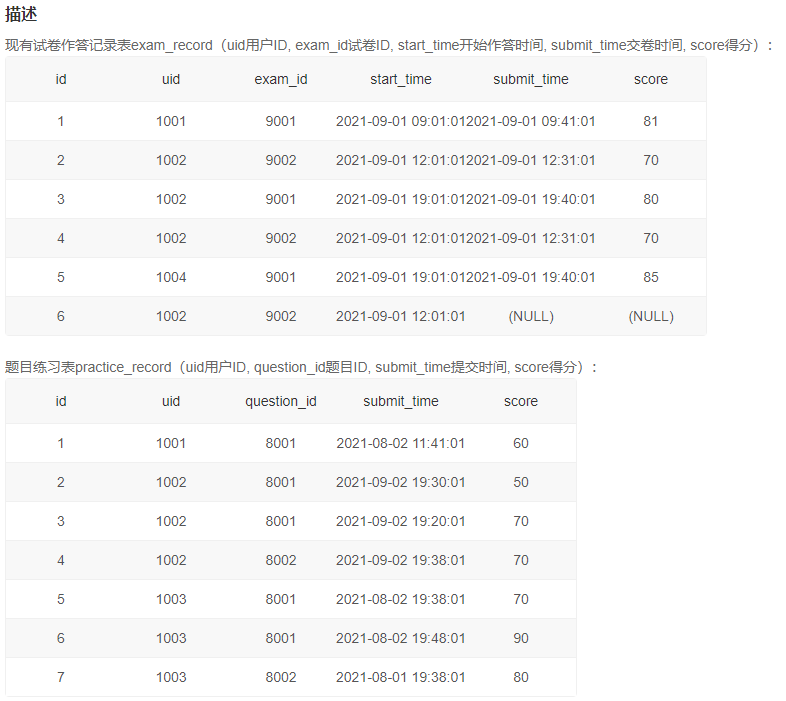
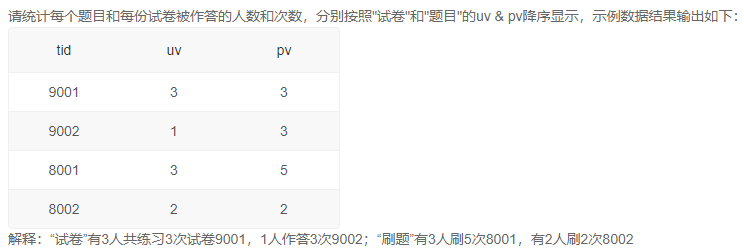
答案:【UNION和ORDER BY混用会被覆盖】
-- order by可以存在 union的字句里面,但是功能不会生效
SELECT * FROM
(SELECT
exam_id AS tid,
COUNT(DISTINCT uid) AS uv,
COUNT(exam_id) AS pv
FROM exam_record
GROUP BY tid
ORDER BY uv DESC,pv DESC) AS A
UNION
SELECT * FROM
(SELECT
question_id AS tid,
COUNT(DISTINCT uid) AS uv,
COUNT(question_id) AS pv
FROM practice_record
GROUP BY tid
ORDER BY uv DESC,pv DESC) AS B
2、分别满足两个活动的人
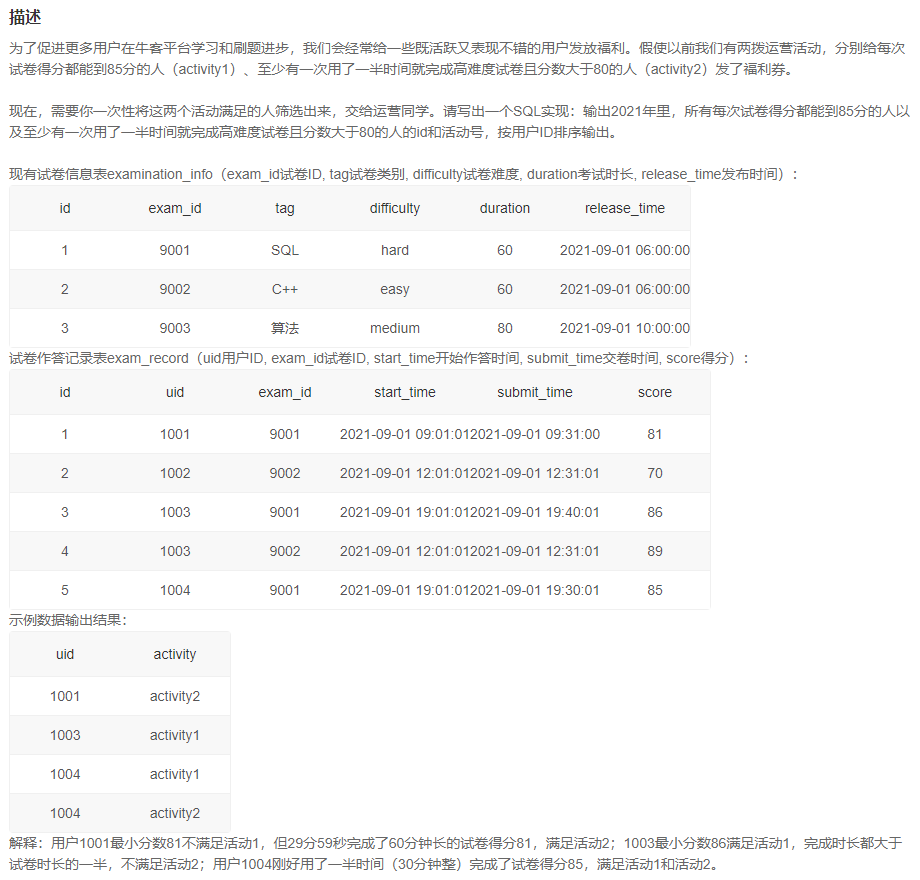
思路:TIMESTAMPDIFF(SECOND,start_time,submit_time)<=duration*30,时间比较用SECOND和TIMESTAMPDIFF
至少有一次不需要聚合函数,在where中即可实现,先查找出符合要求的,再进行分组
全部需要用聚合函数,先分组再having
-- 输出2021年里,所有每次试卷得分都能到85分的人以及至少有一次
-- 用了一半时间就完成高难度试卷且分数大于80的人的id和活动号,按用户ID排序输出。
-- 全部成绩大于85可以用最小成绩>85表示
(SELECT
uid,
"activity1" AS activity
FROM exam_record
GROUP BY uid
HAVING MIN(score)>=85)
UNION ALL
(SELECT
uid,
"activity2" AS activity
FROM exam_record B
LEFT JOIN examination_info A
ON A.exam_id=B.exam_id
WHERE
TIMESTAMPDIFF(SECOND,start_time,submit_time)<=duration*30
AND
score>=80
AND
difficulty="hard"
GROUP BY uid)
ORDER BY uid
三、连接查询
1、满足条件的用户的试卷完成数和题目练习数
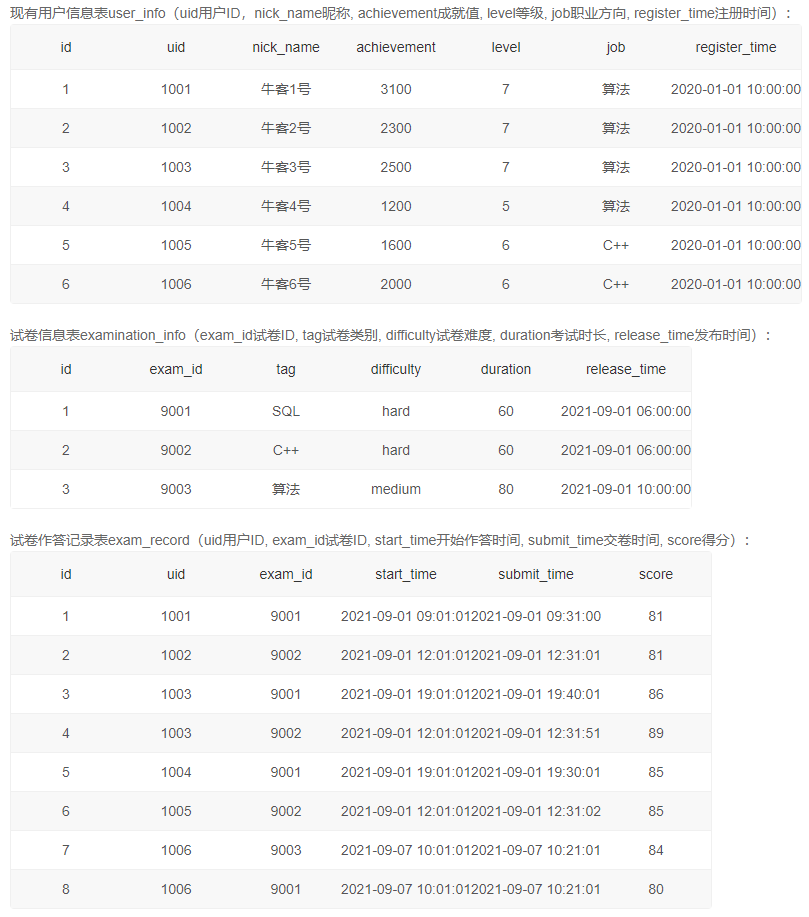
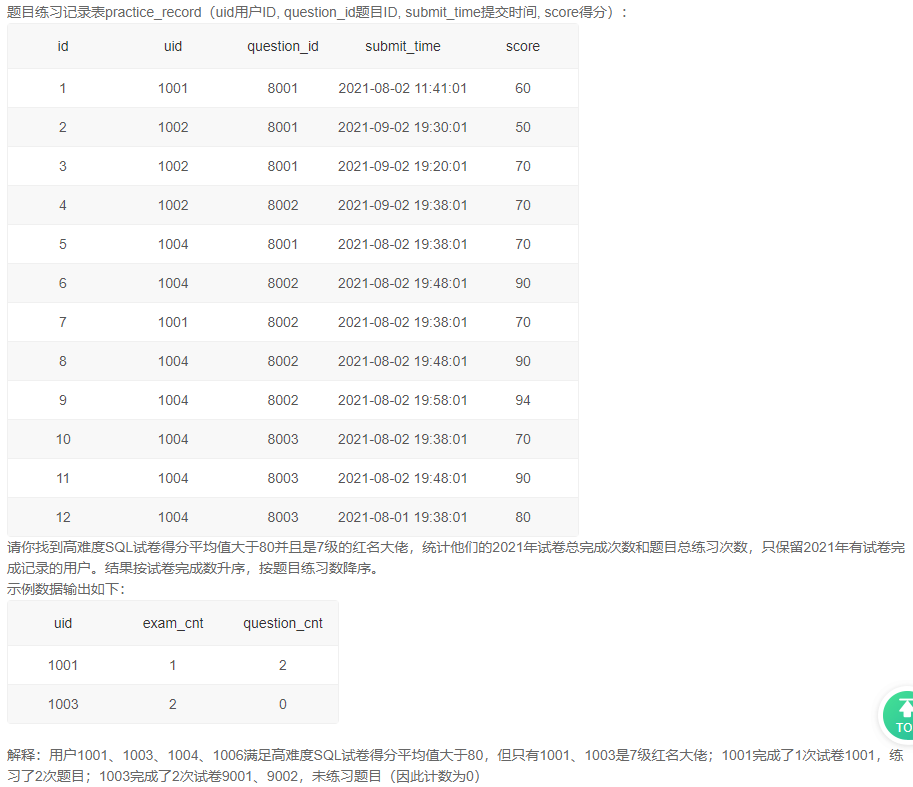
自己的写法【错误】
SELECT
A.uid,
COUNT(DISTINCT C.uid) AS exam_cnt,
COUNT(DISTINCT D.uid) AS question_cnt
FROM user_info A
JOIN examination_info B
JOIN exam_record C
JOIN practice_record D
ON
A.uid=C.uid
AND
A.uid=D.uid
AND
B.exam_id=C.exam_id
WHERE
level=7
AND
tag="SQL"
AND
difficulty="hard"
AND
(YEAR(C.submit_time)=2021
OR
YEAR(D.submit_time)=2021)
GROUP BY A.uid
HAVING -- 子句不能出现year
AVG(C.score)>80
ORDER BY exam_cnt ASC,question_cnt DESC
答案:
-- 先分别写出2021年分组后的试卷完成情况和题目练习情况
-- 再查询出高难度SQL试卷得分平均值大于80并且是7级的红名大佬
select
uid,
exam_cnt,
if(question_cnt is null, 0, question_cnt)
from
(select
uid,
count(submit_time) as exam_cnt
from exam_record
where YEAR(submit_time) = 2021
group by uid) t left join (select
uid,
count(submit_time) as question_cnt
from practice_record
where YEAR(submit_time) = 2021
group by uid) t2 using(uid) where uid in
(
select
uid
from exam_record
join examination_info using(exam_id)
join user_info using(uid)
where tag = 'SQL' and difficulty = 'hard' and `level` = 7
group by uid
having avg(score) >= 80
)
order by exam_cnt asc, question_cnt desc
2、每个6/7级用户活跃情况
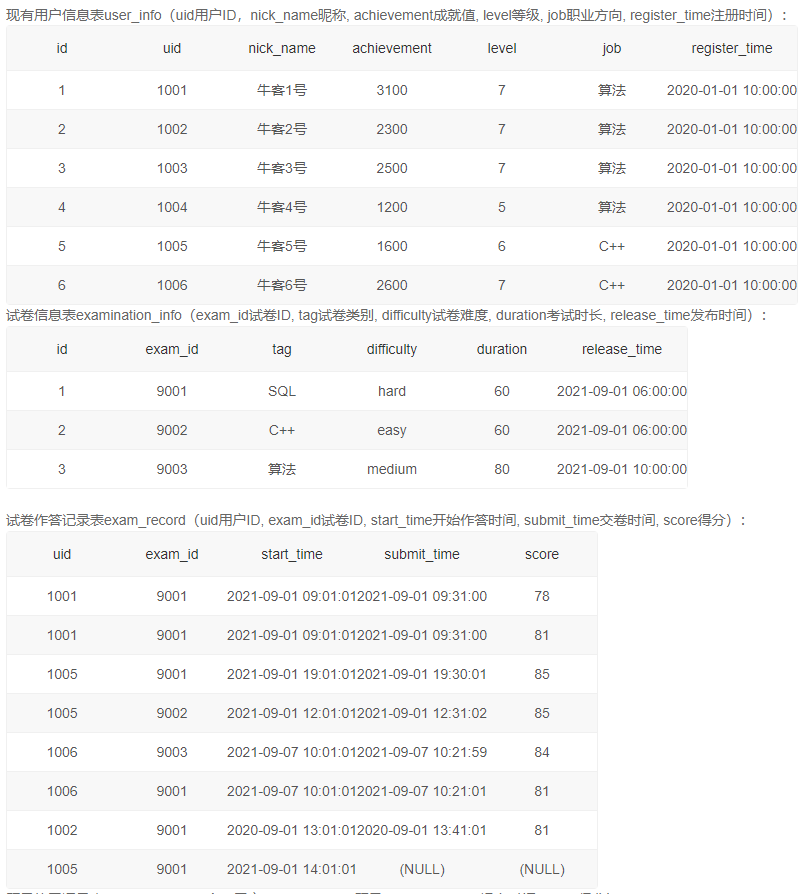
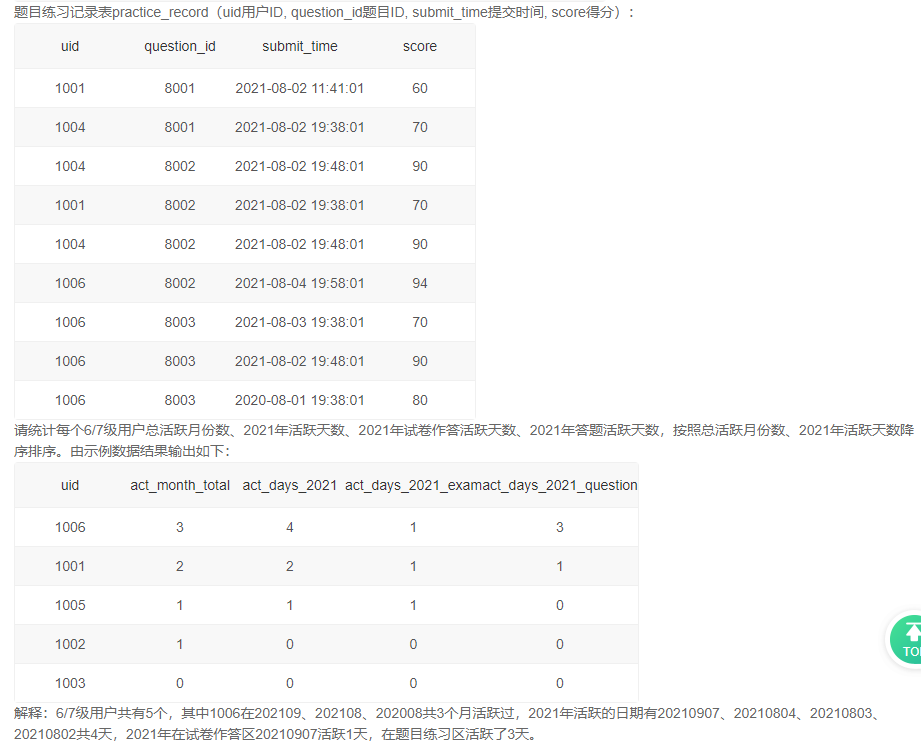
自己分步写的:
-- 查询出6/7级用户
SELECT
uid
FROM user_info
WHERE
level=6
OR
level=7 -- 查询总活跃月份数
SELECT
uid,
COUNT(DISTINCT act_month) AS act_month_total
FROM
(SELECT
uid,
DATE_FORMAT(start_time,"%Y%m") AS act_month
FROM exam_record
UNION ALL
SELECT
uid,
DATE_FORMAT(submit_time,"%Y%m") AS act_month
FROM practice_record) t1
GROUP BY uid -- 查询2021年活跃天数(UNION?)
SELECT
uid,
COUNT(DISTINCT act_days) AS act_days_2021
FROM
((SELECT
uid,
DATE(start_time) AS act_days
FROM exam_record
WHERE
YEAR(start_time)=2021)
UNION ALL
(SELECT
uid,
DATE(submit_time) AS act_days
FROM practice_record
WHERE
YEAR(submit_time)=2021)) t1
GROUP BY uid -- 查询试卷作答活跃天数
SELECT
uid,
COUNT(DISTINCT DATE(start_time)) AS act_month_total
FROM exam_record
WHERE YEAR(start_time)=2021
GROUP BY uid -- 2021年答题活跃天数
SELECT
uid,
COUNT(DISTINCT DATE(submit_time)) AS act_month_total
FROM practice_record
WHERE YEAR(submit_time)=2021
GROUP BY uid
答案:
select
ui.uid,
count(distinct left(s,6)) as act_month_total,
count(distinct if(left(s,4)='2021',right(s,4),null)) as act_days_2021,
count(distinct if(left(s,4)='2021' and tag='e',right(s,4),null)) as act_days_2021_exam,
count(distinct if(left(s,4)='2021' and tag='p',right(s,4),null)) as act_days_2021_question
from (
select uid,DATE_FORMAT(submit_time,'%Y%m%d') as s,'p' tag from practice_record pr
union all
SELECT uid,DATE_FORMAT(start_time,'%Y%m%d') as s,'e' as tag from exam_record er
)mon
right join user_info ui
on ui.uid = mon.uid
where ui.level >5
group by uid
order by act_month_total DESC,act_days_2021 desc
【SQL进阶】【分步写、联合各自排序、TIMESTAMPDIFF时间比较】Day04:多表查询的更多相关文章
- 《SQL 进阶教程》 自连接分组排序:练习题1-2-2
分组排序 SELECT d1.district, d1. NAME, (SELECT COUNT(d2.price) FROM district_products d2 WHERE d2.price ...
- SQLYog执行SQL脚本提示:错误代码: 1067 - Invalid default value for '数据库表'查询:解决办法
强烈建议:完全卸载当前版本MySQL,重新安装5.6及以上版本 完全卸载方法:https://jingyan.baidu.com/article/3d69c551611290f0ce02d77b.ht ...
- 《SQL基础教程》+ 《SQL进阶教程》 学习笔记
写在前面:本文主要注重 SQL 的理论.主流覆盖的功能范围及其基本语法/用法.至于详细的 SQL 语法/用法,因为每家 DBMS 都有些许不同,我会在以后专门介绍某款DBMS(例如 PostgreSQ ...
- 【SQL进阶】03.执行计划之旅1 - 初探
听到大牛们说执行计划,总是很惶恐,是对知识的缺乏的惶恐,所以必须得学习执行计划,以减少对这一块知识的惶恐,下面是对执行计划的第一讲-理解执行计划. 本系列[T-SQL]主要是针对T-SQL的总结. S ...
- MySQL:SQL进阶
一.数据库相关理论 1.系统数据库 information_schema: 虚拟库,不占用磁盘空间,存储的是数据库启动后的一些参数,如用户表信息.列信息.权限信息.字符信息等performance_s ...
- mysql基础sql进阶
回顾前面的基础命令语句 修改数据表 添加字段: alter table 表名 add 字段名 列类型[not null|null][primary key][unique][auto_incremen ...
- SQL优化之SQL 进阶技巧(上)
由于工作需要,最近做了很多 BI 取数的工作,需要用到一些比较高级的 SQL 技巧,总结了一下工作中用到的一些比较骚的进阶技巧,特此记录一下,以方便自己查阅,主要目录如下: SQL 的书写规范 SQL ...
- SQL进阶随笔--case用法(一)
SQL进阶一整个是根据我看了pdf版本的整理以及自己的见解整理.后期也方便我自己查看和复习. CASE 表达式 CASE 表达式是从 SQL-92 标准开始被引入的.可能因为它是相对较新的技术,所以尽 ...
- SQL进阶语法的多表操作
AS别名 多张表联合操作,如果表多,字段名长,不方便阅读.这里我们可以使用 as 关键字来对字段名设置别名. as也可以省略,看个人喜好,在这里我还是支持把 as 写上,这样我们在面对复杂的SQL ...
- SQL优化之SQL 进阶技巧(下)
上文( SQL优化之SQL 进阶技巧(上) )我们简述了 SQL 的一些进阶技巧,一些朋友觉得不过瘾,我们继续来下篇,再送你 10 个技巧 一. 使用延迟查询优化 limit [offset], [r ...
随机推荐
- 源码安装最新版keepalived,剥离日志出来并配置日志轮询
安装 yum install -y gcc openssl-devel popt-devel ipvsadm libnl3-devel net-snmp-devel libnl libnl-devel ...
- Notebook交互式完成目标检测任务
摘要:本文将介绍一种在Notebook中进行算法开发的新方式,新手也能够快速训练自己的模型. 目标检测是计算机视觉中非常常用且基础的任务,但是由于目标检测任务的复杂性,往往令新手望而却步.本文将介绍一 ...
- 适用于移动端、PC 端 Vue.js 图片预览插件
1.安装:npm install --save vue-picture-preview 2.使用: (1)入口文件中main.js中全局引入: import Vue from 'vue' import ...
- 220514 T1 查询 (二分查找+vector)
用vector记录每个数出现的位置,对于要查询的X,要找他落在L~R的个数有几个,用lower_bound和upper_bound查找,相减就是答案. 1 #include<bits/stdc+ ...
- java中的自动拆装箱与缓存(Java核心技术阅读笔记)
最近在读<深入理解java核心技术>,对于里面比较重要的知识点做一个记录! 众所周知,Java是一个面向对象的语言,而java中的基本数据类型却不是面向对象的!为了解决这个问题,Java为 ...
- python今日分享(内置方法)
目录 一.习题详解 二.数据类型的内置方法理论 三.整型相关操作 四.浮点型相关操作 五.字符串相关操作 六.列表相关操作 今日详解 一.习题详解 1.计算1-100所有数据之和 all_num = ...
- sql语句优化小结
sql的优化技巧. 1.用join进行子查询的优化. 低效的子查询 select a.user_name,a.over,(select over from user2 b where a.user_n ...
- Mysql编程中遇到的小错误
我在mysql中创建的数据库表语句为如下 create table grade (id int not null, name varchar(255), desc varchar(255), prim ...
- Go_gin权限验证
权限管理 Casbin是用于Golang项目的功能强大且高效的开源访问控制库. 1. 特征 Casbin的作用: 以经典{subject, object, action}形式或您定义的自定义形式实施策 ...
- prometheus监控实战
第一节.环境和软件版本 1.1.操作系统环境 主机ip 操作系统 部署软件 备注 192.168.10.10 Centos7.9 Grafana.Pushgateway.Blackbox Export ...