linux 内存布局以及tlb更新的一些理解
x86架构,问题:
1.内核线程是否有vma线性区?
2.单线程的一个进程,它修改了自己的页表,是否需要发送ipi来通知其他核更新tlb?
3.普通进程,在32位和64位,对应的线性区的最大地址能到多少?
在64位中,linux内核默认的内存布局是:
ffffffff ffffffff _____________
| |
| 内核空间 |
ffff8000 00000000 |____________|
| |
| 未使用 |
| 的空间 |
| |
00007fff ffffffff |____________|
| |
| 用户空间 |
00000000 00000000 |____________|
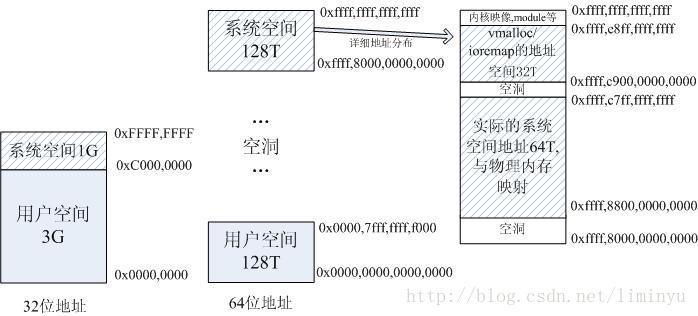
也就是用户空间占用的位数是47位,内核空间也是47位,所以整体可以寻址的是2的48次方,也就是256T,足够用了。
那另外0xffff,8800,0000,0000 – 0xffff,c7ff,ffff,ffff这64T直接和物理内存进行映射,0xffff,c900,0000,0000 – 0xffff,e8ff,ffff,ffff这32T用于vmalloc/ioremap的地址空间。
而32位地址空间时,当物理内存大于896M时(Linux2.4内核是896M,3.x内核是884M,是个经验值),由于地址空间的限制,内核只会将0~896M的地址进行映射,而896M以上的空间用做一些固定映射和vmalloc/ioremap。而64位地址时是将所有物理内存都进行映射。
64位里面没有了那些高端内存的说法,所以内存管理和映射反而简单了。借用csdn中搜索的图(图中有对应水印),用户态地址布局如下:
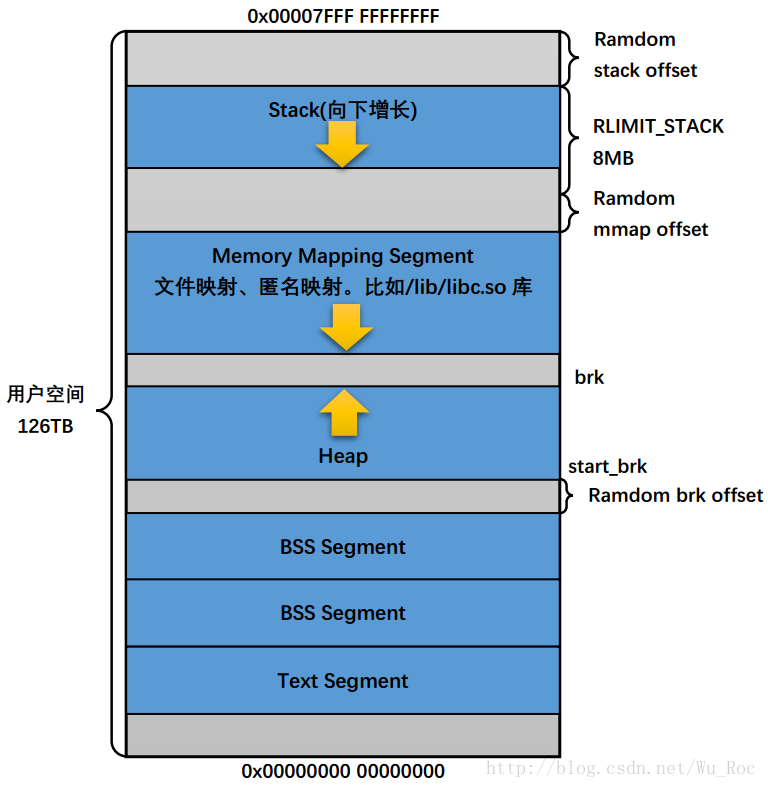
内核态地址布局如下:
现在看第一个问题:内核线程,借用了别人的mm作为active_mm,它其实没有vma的,vma里面都是关于用户态地址的。由于内核线程不访问用户态地址空间,则不需要vma。(有同事提醒说,如果一个内核线程故意去访问用户态的数据区,这种也需要访问用户态地址空间,但我没见着这么用过的,自己写的内核线程倒是可以这么做)
一个多线程的进程,在内核中,看到的mm_struct(简写为mm,下同)中的计数如下:
crash> mm_struct.mm_users 0xffff8857b5ef92c0
mm_users = {
counter =
}
crash> mm_struct.mm_count 0xffff8857b5ef92c0
mm_count = {
counter =
}
mm_user是这个进程中的线程个数的体现,也就是这些线程共用这个mm,
如果是内核线程借用mm作为active_mm,则计数增加是在mm_count中,对于只有一个线程的进程而言,如果调度出去,那么它的mm如果被内核线程借用的话,则mm有两个计数,应该分别为:
mm_user =1,而mm_count=2.(其中一个是本身的计数,一个是内核线程引用的计数)。
初始状态下,这两个值都是1。当 mm_users 减为 0 时,mm_count 会自减 1。也即是仅当 mm_users 减为 0 时,mm_count 才可能为 0。
mm_count 代表了对 mm 本身的引用,而 mm_users 代表对 mm 相关资源的引用,分了两个层次。
可能存在这样的情况,mm 已经没有人使用了(mm_users为0),所以其相关资源被释放掉(如vma);但是 mm 本身可能还在被人借用(比如被一个内核线程,它不会使用vma),所以 mm 本身还不能被释放;这句话不知道怎么写比较好,就像中国人说,夏天能穿多少穿多少,冬天能穿多少穿多少一个道理。
现在来看第二个问题,关于tlb的刷新问题,首先要明白tlb中,有标记为Global(后面简称G)的部分,也有不是的,为G的属于内核,所有进程通用。ipi是实现tlb更新的一种方式,但不是唯一方式。处理器不能自动同步他们自己的tlb,因为决定线性地址与物理地址之间的映射有效性的,是内核,而不是硬件本身。
当这个单线程的进程A调度到其他的cpu上,他的mm可能还被其他内核线程借用着,这个时候如果该线程A修改了自己的页表集,不管是G的条目还是非G的条目,自然要体现在当前cpu的tlb上,如果是G项,则会flush_tlb_all,此时的目的cpu是所有cpu,如果非G项,就会发送ipi通知相关的cpu,发送的目的cpu,就在mm的cpumask_allocation成员中(2.6的代码是在cpu_vm_mask),由于被借用,所以如果借用的内核线程运行的cpu和当前A线程运行的cpu不一致的话,则cpumask_allocation 中就有两个cpu位被置位。此时使用的函数主要有flush_tlb_mm和flush_tlb_range等,针对的是非G的条目。关于cpumask_allocation,可以用如下的crash来验证:
crash> mm_struct.cpumask_allocation 0xffff8852eb41abc0
cpumask_allocation = {
bits = {, , , , , , , , , , , , , , , , , , , , , , , , , , , , , , , , , , , , , , , , , , , , , , , , , , , , , , , , , , , , , , , , , , , , , , , , , , , , , , , }
} crash> px
$ = 0x2000000000000 fpu = {
last_cpu = ,
has_fpu = ,
state = 0xffff8823f52dc980
},
借用A的mm的内核线程B,因为启用lazytlb模式,虽然收到了ipi请求刷新tlb,非G条目,就不会更新其tlb,并将其cpu从对应的mm->cpu_vm_mask删除。一旦删除,以后都不会再收到非G条目的更新了,因为发送方是根据cpu_vm_mask(3.10是cpumask_allocation)来发送ipi请求的。当该内核线程被切换出去的时候,如果被替换的mm刚好和自己的mm一样,则内核调用__flush_tlb 来使得该cpu的所有非全局tlb表项失效。
第一次看到这个地方,还很迷糊,明明和自己的mm一样,为啥还要刷,后来想了下,由于lazytlb模式,自己当时已经不刷tlb了,也就是虽然mm一样,但和该进程的mm里面的各个vma对应的页表已经不一样了,存在脏的tlb,如果不刷,有可能导致访问异常。就是偷懒了没刷,到头来发现mm一样,还得刷,但这种概率不高,特别是单线程的程序。
如果mm不一样,自然天生要刷。这个就是lazytlb的。
最后来看第三个问题,由于线性区里面对应的地址都是用户态的,所以应该一个是3G,一个是2的47次方了,跟布局有关系。这个和第一个问题有些相关。
ps:lazytlb,在vmalloc中也有体现,就是vfree流程中,对于tlbflush操作,采用lazy模式,此时并不真正free,等收集一部分之后,再free,同时刷tlb,防止每次free都去刷tlb,提高了性能。具体可以查看 free_vmap_area_noflush ,lazy_max_pages 等函数。
linux 内存布局以及tlb更新的一些理解的更多相关文章
- Linux 内存布局
本文主要简介在X86体系结构下和在ARM体系结构下,Linux内存布局的概况,力求简单明了,不过多深入概念,多以图示的方式来记忆理解,一图胜万言. Technorati 标签: 内存 布局 ...
- Linux内存管理 (20)最新更新和展望
专题:Linux内存管理专题 关键词:OOM.swap.HMM.LRU. 本系列没有提到的内容由THP(Transparent Huge Page).memory cgroup.slub.CMA.zr ...
- Linux内存布局
在上一篇博文里,我们已经看到Linux如何有效地利用80x86的分段和分页硬件单元把逻辑地址转换为线性地址,在由线性地址转换到物理地址.那么我们的应用程序如何使用这些逻辑地址,整个内存的地址布局又是怎 ...
- linux内存布局------深入理解计算机系统
- linux系统进程的内存布局
内存管理模块是操作系统的心脏:它对应用程序和系统管理非常重要.今后的几篇文章中,我将着眼于实际的内存问题,但也不避讳其中的技术内幕.由于不少概念是通用的,所以文中大部分例子取自32位x86平台的Lin ...
- linux内存管理解析1----linux物理,线性内存布局及页表的初始化
主要议题: 1分页,分段模式及实模式 2Linux分页 3linux内存线性地址空间布局及物理内存空间布局 4linux页表初始化及代码解析 1.1.1内存寻址和保护模式 在X86平台上,内存控制单元 ...
- [内存管理]linux X86_64处理器的内存布局图
linux X86 64位内存布局图
- Linux内存管理 (3)内核内存的布局图
专题:Linux内存管理专题 关键词:内核内存布局图.lowmem线性映射区.kernel image.ZONE_NORMAL.ZONE_HIGHMEM.swapper_pg_dir.fixmap.v ...
- Linux内存初始化(三) 内存布局
一.前言 同样的,本文是内存初始化文章的一份补充文档,希望能够通过这样的一份文档,细致的展示在初始化阶段,Linux 4.4.6内核如何从device tree中提取信息,完成内存布局的任务.具体的c ...
随机推荐
- [UE4]函数参数引用
函数传递的变量可以当做正常的内部变量使用,而不需要把函数变量赋值给新创建一个内部变量.
- 第一次软件工程作业——html制作一份简单的个人简历
源码链接(码云):https://gitee.com/yongliuli/codes/eavjr7lxotb85s0icnq1z68 简历效果图展示: 代码展示: 添加背景音乐的方法: 在<he ...
- 解决DevExpress10.2.4版本在VS2012工具箱控件不显示的问题
DevExpress10.2.4支持vs2010,安装vs2010或找一台装有vs2010的机器安装DevExpress10.2.4 执行DevExpress10.2.4的工具ToolboxCreat ...
- PHP正则配合写配置文件导致Getshell
PHP正则配合写配置文件导致Getshell,偶然间看到的一个题目, p 牛的小密圈的一个问题. 分析一下,漏洞代码: index.php <?php $str=addslashes($_GET ...
- XML与 实体的相互转化
using System; using System.Linq; using System.Xml; using System.Reflection; using System.Data; using ...
- [SHOI2012]信用卡凸包(计算几何)
/* 考验观察法?? 可以发现最终答案等于所有作为圆心的点求出凸包的周长加上一个圆的周长 向量旋转 (x1, y1) 相较于 (x2, y2) 旋转角c 答案是 (dtx * cosc - dty * ...
- Hive 2.1.1安装配置
##前期工作 安装JDK 安装Hadoop 安装MySQL ##安装Hive ###下载Hive安装包 可以从 Apache 其中一个镜像站点中下载最新稳定版的 Hive, apache-hive-2 ...
- 数据库导入Excel
package com.cfets.ts.s.user.rest; import java.io.File; import java.io.FileInputStream; import java.i ...
- WPF 获取文件夹路径,目录路径,复制文件,选择下载文件夹/目录
private void Border_MouseLeftButtonUp_4(object sender, MouseButtonEventArgs e) { //获取项目中文件 , System. ...
- linux中ps命令
ps的参数 -C的使用 [root@centos7 ~]# ps -C nginx -o user,pid,comm USER PID COMMAND root 2697 nginx nginx 26 ...