mysql InnoDB index 主键采用聚簇索引,二级索引不采用聚簇索引
我的归纳:
(1)InnoDB的主键采用聚簇索引存储,使用的是B+Tree作为索引结构,但是叶子节点存储的是索引值和数据本身(注意和MyISAM的不同)。
(2)InnoDB的二级索引不使用聚蔟索引,叶子节点存储的是KEY字段加主键值。因此,通过二级索引查询首先查到是主键值,然后InnoDB再根据查到的主键值通过主键索引找到相应的数据块。
(3)MyISAM的主键索引和二级索引叶子节点存放的都是列值与行号的组合,叶子节点中保存的是数据的物理地址
(4)MyISAM引擎使用B+Tree作为索引结构,叶节点的data域存放的是数据记录的地址
(5)为什么用B+Tree 不是BTree:
B-Tree:如果一次检索需要访问4个节点,数据库系统设计者利用磁盘预读原理,把节点的大小设计为一个页,那读取一个节点只需要一次I/O操作,完成这次检索操作,最多需要3次I/O(根节点常驻内存)。数据记录越小,每个节点存放的数据就越多,树的高度也就越小,I/O操作就少了,检索效率也就上去了。
B+Tree:非叶子节点只存key,大大滴减少了非叶子节点的大小,那么每个节点就可以存放更多的记录,树更矮了,I/O操作更少了。所以B+Tree拥有更好的性能。
下面是原文中对聚簇索引的介绍,介绍的很简单易懂:
1.聚簇索引是对磁盘上实际数据重新组织以按指定的一个或多个列的值排序的算法。特点是存储数据的顺序和索引顺序一致。
一般情况下主键会默认创建聚簇索引,且一张表只允许存在一个聚簇索引。
在《数据库原理》一书中是这么解释聚簇索引和非聚簇索引的区别的:
聚簇索引的叶子节点就是数据节点,而非聚簇索引的叶子节点仍然是索引节点,只不过有指向对应数据块的指针。
因此,MySQL中不同的数据存储引擎对聚簇索引的支持不同就很好解释了。
2.下面,我们可以看一下mysql中MYISAM和INNODB两种引擎的索引结构。
如原始数据为:
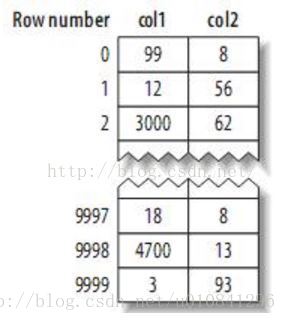
MyISAM引擎的数据存储方式如图:
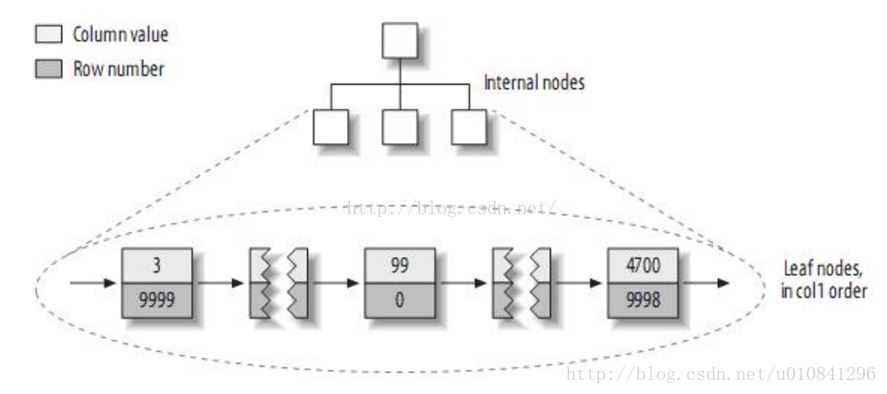
(1)MYISAM是按列值与行号来组织索引的。它的叶子节点中保存的实际上是指向存放数据的物理块的指针。
从MYISAM存储的物理文件我们能看出,MYISAM引擎的索引文件(.MYI)和数据文件(.MYD)是相互独立的。
(2)而InnoDB按聚簇索引的形式存储数据,所以它的数据布局有着很大的不同。它存储数据的结构大致如下:
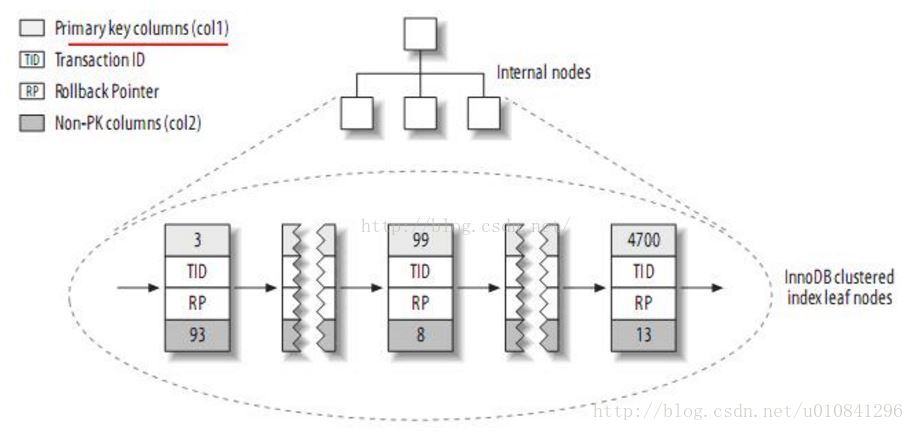
注:聚簇索引中的每个叶子节点包含主键值、事务ID、回滚指针(rollback pointer用于事务和MVCC)和余下的列(如col2)。
(3)INNODB的二级索引与主键索引有很大的不同。InnoDB的二级索引的叶子包含主键值,而不是行指针(row pointers),这减小了移动数据或者数据页面分裂时维护二级索引的开销,因为InnoDB不需要更新索引的行指针。其结构大致如下:
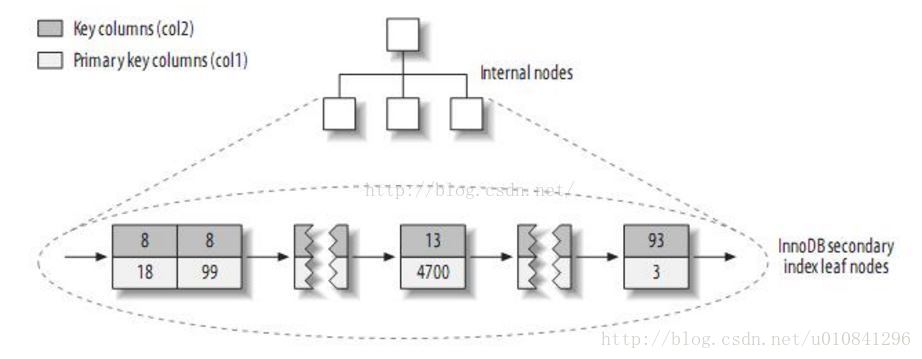
INNODB和MYISAM的主键索引与二级索引的对比:
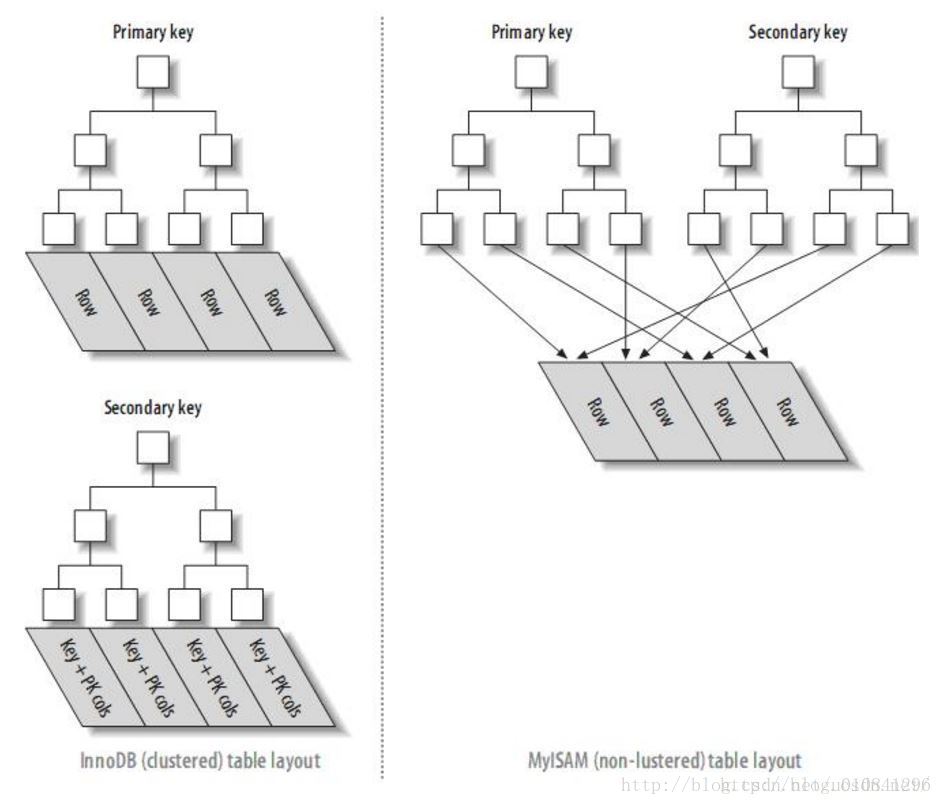
(4)InnoDB的的二级索引的叶子节点存放的是KEY字段加主键值。因此,通过二级索引查询首先查到是主键值,然后InnoDB再根据查到的主键值通过主键索引找到相应的数据块。而MyISAM的二级索引叶子节点存放的还是列值与行号的组合,叶子节点中保存的是数据的物理地址。所以可以看出MYISAM的主键索引和二级索引没有任何区别,主键索引仅仅只是一个叫做PRIMARY的唯一、非空的索引,且MYISAM引擎中可以不设主键。
mysql InnoDB index 主键采用聚簇索引,二级索引不采用聚簇索引的更多相关文章
- MySQL与Oracle主键Query性能测试结果
测试结果总结如下: 1. 按主键读:SQL形式:SELECT * FROM table WHERE id=?. 1.1. 主键为数字.如果所有ID均不存在,纯比较SQL解析能力.MySQL解析SQL的 ...
- MySQL中innodb表主键设计原则
主键设计的原则:1. 一定要显式定义主键2. 采用与业务无关的单独列3. 采用自增列4. 数据类型采用int,并尽可能小,能用tinyint就不用int,能用int就不用bigint5. 将主键放在表 ...
- MySQL 聚簇索引&&二级索引&&辅助索引
MySQL非聚簇索引&&二级索引&&辅助索引 mysql中每个表都有一个聚簇索引(clustered index ),除此之外的表上的每个非聚簇索引都是二级索引,又叫辅 ...
- 设置MySQL数据表主键
设置MySQL数据表主键: 使用“primary key”关键字创建主键数据列.被设置为主键列不允许出现重复的值,很多情况下与“auto_increment”递增数字相结合.如下SQL语句所示: My ...
- 关于MySQL自增主键的几点问题(上)
前段时间遇到一个InnoDB表自增锁导致的问题,最近刚好有一个同行网友也问到自增锁的疑问,所以抽空系统的总结一下,这两个问题下篇会有阐述. 1. 划分三种插入类型 这里区分一下几种插入数据行的类型,便 ...
- MySQL 数据库,主键为何不宜太长长长长长长长长?
回答星球水友提问:沈老师,我听网上说,MySQL数据表,在数据量比较大的情况下,主键不宜过长,是不是这样呢?这又是为什么呢? 这个问题嘛,不能一概而论: (1)如果是InnoDB存储引擎,主键不宜过长 ...
- InnoDB的主键选择与插入优化
索引的存放方式MyISAM和InnoDB存储引擎在MySQL中,不同存储引擎对索引的实现方式是不同的,总结下MyISAM和InnoDB两个存储引擎的索引实现方式.MyISAM引擎使用B+Tree作为索 ...
- day03 MySQL数据库之主键与外键
day03 MySQL数据库之主键与外键 昨日内容回顾 针对库的基本SQL语句 # 增 create database meng; # 查 show databases; shwo create da ...
- Mysql 创建联合主键
Mysql 创建联合主键2008年01月11日 星期五 下午 5:21使用primary key (fieldlist) 比如: create table mytable ( ...
随机推荐
- 关于npm Vue
参考:http://www.runoob.com/w3cnote/vue2-start-coding.html 安装vue脚手架 npm install vue-cli -g 查看当前脚手架版本 np ...
- redis示例 - 限速器,计时器
INCR INCR key 将 key 中储存的数字值增一. 如果 key 不存在,那么 key 的值会先被初始化为 0 ,然后再执行 INCR 操作. 如果值包含错误的类型,或字符串类型的值不能表示 ...
- Spark生态以及原理
spark 生态及运行原理 Spark 特点 运行速度快 => Spark拥有DAG执行引擎,支持在内存中对数据进行迭代计算.官方提供的数据表明,如果数据由磁盘读取,速度是Hadoop MapR ...
- nuxtjs中使用axios
最近使用nuxtjs服务端渲染框架,在异步请求时遇到两个问题,一是怎么使用axios, 二是怎么在asyncData方法中使用axios 当使用脚手架create nuxt-app创建项目时,会提示是 ...
- arithmetic-02
Java collection API 中实现的表ADT: collection<E>接口实现继承iterable<E>接口,实现iterable接口的类可以使用增强for循环 ...
- 线段树 HDU-1166 敌兵布阵
敌兵布阵是一个线段树典题,题目如下(点此查看题目出处): Problem Description C国的死对头A国这段时间正在进行军事演习,所以C国间谍头子Derek和他手下Tidy又开始忙乎了.A国 ...
- Practical Lessons from Predicting Clicks on Ads at Facebook
ABSTRACT 这篇paper中作者结合GBDT和LR,取得了很好的效果,比单个模型的效果高出3%.随后作者研究了对整体预测系统产生影响的几个因素,发现Feature(能挖掘出用户和广告的历史信息) ...
- 收银台数据库存储AES加解密
高级加密标准(AES,Advanced Encryption Standard)为最常见的对称加密算法加密和解密用到的密钥是相同的,这种加密方式加密速度非常快,适合经常发送数据的场合.缺点是密钥的传输 ...
- 解决 Bash On Windows 下载慢或无法下载的问题
解决 Bash On Windows "无法从 Windows 应用商店下载.请检查网络连接."的问题 Fiddler和Bash On Windows 源离线压缩包:http:// ...
- Html lable 标签
Html lable 标签 <html> <body> <!-- label 关联光标标签,点击文字使得关联的标签获取光标.for="username" ...