《机器学习实战(基于scikit-learn和TensorFlow)》第四章内容的学习心得
本章主要讲训练模型的方法。
线性回归模型
- 闭式方程:直接计算最适合训练集的模型参数
- 梯度下降:逐渐调整模型参数直到训练集上的成本函数调至最低,最终趋同与第一种方法计算出的参数
首先,给出线性回归模型的预测公式

将上述公式向量化

当公式存在后,我们由于需要最优参数,因此需要成本函数。线性回归模型一般的成本函数是RMSE或者MSE,这里用MSE

然后,开始求优。
1、使用标准方程(闭式解或者叫公式解)

这个变化是根据线性代数中的矩阵求逆以及相关运算求出的一个公式,要注意,这里的X是一个全数据的矩阵,行为特征数,列为训练集数量。
通过上述理论,给出代码进行求解:
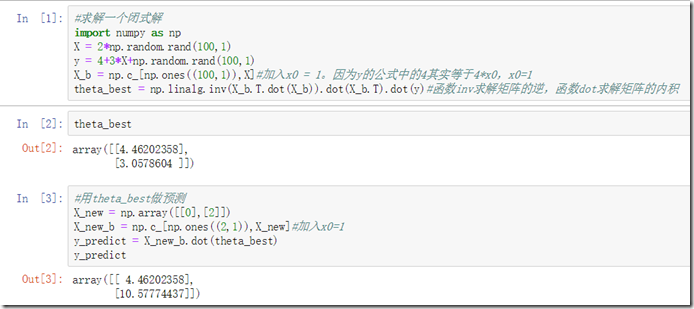
代码中首先随机生成数据集并添加噪声,然后通过闭式解求出参数集,然后进行预测。
绘制结果
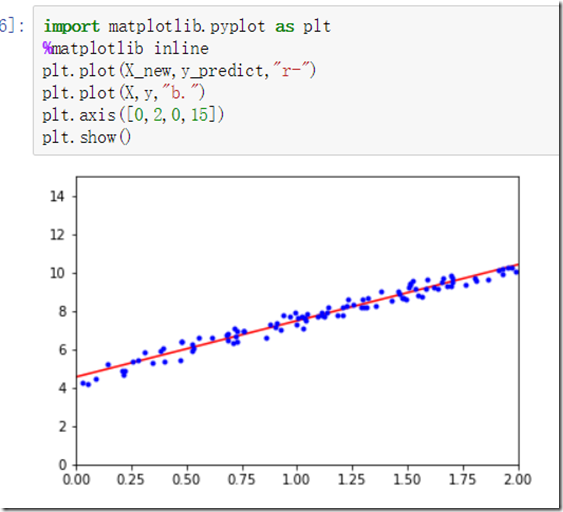
注意,使用标准方程时,一般来说特征数量越多矩阵求逆运算越复杂,计算复杂度越高,更加不容易求解,但是好处是当求出来后,预测很快。
2、梯度下降
具体来说,就是迭代调整参数,使得成本函数最小化。
首先,使用一个随机的θ值,然后逐步让θ变化,使得更加靠近我们的目标,直到算法收敛到一个最小值。
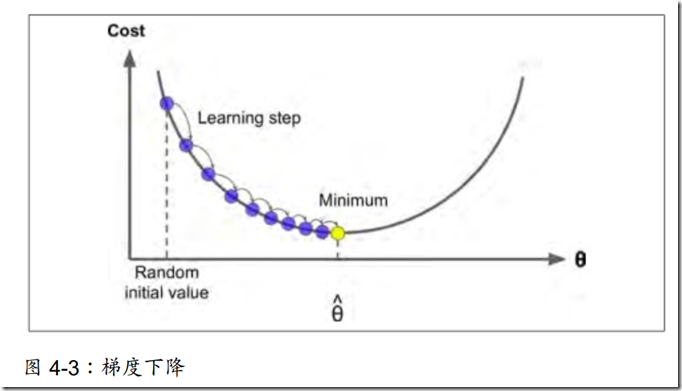
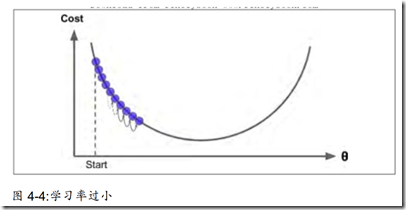
在这个方法中,θ值的取值很关键,因为它代表步长,过大可能算法不能收敛,导致发散,过小,会导致算法收敛速度变慢。
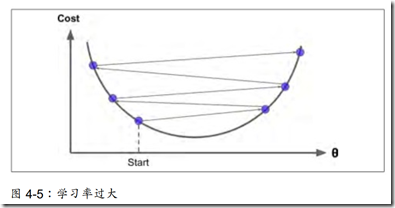
梯度下降在非凸函数中,可能会收敛到一个局部最优值,而在凸函数中会收敛到全局最优。
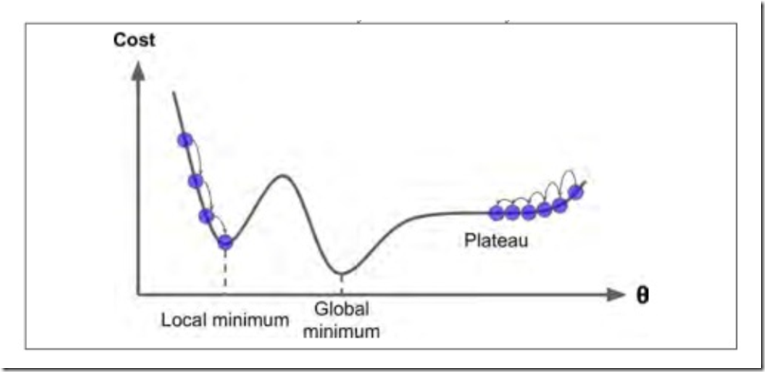
梯度下降速度与参数的大小也有关系
梯度下降需要计算公式的梯度,我们当然需要计算成本函数关于参数θ的偏导数

这里有三个变种,分别是
- 批量梯度下降
- 随机梯度下降
- 小批量梯度下降
批量梯度下降
批量梯度下降最关键的是一次计算使用全部的训练函数进行,采用线性代数中的矩阵计算实现。

每一个的θ都是通过全部的训练函数计算出来。最后生成参数的梯度向量。
梯度下降的更新公式:

代码:
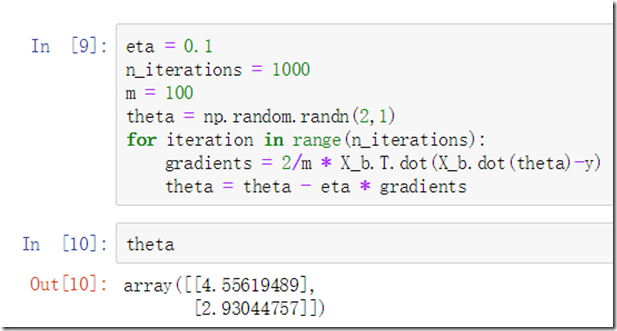
可以发现,预测结果与之前的标准方程基本一致。
这里注意:可以通过网格搜索确定学习率θ,限制迭代次数。
随机梯度下降
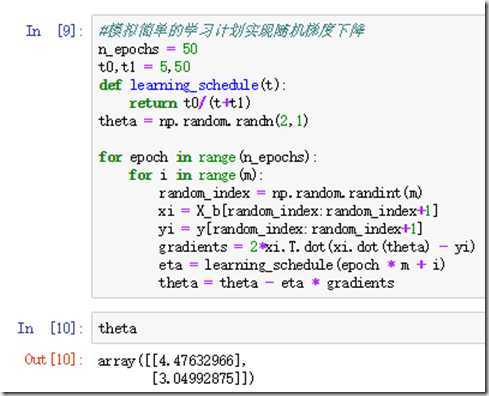
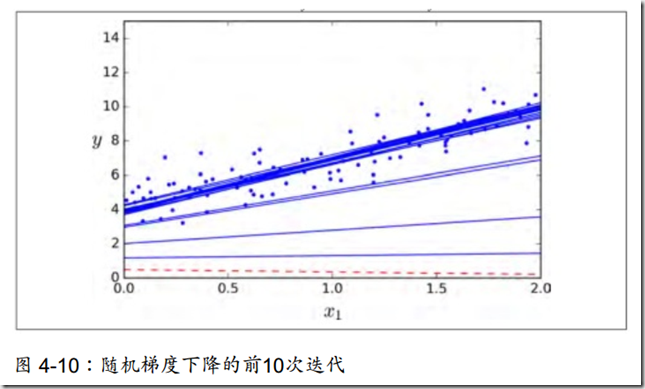
随机梯度下降的关键是随机二字,在操作的时候,随机选取一个训练集上的数据,根据之前的梯度公式给出相应的偏导数,然后用该偏导数去更新全部的参数θ。随机梯度下降的最大的优势在于计算非常迅速,每次更新都是基于单个实例。
当然,有利就有弊,随机梯度下降的成本函数的图像是不断上上下下的,它的下降不规则,但总体趋势一定是下降的。但即使达到了最小值,依旧还会不断的反弹,永远不会停止。
随机梯度下降还有一个比较好的优势在于它比批量梯度下降更加的能找到全局最优值,因为它的不规则性,它比批量梯度下降更加能够跳出局部最小值,但永远定位不到最小值。
一般采取的策略是模拟退火,意思是刚开始步长可以设置的稍大,然后将步长越来越小,让算法接近全局最小值。
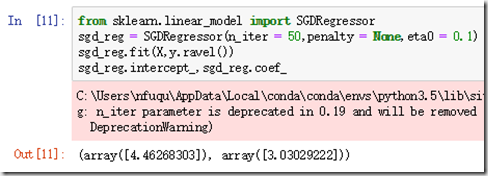
这里的SGDRegressor类中,默认的优化的成本函数是平方误差。
小批量梯度下降
是批量梯度下降的简化形式,主要是通过小批量的训练集数据进行参数更新,这样做的好处是能够在矩阵运算的硬件优化中获得显著的性能提升。当然,小批量梯度下降在同等的条件下,能比随机梯度下降更加接近最小值。
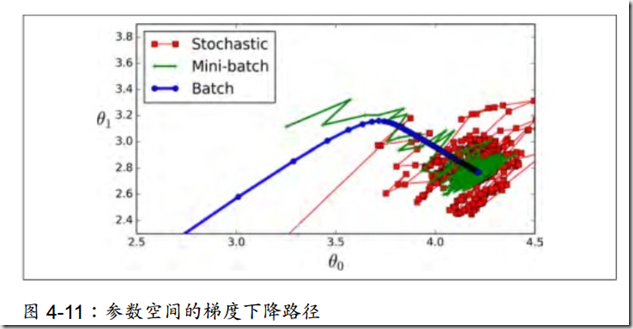
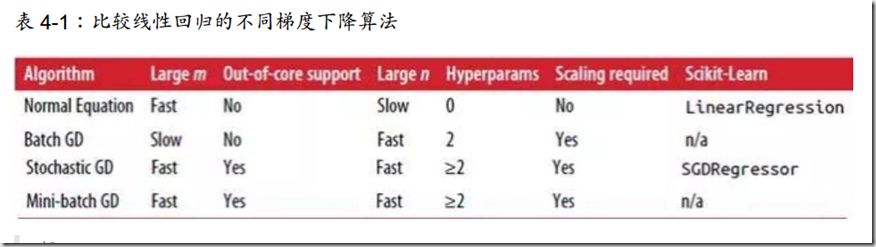
三者比较
多项式回归模型
这种模型是在线性模型的基础上,为每个特征的幂次方作为一个新特征添加,然后在这个拓展的训练集上训练。
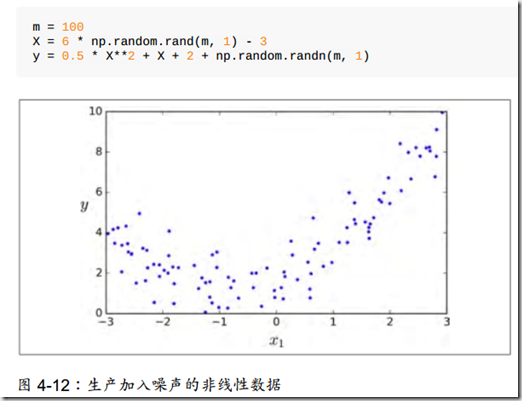
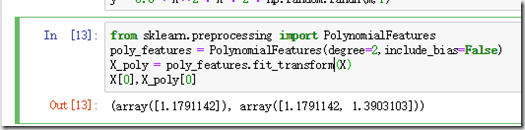
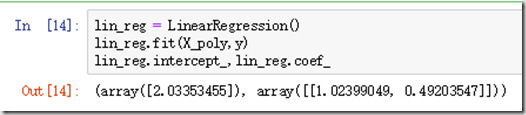
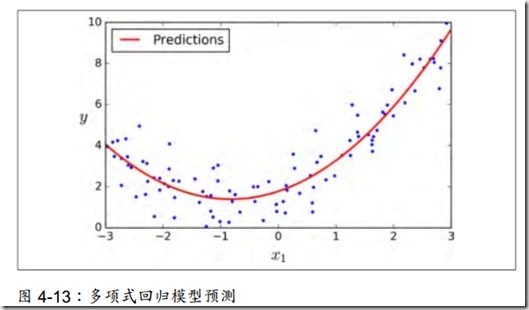
我们可以发现,模型的预测效果比线性要好。
这里注意:特征的数量越多,组合的特征就越多,就会存在爆炸的情况,因此在操作PolynomialFeatures(degree=d)这个类时,一定注意控制计算的大小!
学习曲线
我们训练集训练出的模型,最佳的性能是拥有对其他测试集数据的泛化能力,因此要求我们的模型要拟合训练集上的数据要充足且不能过拟合。
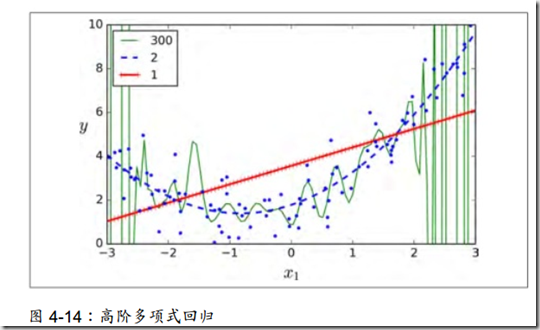
通过图像能够发现,数据在线性回归中没有很好的拟合数据,是欠拟合,在高阶(300)多项式中被过拟合,在2次回归中是较好拟合,因此把握回归的度是一个关键。
我们可以观察学习曲线,即画出模型在训练集上的表现,同时画出以训练集规模为自变量的训练集的图像曲线。
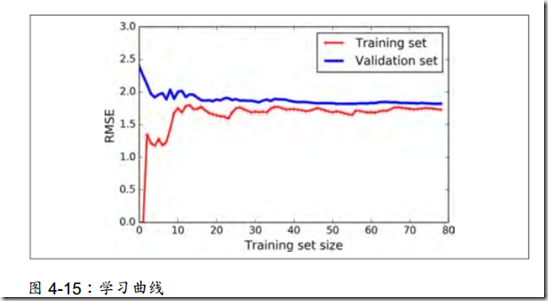

注意:如果模型再怎么训练都不能很好的拟合数据,说明模型本身能力较弱,无法适应当前任务,需要更换复杂度更高的模型去处理。
在学习曲线中,如果训练集的结果比验证集好,说明模型还是存在过拟合的现象,我们最终想看到的是两条曲线的重合或者几乎重合,能做的方法有提供更多的训练数据。
方差、偏差与不可约误差
偏差:泛化误差的这部分误差是由于错误的假设决定的。例如实际是一个二次模型,你却假设了一个线性模型。一个高偏差的模型最容易出现欠拟合。
方差:这部分误差是由于模型对训练数据的微小变化较为敏感,一个多自由度的模型更容易有高的方差(例如一个高阶多项式模型)
,因此会导致模型过拟合。
不可约误差:这部分误差是由于数据本身的噪声决定的。降低这部分误差的唯一方法就是进行数据清洗(例如:修复数据源,修复坏的传感器,识别和剔除异常
值)
。
解决过拟合问题——正则化
我们要懂得一个规则,就是模型拥有越少的自由度,就越难拟合数据,过拟合的情况发生的概率就会越少。
四个正则化方式:
- 岭回归
- 套索回归
- 弹性网络
- 早期停止法
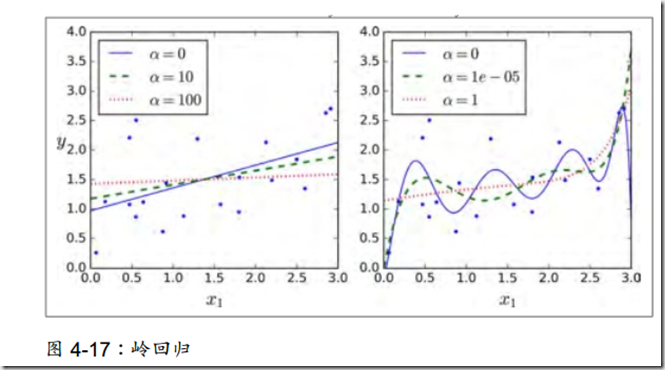
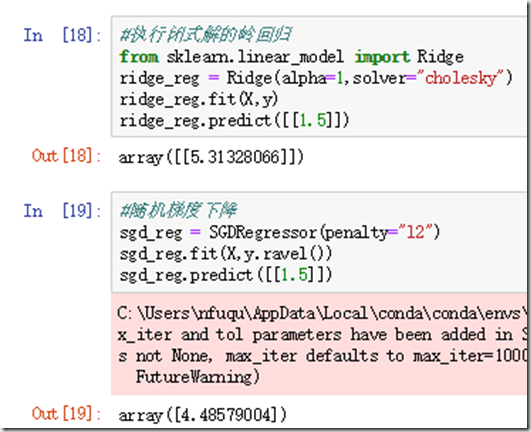
1、岭回归
方法就是在损失函数的尾部直接加上一个正则化项: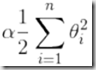 。
。

超参数α控制着惩罚的轻重,过小则正则化的约束能力变弱,过大则约束力太强,模型失去意义。
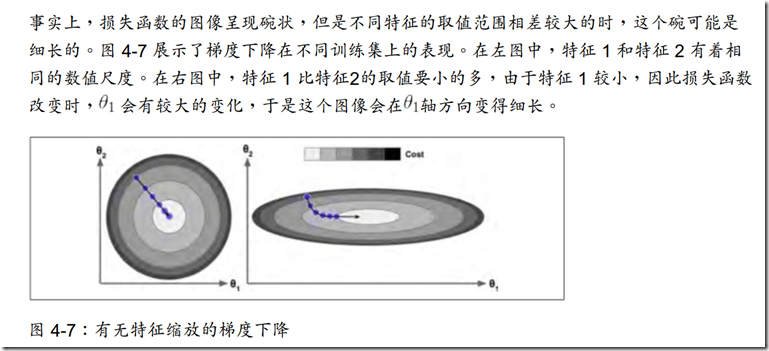
注意:使用岭回归前,对数据进行放缩(可以使用 StandardScaler ) 是非常重要的,算法对于输入特征的数值尺度(scale) 非常敏感。

2、套索回归
与岭回归很相似,但这里使用的正则项是l1范数。
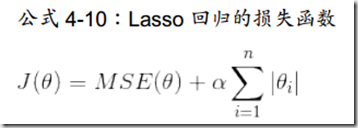
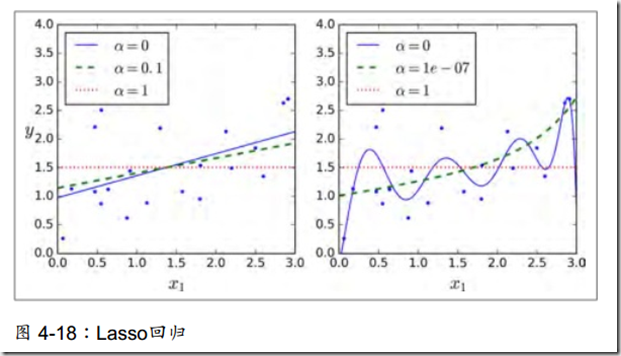
这个正则化有个好处,在于它倾向于将不重要的特征权重设置为0。
还要注意的是,由于某些θ值设置为0,因此在该处是不允许求偏导的,需要子梯度向量
3、弹性网络

超参数r是控制弹性的标准,r=1就是套索回归,r=0就是岭回归。
4、早期停止法
方法即为观察预测误差下降到最低点时,停止训练,并将该时候的训练模型作为最佳模型使用。
注意:随机梯度下降或小批量梯度下降中,由于不是平滑曲线,因此需要误差曲线高于最小值一段时间后再回滚到最小值对应的最佳模型上。
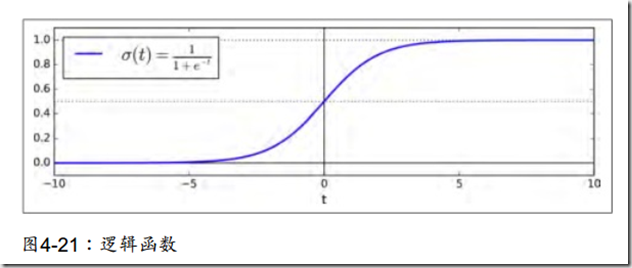
逻辑回归模型
Logistic 回归(也称为 Logit
回归)
通常用于估计一个实例属于某个特定类别的概率 。

 是sigmoid函数。
是sigmoid函数。
其单个样本的损失函数为:


这里需要用梯度下降的方式将参数确定,并没有公式解。
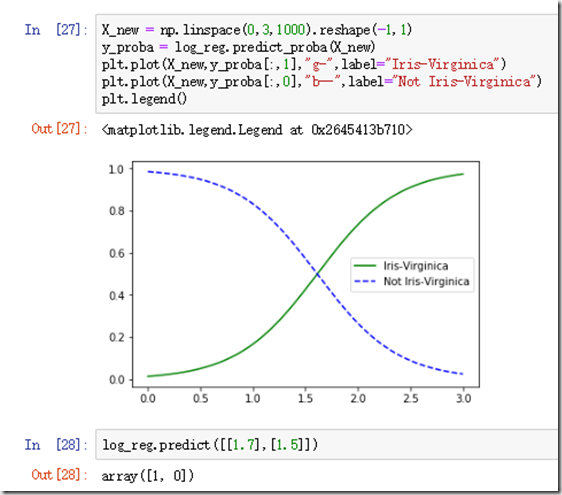
下面代码给出对于某类型花的逻辑回归分类器
softmax回归模型
思路:当给定一个实例 时,Softmax 回归模型首先计算 类的分数 ,然后将分数应用在 Softmax 函数(也称为归一化指数) 上,估计出每类的概率。



它的成本函数表示为


通过计算每个类别的梯度向量,使用梯度下降找到合适的θ。
用softmax进行分类花种类的划分:
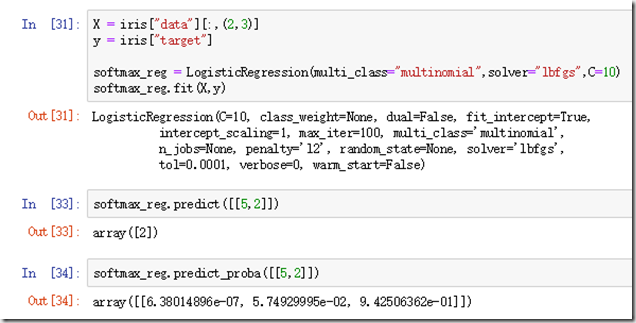
对于softmax最后我的理解就是一个归一化操作,寻找一个得分最高的类别作为预测类别。
《机器学习实战(基于scikit-learn和TensorFlow)》第四章内容的学习心得的更多相关文章
- 《机器学习实战(基于scikit-learn和TensorFlow)》第三章内容的学习心得
本章主要讲关于分类的一些机器学习知识点.我会按照以下关键点来总结自己的学习心得:(本文源码在文末,请自行获取) 什么是MNIST数据集 二分类 二分类的性能评估与权衡 从二元分类到多类别分类 错误分析 ...
- 《机器学习实战(基于scikit-learn和TensorFlow)》第二章内容的学习心得
请支持正版图书, 购买链接 下方内容里面很多链接需要我们***,请大家自备梯子,实在不会再请留言,节约彼此时间. 源码在底部,请自行获取,谢谢! 当开始着手进行一个端到端的机器学习项目,大致需要以下几 ...
- 分享《机器学习实战基于Scikit-Learn和TensorFlow》中英文PDF源代码+《深度学习之TensorFlow入门原理与进阶实战》PDF+源代码
下载:https://pan.baidu.com/s/1qKaDd9PSUUGbBQNB3tkDzw <机器学习实战:基于Scikit-Learn和TensorFlow>高清中文版PDF+ ...
- (原创)(三)机器学习笔记之Scikit Learn的线性回归模型初探
一.Scikit Learn中使用estimator三部曲 1. 构造estimator 2. 训练模型:fit 3. 利用模型进行预测:predict 二.模型评价 模型训练好后,度量模型拟合效果的 ...
- (原创)(四)机器学习笔记之Scikit Learn的Logistic回归初探
目录 5.3 使用LogisticRegressionCV进行正则化的 Logistic Regression 参数调优 一.Scikit Learn中有关logistics回归函数的介绍 1. 交叉 ...
- 机器学习实战:基于Scikit-Learn和TensorFlow 读书笔记 第6章 决策树
数据挖掘作业,要实现决策树,现记录学习过程 win10系统,Python 3.7.0 构建一个决策树,在鸢尾花数据集上训练一个DecisionTreeClassifier: from sklearn. ...
- 集成算法(chapter 7 - Hands on machine learning with scikit learn and tensorflow)
Voting classifier 多种分类器分别训练,然后分别对输入(新数据)预测/分类,各个分类器的结果视为投票,投出最终结果: 训练: 投票: 为什么三个臭皮匠顶一个诸葛亮.通过大数定律直观地解 ...
- 【.NET Core项目实战-统一认证平台】第十四章 授权篇-自定义授权方式
[.NET Core项目实战-统一认证平台]开篇及目录索引 上篇文章我介绍了如何强制令牌过期的实现,相信大家对IdentityServer4的验证流程有了更深的了解,本篇我将介绍如何使用自定义的授权方 ...
- DirectX12 3D 游戏开发与实战第四章内容(上)
Direct3D的初始化(上) 学习目标 了解Direct3D在3D编程中相对于硬件所扮演的角色 理解组件对象模型COM在Direct3D中的作用 掌握基础的图像学概念,例如2D图像的存储方式,页面翻 ...
随机推荐
- 微信小程序 验证码倒计时组件
https://blog.csdn.net/susuzhe123/article/details/80032224
- 20162322 朱娅霖 作业011 Hash
20162322 2017-2018-1 <程序设计与数据结构>第十一周学习总结 教材学习内容总结 哈希方法 一.定义 哈希:次序--更具体来说是项在集合中的位置--由所保存元素值的某个函 ...
- vue项目强制清除页面缓存
异常描述: 支付宝中内嵌h5项目(vue框架开发),前端重新打包上传之后访问页面会导致页面空白.页面tab点击异常之类异常情况,需要手动清除支付宝缓存才可以正常访问. 解决方案: 在HTTP协议中,只 ...
- Pains and Sickness 学习笔记
Headaches can be very painful and can last for a long time. If you have a headache, your head hurts. ...
- 目前php连接mysql的主要方式
mysqli和PDO, 其中mysqli可以有面向过程,面向对象两种方式.而pdo只有面向对象的方式. <?php // $mysql_server = "localhost" ...
- 手机连得上WIFI,电脑连不上的情况
可以搜到,密码也对,但就是连不上,这时候可能就是你的设置错了. 操作步骤以下: 右击我的电脑-->管理-->设备管理器-->网络适配器-->找到你wifi对应的那个名称(如果不 ...
- robotframework手机号随机产生脚本
首先,要导入使用库 random; ${phone} Evaluate random.choice(['139','188','185','136','158','151'])+"" ...
- ubuntu,day 2 ,退出当前用户,创建用户,查找,su,sudo,管道符,grep,alias,mount,tar解压
本节内容: 1,文件权限的控制,chmod,chown 2,用户的增删和所属组,useradd,userdel 3,用户组的增删,groupadd,groupdel 4,su,sudo的介绍 5,别名 ...
- nagios 报警参数
host_notification_options: d = notify on DOWN host states, u = notify on UNREACHABLE host states r = ...
- poj2240
一个关于套利的题,就是判断是否有正环,我这里是用的SPFA,只要判断出来一种货币初始为1,最后变得大于1就代表是正环,要注意一下最后对vector的清空,当时从1开始清空,导致wa了两次,找了半天,尽 ...