大数据hadoop的伪分布式搭建
1.配置环境变量JDK配置
1.JDK安装
个人喜欢在
vi ~/.bash profile 下配置
export JAVA_HOME=/home/hadoop/app/jdk1.8.0_91
export PATH=$JAVA_HOME/bin:$PATH
当然要让环境变量生效source ~/.bash_profile
echo $JAVA_HOME
在输入 java -verision,生效就装好了jdk

2.安装ssh
生成秘钥
ssh-keygen -t rsa
在将公钥复制到authorized_keys中

hadoop 安装中需要安装hadoop.env.sh

通过echo $JAVA_HOME 的到环境变量并且配置hadoop.env.sh中

core-site.xml要修改的文件在hadoop中
hadoop 在1.0是端口默认是9000现在2.0默认是8020
<configuration>
<property>
<name>fs.defaultFS</name>
<value>hdfs://localhost:8020</value>
</property>
</configuration>
//制定一个存放临时文件的文件夹
<configuration>
<property>
<name>dfs.replication</name>
<value>/home/hadoop/app/tmp</value>
</property>
</configuration>
然后可以再core-site.xml中的指定的文件夹中
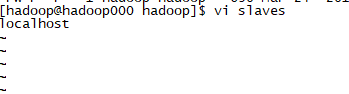
你有多少个datenode就写在slave中
5.启动hdfs
格式化文件系统(仅第一次执行即可,不要重复执行):hdfs/hadoop namenode -format

2.快速启动namenode和datanode

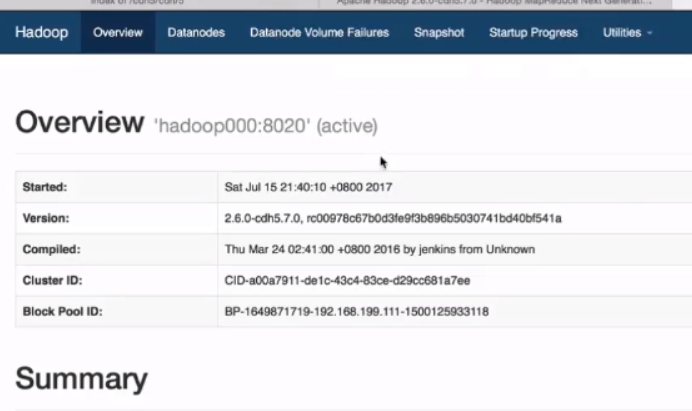
伪分布式启动成功

在网页上输入http://hadoop000:50070可以进行观看hadoop给前端的展示
停止伪分布式
./stop.dfs.sh

大数据hadoop的伪分布式搭建的更多相关文章
- 大数据 -- Hadoop集群环境搭建
首先我们来认识一下HDFS, HDFS(Hadoop Distributed File System )Hadoop分布式文件系统.它其实是将一个大文件分成若干块保存在不同服务器的多个节点中.通过联网 ...
- 【原创干货】大数据Hadoop/Spark开发环境搭建
已经自学了好几个月的大数据了,第一个月里自己通过看书.看视频.网上查资料也把hadoop(1.x.2.x).spark单机.伪分布式.集群都部署了一遍,但经历短暂的兴奋后,还是觉得不得门而入. 只有深 ...
- Hadoop的伪分布式搭建
我们在搭建伪分布式Hadoop环境,需要将一系列的配置文件配置好. 一.配置文件 1. 配置文件hadoop-env.sh export JAVA_HOME=/opt/modules/jdk1.7.0 ...
- 大数据-hadoop HA集群搭建
一.安装hadoop.HA及配置journalnode 实现namenode HA 实现resourcemanager HA namenode节点之间通过journalnode同步元数据 首先下载需要 ...
- 搭建大数据hadoop完全分布式环境遇到的坑
搭建大数据hadoop完全分布式环境,遇到很多问题,这里记录一部分,以备以后查看. 1.在安装配置完hadoop以后,需要格式化namenode,输入指令:hadoop namenode -forma ...
- 我搭建大数据Hadoop完全分布式环境遇到的坑---hadoop: command not found
搭建大数据hadoop环境,遇到很多问题,这里记录一部分,以备以后查看. [遇到问题].在安装配置完hadoop以后,需要格式化namenode,输入指令:hadoop namenode -forma ...
- 大数据Hadoop学习之搭建hadoop平台(2.2)
关于大数据,一看就懂,一懂就懵. 一.概述 本文介绍如何搭建hadoop分布式集群环境,前面文章已经介绍了如何搭建hadoop单机环境和伪分布式环境,如需要,请参看:大数据Hadoop学习之搭建had ...
- Hadoop简介与伪分布式搭建—DAY01
一. Hadoop的一些相关概念及思想 1.hadoop的核心组成: (1)hdfs分布式文件系统 (2)mapreduce 分布式批处理运算框架 (3)yarn 分布式资源调度系统 2.hadoo ...
- 王家林的“云计算分布式大数据Hadoop实战高手之路---从零开始”的第十一讲Hadoop图文训练课程:MapReduce的原理机制和流程图剖析
这一讲我们主要剖析MapReduce的原理机制和流程. “云计算分布式大数据Hadoop实战高手之路”之完整发布目录 云计算分布式大数据实战技术Hadoop交流群:312494188,每天都会在群中发 ...
随机推荐
- new date() 计算本周周一日期
new date() 计算本周周一日期 需求:计算某天的那一周周一的日期 1.new Date() date.getDay(); //获取周几 0-6 date.getTime();//获取时间戳 1 ...
- C# 类库调试 启动外部程序无法调试
无法调试进程 test.exe [17936] 中的某些代码.请参阅下面的状态信息. IntelliTrace 代码失败(0x80131534). Managed (v4.6.v4.5.v4.0 ...
- E2040 Declaration terminated incorrectly - System.ZLib.hpp(310) ZLIB_VERSION
[bcc32 Error] System.ZLib.hpp(310): E2040 Declaration terminated incorrectly Full parser context ...
- php7内核执行流程(转载留记录)
- Notepadd ++ PluginManager安装
下载地址https://github.com/bruderstein/nppPluginManager/releases 解压后有2个包plugins和updater 分别放入C:\Program F ...
- English-英语学习杂志及资料
[英文原版杂志] >>经济学人 英文原版PDF+双语版+文本音频 超全下载!http://bbs.zhan.com/thread-8443-1-1.html?sid=2004 >&g ...
- 推荐一款idea 翻译插件 ECTranslation
无意中看到一款idea翻译插件, ECTranslation,才知道有这么个东西,推荐给看到的人吧,使用简单,值得拥有. 参考:http://p.codekk.com/detail/Android/S ...
- Unable to connect to zookeeper server within timeout: 5000
错误 严重: StandardWrapper.Throwable org.springframework.beans.factory.BeanCreationException: Error crea ...
- JSFL 禁止脚本运行时间太长的警告
fl.showIdleMessage(false);
- unity 脚本说明
MonoBehavour void OnEnable(){ //OnEnable执行在Wake和之前 } void Awake(){ // } void Start(){ } void OnEnabl ...