storm(5)-分布式单词计数例子
例子需求:
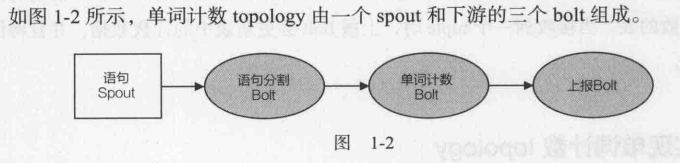
spout:向后端发送{"sentence":"my dog has fleas"}。一般要连数据源,此处简化写死了。
语句分割bolt(SplitSentenceBolt):订阅spout发送的tuple。每收到一个tuple,bolt会获取"sentence"对应值域的值,然后分割为一个个的单词。最后,每个单词向后发送1个tuple:
{"word":"my"}
{"word":"dog"}
{"word":"has"}
{"word":"fleas"}
单词计数bolt(WordCountBolt):订阅SplitSentenceBolt的输出。每当接收到1个tuple,会将对应单词的计数加1,最后向后发送该单词当前的计数。
{"word":"dog","count":5}
上报bolt:接收WordCountBolt输出,维护各单词对应计数表,并修改累计计数值。
代码实现:
package com.ebc.spout; import com.ebc.Utils;
import org.apache.storm.spout.SpoutOutputCollector;
import org.apache.storm.task.TopologyContext;
import org.apache.storm.topology.OutputFieldsDeclarer;
import org.apache.storm.topology.base.BaseRichSpout;
import org.apache.storm.tuple.Fields;
import org.apache.storm.tuple.Values; import java.util.Map; /**
* @author yaoyuan2
* @date 2019/4/11
*/
public class SentenceSpout extends BaseRichSpout {
private SpoutOutputCollector collector;
private final String [] sentences = {"a b", "c a"};
private int index = 0;
/**
* 所有spout组件在初始化时调用这个方法。
* @param conf:storm配置信息
* @param context:topology中组件信息
* @param collector:提供了emit tuple方法
* @return void
*/
@Override
public void open(Map conf, TopologyContext context, SpoutOutputCollector collector) {
this.collector = collector;
} @Override
public void nextTuple() {
this.collector.emit(new Values(sentences[index]));
index++;
if (index >= sentences.length) {
index = 0;
}
Utils.waitForMillis(1);
} @Override
public void declareOutputFields(OutputFieldsDeclarer declarer) {
declarer.declare(new Fields("sentence"));
}
}
package com.ebc.blot; import org.apache.storm.task.OutputCollector;
import org.apache.storm.task.TopologyContext;
import org.apache.storm.topology.OutputFieldsDeclarer;
import org.apache.storm.topology.base.BaseRichBolt;
import org.apache.storm.tuple.Fields;
import org.apache.storm.tuple.Tuple;
import org.apache.storm.tuple.Values; import java.util.Map; /**
* @author yaoyuan2
* @date 2019/4/11
*/
public class SplitSentenceBolt extends BaseRichBolt {
private OutputCollector collector;
/**
* 类似spout中的open()方法,可初始化数据库连接
* @param stormConf
* @param context
* @param collector
* @return void
*/
@Override
public void prepare(Map stormConf, TopologyContext context, OutputCollector collector) {
this.collector = collector;
}
/**
* <pre>
* 每当从订阅的数据流中接收1个tuple,都会调用这个方法。
* 形如:{"sentence":"my dog has fleas"}
* </pre>
* @param input
* @return void
*/
@Override
public void execute(Tuple input) {
String sentence = input.getStringByField("sentence");
String [] words = sentence.split(" ");
for (String word:words) {
this.collector.emit(new Values(word));
}
}
/**
* <pre>
* 每个tuple包含一个"word",如
* {"word":"my"}
* {"word":"dog"}
* {"word":"has"}
* {"word":"fleas"}
* </pre>
* @param declarer
* @return void
*/
@Override
public void declareOutputFields(OutputFieldsDeclarer declarer) {
declarer.declare(new Fields("word"));
}
}
package com.ebc.blot; import org.apache.storm.task.OutputCollector;
import org.apache.storm.task.TopologyContext;
import org.apache.storm.topology.OutputFieldsDeclarer;
import org.apache.storm.topology.base.BaseRichBolt;
import org.apache.storm.tuple.Fields;
import org.apache.storm.tuple.Tuple;
import org.apache.storm.tuple.Values; import java.util.HashMap;
import java.util.Map; /**
* @author yaoyuan2
* @date 2019/4/11
*/
public class WordCountBolt extends BaseRichBolt {
private OutputCollector collector;
private HashMap<String,Long> counts = null;
/**
* <pre>
* 一般情况下,
* 在构造函数中,只能对可序列化的对象赋值和实例化
* 在prepare中,对不可序列化的对象实例化。
* </pre>
* @param stormConf
* @param context
* @param collector
* @return void
*/
@Override
public void prepare(Map stormConf, TopologyContext context, OutputCollector collector) {
this.collector = collector;
this.counts = new HashMap<String,Long>();
} @Override
public void execute(Tuple input) {
String word = input.getStringByField("word");
Long count = this.counts.get(word);
if (count == null) {
count = 0L;
}
count++;
this.counts.put(word,count);
this.collector.emit(new Values(word,count)); }
/**
* 形如:{"word":"dog","count":5}
* @param declarer
* @return void
*/
@Override
public void declareOutputFields(OutputFieldsDeclarer declarer) {
declarer.declare(new Fields("word","count"));
}
}
package com.ebc.blot; import lombok.extern.slf4j.Slf4j;
import org.apache.storm.task.OutputCollector;
import org.apache.storm.task.TopologyContext;
import org.apache.storm.topology.OutputFieldsDeclarer;
import org.apache.storm.topology.base.BaseRichBolt;
import org.apache.storm.tuple.Tuple; import java.util.*; /**
* @author yaoyuan2
* @date 2019/4/11
*/
@Slf4j
public class ReportBolt extends BaseRichBolt {
private HashMap<String,Long> counts = null;
@Override
public void prepare(Map stormConf, TopologyContext context, OutputCollector collector) {
this.counts = new HashMap<String,Long>();
} @Override
public void execute(Tuple input) {
String word = input.getStringByField("word");
Long count = input.getLongByField("count");
this.counts.put(word,count);
} @Override
public void declareOutputFields(OutputFieldsDeclarer declarer) {
//该bolt不再向后emit任何数据流
}
/**
* <pre>
* 当topology关闭时输出最终的计数结果。
* 通常,clean()方法用来释放bolt占用的资源,如数据库连接。
* 注意,当topology在strom集群上运行时,clean()不能保证会执行,但本地模式能保证执行。
* </pre>
* @return void
*/
@Override
public void cleanup() {
log.info("最终counts");
List<String> keys = new ArrayList<String>();
keys.addAll(this.counts.keySet());
Collections.sort(keys);
for (String key : keys) {
System.out.println(key + " : " + this.counts.get(key));
}
log.info("---------"); }
}
package com.ebc; import com.ebc.blot.ReportBolt;
import com.ebc.blot.SplitSentenceBolt;
import com.ebc.blot.WordCountBolt;
import com.ebc.spout.SentenceSpout;
import org.apache.storm.Config;
import org.apache.storm.LocalCluster;
import org.apache.storm.topology.TopologyBuilder;
import org.apache.storm.tuple.Fields; /**
* @author yaoyuan2
* @date 2019/4/12
*/
public class WordCountTopology {
private static final String SENTENCE_SPOUT_ID = "sentence-spout";
private static final String SPLIT_BOLT_ID = "split-bolt";
private static final String COUNT_BOLT_ID = "count-bolt";
private static final String REPORT_BOLT_ID = "report-bolt";
private static final String TOPOLOGY_NAME = "word-count-topology"; public static void main(String[] args) {
SentenceSpout spout = new SentenceSpout();
SplitSentenceBolt splitBolt = new SplitSentenceBolt();
WordCountBolt countBolt = new WordCountBolt();
ReportBolt reportBolt = new ReportBolt(); TopologyBuilder builder = new TopologyBuilder();
builder.setSpout(SENTENCE_SPOUT_ID,spout);
//SentenceSpout --> SplitSentenceBolt。shuffleGrouping:要求spout将tuple随机均匀的分发给splitBolt实例
builder.setBolt(SPLIT_BOLT_ID,splitBolt).shuffleGrouping(SENTENCE_SPOUT_ID);
//SplitSentenceBolt --> WordCountBolt。fieldsGrouping:field="word"的tuple会被路由到同一个WordCountBolt实例中。
builder.setBolt(COUNT_BOLT_ID,countBolt).fieldsGrouping(SPLIT_BOLT_ID,new Fields("word"));
//WordCountBolt --> ReportBolt。globalGrouping:将WordCountBolt上所有的tuple都发送到唯一的一个ReportBolt实例中。此时并发度失去了意义。
builder.setBolt(REPORT_BOLT_ID,reportBolt).globalGrouping(COUNT_BOLT_ID); Config config = new Config();
LocalCluster cluster = new LocalCluster();
cluster.submitTopology(TOPOLOGY_NAME,config,builder.createTopology());
Utils.waitForSeconds(10);
cluster.killTopology(TOPOLOGY_NAME);
cluster.shutdown();
}
}
输出:
10:16:22.675 [SLOT_1027] INFO com.ebc.blot.ReportBolt:45 - 最终counts
a : 7526
b : 3763
c : 3763
10:16:22.686 [SLOT_1027] INFO com.ebc.blot.ReportBolt:52 - ---------
storm(5)-分布式单词计数例子的更多相关文章
- Storm实现单词计数
package com.mengyao.storm; import java.io.File; import java.io.IOException; import java.util.Collect ...
- Hadoop: 单词计数(Word Count)的MapReduce实现
1.Map与Reduce过程 1.1 Map过程 首先,Hadoop会把输入数据划分成等长的输入分片(input split) 或分片发送到MapReduce.Hadoop为每个分片创建一个map任务 ...
- 自定义实现InputFormat、OutputFormat、输出到多个文件目录中去、hadoop1.x api写单词计数的例子、运行时接收命令行参数,代码例子
一:自定义实现InputFormat *数据源来自于内存 *1.InputFormat是用于处理各种数据源的,下面是实现InputFormat,数据源是来自于内存. *1.1 在程序的job.setI ...
- 大数据【四】MapReduce(单词计数;二次排序;计数器;join;分布式缓存)
前言: 根据前面的几篇博客学习,现在可以进行MapReduce学习了.本篇博客首先阐述了MapReduce的概念及使用原理,其次直接从五个实验中实践学习(单词计数,二次排序,计数器,join,分 ...
- 【Storm】storm安装、配置、使用以及Storm单词计数程序的实例分析
前言:阅读笔记 storm和hadoop集群非常像.hadoop执行mr.storm执行topologies. mr和topologies最关键的不同点是:mr执行终于会结束,而topologies永 ...
- Hadoop分布环境搭建步骤,及自带MapReduce单词计数程序实现
Hadoop分布环境搭建步骤: 1.软硬件环境 CentOS 7.2 64 位 JDK- 1.8 Hadoo p- 2.7.4 2.安装SSH sudo yum install openssh-cli ...
- Storm入门2-单词计数案例学习
[本篇文章主要是通过一个单词计数的案例学习,来加深对storm的基本概念的理解以及基本的开发流程和如何提交并运行一个拓扑] 单词计数拓扑WordCountTopology实现的基本功能就是不停地读入 ...
- 分析MapReduce执行过程+统计单词数例子
MapReduce 运行的时候,会通过 Mapper 运行的任务读取 HDFS 中的数据文件,然后调用自己的方法,处理数据,最后输出.Reducer 任务会接收 Mapper 任务输出的数据,作为自己 ...
- Spark: 单词计数(Word Count)的MapReduce实现(Java/Python)
1 导引 我们在博客<Hadoop: 单词计数(Word Count)的MapReduce实现 >中学习了如何用Hadoop-MapReduce实现单词计数,现在我们来看如何用Spark来 ...
随机推荐
- dbcp的销毁
使用commons-dbcp-1.2.2.jar的DataSource,发现每次动态编译后连接池中的连接不会释放,新的连接池建立有mssql多出一组连接,只有重新启动tomcat或weblogic才可 ...
- HDU 6125 Free from square (状压DP+背包)
题意:问你从 1 - n 至多选 m 个数使得他们的乘积不能整除完全平方数. 析:首先不能整除完全平方数,那么选的数肯定不能是完全平方数,然后选择的数也不能相同的质因子. 对于1-500有的质因子至多 ...
- CodeForces 288A Polo the Penguin and Strings (水题)
题意:给定一个字符,让你用前 k 个字符把它排成 n 长度,相邻的字符不能相等,并且把字典序最小. 析:其实很简单么,我们只要多循环ab,就行,最后再把剩下的放上,要注意k为1的时候. 代码如下: # ...
- MySQL查询表内重复记录并删除
在日常业务场景中,经常会出现一个问题就是解决数据重复的问题,这里用到了一张用户表(s_user)做重复数据操作,分别包含了两个字段,id.name分别用于做唯一标示以及相同姓名的检索. 表结构以及测试 ...
- Java设置jre通过java new Date()得到的时间的时区
1.前提 由于公司有印尼的项目,该项目仅对印尼当地开放使用(公司在国内,用的是阿里云的ECS,但是阿里云在印尼没有服务器,所以就买了新加坡的服务器),印尼当地人用的是东七区的时间,所以比国内东八区的时 ...
- 20145218张晓涵 web安全基础实践
20145218张晓涵 web安全基础实践 1.实验后回答问题 SQL注入攻击原理,如何防御 SQL注入漏洞是指在Web应用对后台数据库查询语句处理存在的安全漏洞.也就是,在输入字符串中嵌入SQL指令 ...
- [LeetCode 题解]: Longest Substring Without Repeating Characters
Given a string, find the length of the longest substring without repeating characters. For example, ...
- [Erlang14]怎样模拟节点互连后的各种失败情况?
情景: 当节点群互连时,会通过心跳包检查所连接节点是不是连接正常,这个心跳时间默认为60s,可以通过 net_kernel:set_net_ticktime(600). 来重设这个时间值,怎么测试? ...
- commons工具类
转自:https://blog.csdn.net/leaderway/article/details/52387925 1.1. 开篇 在Java的世界,有很多(成千上万)开源的框架,有成功的,也有不 ...
- Flex + Bison: Scanning from memory buffer
Found from StackOverflow: ========================================================================== ...