HDFS初次编程
hadoop是用Java语言实现的开源软件框架,可以支持多种语言,我学习的时候用得自然就是Java了。
在开始编程之前需要做一些配置工作:
Hadoop开发:Hadoop为HDFS和Mapreduce提供了基础的支持,叫hadoop common。Hadoop有一个专门的common jar包,需要导入这个包。
路径:(安装位置)/hadoop(安装之后整个文件夹,一般格式为hadoop+版本号)/share/hadoop
首先新建一个Java Project,右键项目选择Properties---->Java Build Path---->Libraries---->Add External JARs
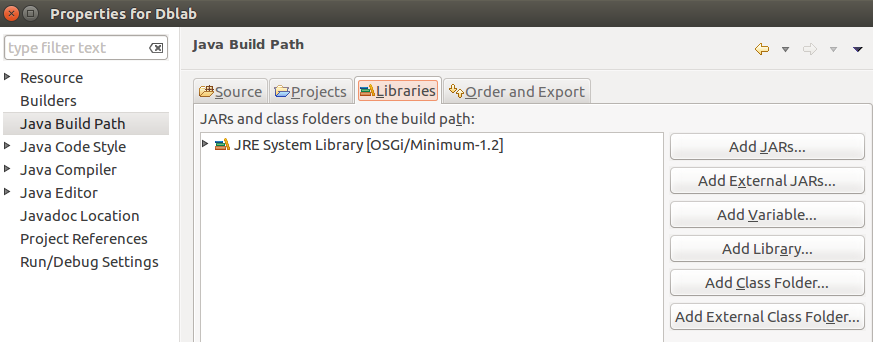
导入如下所示jar包:

接下来就可以具体编程了。
编程实例:
检测伪分布式文件系统HDFS上到底存不存在一个test.txt文件?
1. 把配置文件放到当前Java工程目录下,即把core-site.xml和hdfs-site.xml(/hadoop/etc/hadoop/)放到项目的bin文件夹下面。
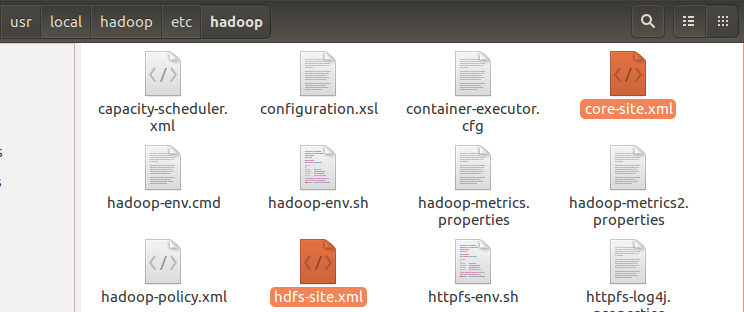
若是缺少该步,运行时会出现错误:

2 编写代码如下:
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.Path; public class first {
public static void main(String args[]){
try{
String filename = "hdfs://localhost:9000/user/hadoop/test.txt"; Configuration conf = new Configuration();
FileSystem fs = FileSystem.get(conf);
if(fs.exists(new Path(filename))){
System.out.println("File exists");
}
else{
System.out.println("File dose not exist");
} }
catch(Exception e){
e.printStackTrace();
}
}
}
启动hadoop:

在这过程中也是遇到了一系列错误,首先是:
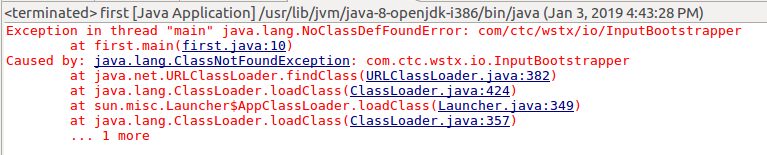
错误原因是缺少包,简单粗暴的解决办法是把common中lib下的所有包都导进去。
再次运行,又出错:
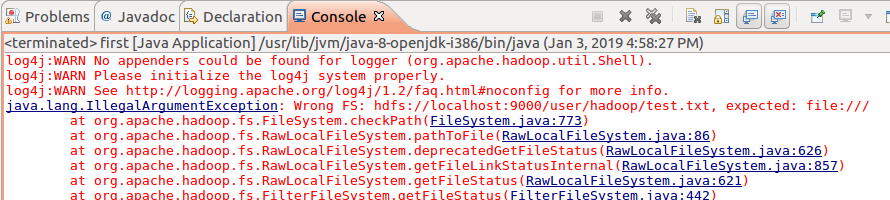
解决办法为在项目的src文件下面创建一个log4j.properties文件,内容为:
# Configure logging for testing: optionally with log file
log4j.rootLogger=WARN, stdout
# log4j.rootLogger=WARN, stdout, logfile log4j.appender.stdout=org.apache.log4j.ConsoleAppender
log4j.appender.stdout.layout=org.apache.log4j.PatternLayout
log4j.appender.stdout.layout.ConversionPattern=%d %p [%c] - %m%n log4j.appender.logfile=org.apache.log4j.FileAppender
log4j.appender.logfile.File=target/spring.log
log4j.appender.logfile.layout=org.apache.log4j.PatternLayout
log4j.appender.logfile.layout.ConversionPattern=%d %p [%c] - %m%n
再运行,继续出错,"Class org.apache.hadoop.hdfs.DistributedFileSystem not found":
又是缺少包,仍然是粗暴添加包,把hdfs中的所有jar包添加进去即可。
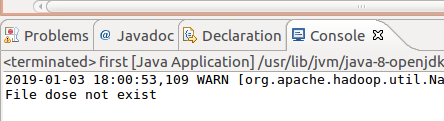
最后,终于成功了!

HDFS初次编程的更多相关文章
- 【HDFS API编程】查看文件块信息
现在我们把文件都存在HDFS文件系统之上,现在有一个jdk.zip文件存储在上面,我们想知道这个文件在哪些节点之上?切成了几个块?每个块的大小是怎么样?先上测试类代码: /** * 查看文件块信息 * ...
- 【HDFS API编程】查看目标文件夹下的所有文件、递归查看目标文件夹下的所有文件
使用hadoop命令:hadoop fs -ls /hdfsapi/test 我们能够查看HDFS文件系统/hdfsapi/test目录下的所有文件信息 那么使用代码怎么写呢?直接先上代码:(这之后 ...
- 【HDFS API编程】从本地拷贝文件,从本地拷贝大文件,拷贝HDFS文件到本地
接着之前继续API操作的学习 CopyFromLocalFile: 顾名思义,从本地文件拷贝 /** * 使用Java API操作HDFS文件系统 * 关键点: * 1)create Configur ...
- 【HDFS API编程】副本系数深度剖析
上一节我们使用Java API操作HDFS文件系统创建了文件a.txt并写入了hello hadoop(回顾:https://www.cnblogs.com/Liuyt-61/p/10739018.h ...
- 【HDFS API编程】查看HDFS文件内容、创建文件并写入内容、更改文件名
首先,重点重复重复再重复: /** * 使用Java API操作HDFS文件系统 * 关键点: * 1)创建 Configuration * 2)获取 FileSystem * 3)...剩下的就是 ...
- 【HDFS API编程】jUnit封装-改写创建文件夹
首先:什么是jUnit 回顾: https://www.cnblogs.com/Liuyt-61/p/10374732.html 上一节我们知道: /** * 使用Java API操作HDFS文件系 ...
- 【HDFS API编程】第一个应用程序的开发-创建文件夹
/** * 使用Java API操作HDFS文件系统 * 关键点: * 1)创建 Configuration * 2)获取 FileSystem * 3)...剩下的就是 HDFS API的操作了*/ ...
- HDFS简单编程实例:文件合并
下图显示了HDFS文件系统中路径为“localhost:50070/explorer.html#/user/hadoop”的目录中所有的文件信息: 对于该目录下的所有文件,我们将执行以下操作: 首先, ...
- HDFS API编程
3.1常用类 3.1.1Configuration Hadoop配置文件的管理类,该类的对象封装了客户端或者服务器的配置(配置集群时,所有的xml文件根节点都是configuration ...
随机推荐
- java学习之路--String类的基本方法
String类常见的功能 获取 1.1 字符串中包含的字符数,也就是获取字符串的长度:int length(); 1.2 根据位置获取某个位置上的字符:char charAt(int index) 1 ...
- 点击app分享链接,js判断手机是否安装某款app,有就尝试打开,没有就下载
html: <h1 class="downlink"> 前往 </h1> js: document.addEventListener('DOMContent ...
- Logcat
logcat -- "-s"选项 : 设置输出日志的标签, 只显示该标签的日志; -- "-f"选项 : 将日志输出到文件, 默认输出到标准输出流中, -f 参 ...
- ArcPy第一章-Python基础
学习Arcpy,从零开始积累.1.代码注释: python中,说明部分通常使用注释来实现: 方式: # 或者 ## + 注释部分内容2. 模块导入: 方式: import Eg: import arc ...
- 解决键盘输入被JDB占用的问题
解决键盘输入被JDB占用的问题 本周的任务"迭代和JDB"在使用JDB调试时需要键盘输入数据,但我在正确的位置输入数据后发现JDB提示如图所示的错误. 上网查找后得知该错误的产生是 ...
- LeetCode 206 Reverse Linked List 解题报告
题目要求 Reverse a singly linked list. Example: Input: 1->2->3->4->5->NULL Output: 5-> ...
- JMeter学习-041-响应数据中文乱码解决方法
华夏子孙,中文为母语.因而在接口测试过程中,响应数据含有中文是再也正常不过的事情.同时,初学JMeter的童鞋,经常会遇到响应数据中中文乱码的问题. 本文中提供两种方式的修正方法,仅供大家参考,谢谢. ...
- [vue]mvc模式和mvvm模式及vue学习思路(废弃)
好久不写东西了,感觉收生疏了, 学习使用以思路为主, 记录笔记为辅作用. v-if: http://www.cnblogs.com/iiiiiher/p/9025532.html v-show tem ...
- 用stm32f10x建立新的工程重要步骤
stm32f10x系列新建空的工程主要原理: 1.添加启动文件 不同的芯片类型的启动文件的容量是不同的,选择适合该芯片的容量作为启动文件. 注意:启动文件是汇编语言编写的,所以文件的后缀名为.s 2. ...
- centos7.5固定局域网ip
有点时候,比如像我们单位,没事干就停一次网,结果ip变了,还得重新看ip,重新配置,很麻烦,所以干脆把自己ip固定,以不变应万变!!! 1.首先查看自己的ip是什么: $ ifconfig eno1: ...