对fastdfs 文件清单进行检查,打印无效的文件
对fastdfs 文件清单进行检查,打印无效的文件
2017年12月12日 18:37:18 守望dfdfdf 阅读数:281 标签: fastdfssftpmysql 更多
个人分类: 工作 问题
编辑
版权声明:本文为博主原创文章,转载请注明文章链接。 https://blog.csdn.net/xiaoanzi123/article/details/78752333
需求说明:
写程序 获取所有的fastdfs文件目录清单,然后去数据库进行比对【数据库某个字段就是存的fastdfs文件的目录路径】,来确认 数据库是否存在对应的数据记录。 需求目的就是确认 文件服务器文件记录 和数据库 记录不一致的有哪些数据,把他们输出出来。
困难点:
1、从没有接触过fastdfs 分布式文件系统,对其了解始于现在,但是发现一篇很不错的fastdfs介绍文章,可以学习,链接如下:
http://blog.csdn.net/wallwind/article/details/39891105
2、不知道如何获取fastdfs文件列表。在网上查阅得知 没有此需求对应的api,但发现一篇文章,只不过是python实现的。如下:
https://www.cnblogs.com/xiaolinstudy/p/7777123.html python 才刚刚接触,一脸茫然。。。。。
目前已知的的是,在百度上了解:“”没有这样的API。如果确实需要这个功能,可以分析data/sync/目录下的binlog文件。“”
刚刚向老同学咨询下这个问题,真是一语点醒梦中人。他说把上面的python代码和这句话联系起来 。
解决问题的过程中自己只在表面,没有深入,如果想要深入长远发展下去,这种坏习惯要不得,自己以后必须要注意。
回归正题:
首先我要找到fastdfs所在的linux服务器,从没见过,我想看看这个binlog到底是个什么玩意,还有fastdfs配置的 base_path 路径我也不知道。
折腾半天才在运维系统平台找到文件服务器linux对应ip,又找人问了root 的密码。
我以为data目录 在 / 下,发现没有。那就先找base_path路径。
翻阅博客发现 在 /etc/fdfs 目录下,有storage.conf 和 tracker.conf 两个配置文件。
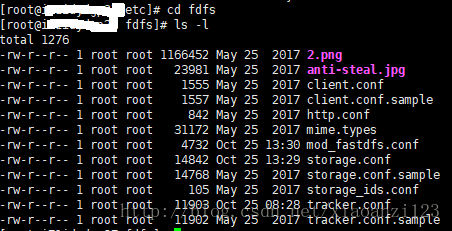
了解到tracker用于控制调度的,storage用于具体的执行。所以打开storage.conf查看。
【注:我第一次打开的tracker.conf,打开发现base_path,按照路径去找没有找到想要的binlog文件】,打开storage.conf,发现配置的base_path,

按照这个路径去找,果然发现了期待的data目录,data下有sync目录,打开sync,看到了期待的binlog文件。
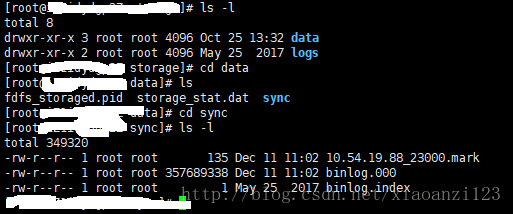
binlig.index 打开发现为空,binlog.000打开,看到了期待的数据目录信息。

接下来,要在java中远程访问这个文件,把内容读取到本地,生成文件保存。参考了这篇博客的的代码:http://blog.csdn.net/qq_29663071/article/details/50497095
代码如下:【要引入jar包 j2ssh-core-0.2.9 我会上传到资源里面。】
/*
* 远程访问 fastdfs 所在 linux服务器,获取 binlog.000 文件数据
*/
public static void getBinlog() throws IOException{
SshClient client=new SshClient();
client.connect("1xxxxx87"); //此处是fastdfs 所在的 Linux服务器IP
//设置用户名和密码
PasswordAuthenticationClient pwd = new PasswordAuthenticationClient();
pwd.setUsername("root");
pwd.setPassword("密码");
int result=client.authenticate(pwd);
if(result==AuthenticationProtocolState.COMPLETE){ //如果连接完成
File file = new File("D:\\text.txt");
OutputStream os = new FileOutputStream(file);
try{
client.openSftpClient().get("linux中binlog文件的绝对路径", os);
}catch (Exception e) {
e.printStackTrace();
System.out.println("获取binlog.000数据失败");
}
}
}
到此,成功把binlog数据储存到本地。接下来我的想法是把这个生成text.txt 文件,读取出来,每一条放入到一个list中,最后我遍历list,去和数据库中的记录对比来做验证。可是这个文件太大了,近350MB,sublime显示有616万条数据。我是第一次杰出这么大的数据量,有点慌。 ---------------------
果然,出问题了。代码如下
public static List<String> readFile(File fileRead){ 【注:已经把text.txt new 过了,作参数穿进来 】
List<String> listBinlog = new ArrayList<String>();
BufferedReader reader = null;
try {
//"以行为单位读取文件内容,一次读一整行:");
reader = new BufferedReader(new FileReader(fileRead));
String tempString = null;
//一次读入一行,直到读入null为文件结束
while ((tempString = reader.readLine()) != null) {
listBinlog.add(tempString);//我想把每一行数据放到list中。
}
reader.close();
} catch (IOException e) {
e.printStackTrace();
} finally {
if (reader != null) {
try {
reader.close();
} catch (IOException e1) {
}
}
}
return listBinlog;
}
很明显,六百多万条数据【一开始没在意到会那么多】,绝对的,内存溢出。
我就改为尝试下面两种方法
List<String> listBinlog = new ArrayList<String>();
//Java.util.Scanner类扫描文件的内容,一行一行连续地读取
FileInputStream inputStream = null;
Scanner sc = null;
try{
inputStream = new FileInputStream(path);
sc = new Scanner(inputStream,"UTF-8");
while(sc.hasNextLine()) {
String line = sc.nextLine();
listBinlog.add(line);
}
// note that Scanner suppresses exceptions
if(sc.ioException() != null) {
throw sc.ioException();
}
}finally{
if(inputStream != null) {
inputStream.close();
}
if(sc != null) {
sc.close();
}
}
return listBinlog;
-----------------------------------------
List listBinlog = new ArrayList<String>();
//Apache Commons IO流 解决读取大文件 内存溢出问题
LineIterator it = FileUtils.lineIterator(fileRead, "UTF-8");
try{
while(it.hasNext()) {
String line = it.nextLine();
listBinlog.add(line);
}
}finally{
LineIterator.closeQuietly(it);
}
return listBinlog;
----------------
上面的方法参考地址:http://blog.csdn.net/win7system/article/details/53747032
结果还是内存溢出。很明显,没什么改进,又尝试初始化链表时指定容量,还不行,之所以内存溢出,就是因为那么大的数据放在一个集合中导致的。
这时经理给我进行了指导,他的意思我把这些数据每一条存到本地数据库里面,添加flag等字段,标志该条数据的比对结果。如果放在list中,就算放得下没有内存溢出,
万一出现问题,之前的遍历白费了,还要重头开始,最好有个标记。
思路开始转变,之前我也没想过 还能去用本地数据库这一点。。。 我就在mysql建表,一个字段放想要存的 fastdfs文件dir ,另外一个字段作标志位。还是之前的一行一行读取数据,把读到的每一行数据处理下(只要自己想要的那一段字符串),存到数据库里面。这时候必须考虑用批处理,但是批处理也有容量啊,要不然肯定还是内存溢出,
参考了这篇文章:http://blog.csdn.net/babyniu411/article/details/47099783, 用事务 和 批处理 结合的形式类解决这个问题。
我的代码如下:
Class.forName("com.mysql.jdbc.Driver");
Connection coon = DriverManager.getConnection("jdbc:mysql://localhost:3306/binlogdata?"
+ "user=root&password=xxxxx&useUnicode=true&characterEncoding=UTF8");
//以行 为单位 读取存入本地的 这个文件,把 每行数据处理后存到mysql中
String allFileNamePath = "text.txt文件的本地路径";
File fileRead = new File(allFileNamePath);
//System.out.println("存入数据库完毕");
FileInputStream inputStream = null;
Scanner sc = null;
inputStream = new FileInputStream(allFileNamePath);
sc = new Scanner(inputStream,"UTF-8");
int i = 1;
//多批次 按事务提交
coon.setAutoCommit(false); // 开始事务
Statement stmt = coon.createStatement();
while(sc.hasNextLine()) {
String line = sc.nextLine();
String str = line.substring(13).trim();
String sql = "INSERT INTO BINLOGDATA (DIR,ISEXIT) VALUES ('"+str+"','0')";
stmt.addBatch(sql);
i++;
if((i%50000==0&& i!=0)){
stmt.executeBatch();
coon.commit();
coon.setAutoCommit(false);// 开始事务
stmt = coon.createStatement();
}
}
coon.commit();// 提交事务
System.out.println("存入数据库完毕");
stmt.close();
coon.close();
// note that Scanner suppresses exceptions
if(sc.ioException() != null) {
throw sc.ioException();
}
因为之前我也试了一下没用批处理的方式,速度对比简直天壤之别。
根据sublime打开显示,数据一共六百多万,我发现库里id出现九百多万的编号,肯定有问题。后发现是我建表的原因,因为我把di字段设为了自增长,由于之前清空了已经插入的数据,重新插入数据,id也就从六百多万开始计数了。取消自增长,此问题解决。但是上述代码出现一个问题,最后一批数据不足
50000的那一组并没有执行插入数据库的操作【通过获取文件总行数解决】。而且有一个大bug,i++的位置放错了,应该放到循环体的最后。。。。。
下面先放上最终提交的 所有代码 :
/*
* mian()方法调用 compareFile();
对FS 文件清单检查,打印无效的文件
*
*/
public static void compareFile() throws Exception {
//getBinlog(); //获取 fastdfs 所在服务器 的binlog.000文件中的数据并存入本地文件中
Class.forName("com.mysql.jdbc.Driver");
//本地mysql数据库
String connect = "jdbc:mysql://localhost:3306/binlogdata?"
+ "user=root&password=XXXXX&useUnicode=true&characterEncoding=UTF8";
Connection coon = DriverManager.getConnection(connect);
//对取回的数据文件 进行数据处理 存储到本地mysql 中
handingFile(coon);
//从本地数据库获取数据,进行比对得出结果
//待完成
coon.close();
}
/*
* 读取 文件,数据处理后添加到本地数据库mysql中
*/
public static void handingFile(Connection coon) throws ClassNotFoundException, SQLException, IOException{
//以行 为单位 读取存入本地的 这个文件,把 每行数据处理后存到mysql中
String allFileNamePath = "D:\\text.txt";
File fileRead = new File(allFileNamePath);
FileInputStream inputStream = null;
inputStream = new FileInputStream(allFileNamePath);
//获取文件 行数
int lineNum = getLineNum(fileRead); //耗时20s
@SuppressWarnings("resource")
Scanner sc = new Scanner(inputStream,"UTF-8");
int i = 1;
//多批次 按事务提交
coon.setAutoCommit(false); // 开始事务
String sql = "INSERT INTO BINLOGDATA (DIR,exitfastdfs,ID,exitdatabase) VALUES ( ? ,'1',?,'0')";
PreparedStatement stmt = coon.prepareStatement(sql); //预编译
while(sc.hasNextLine()) {
if(i > lineNum){
break;
}
String line = sc.nextLine();
String str = line.substring(13).trim();
stmt.setString(1, str);
stmt.setInt(2, i);
stmt.addBatch();
if((i%500000==0&& i!=0 || i == lineNum)){
stmt.executeBatch();
coon.commit();
stmt.close();
coon.setAutoCommit(false);// 开始新的批次的事务
stmt = coon.prepareStatement(sql);
}
i++;
}
coon.commit();// 提交事务
System.out.println("存入数据库完毕");
coon.setAutoCommit(true);
stmt.close();
//coon.close();
// note that Scanner suppresses exceptions
if(sc.ioException() != null) {
throw sc.ioException();
}
}
/*
* 获取文件行数
*/
public static int getLineNum(File file){
int index = 0;
try {
FileReader fileReader = new FileReader(file);
BufferedReader bufferedReader = new BufferedReader(fileReader);
while (bufferedReader.readLine()!=null){
index++;
}
} catch (IOException e) {
e.printStackTrace();
}
return index;
}
/*
* 远程访问 fastdfs 所在 linux服务器,获取 binlog.000 文件数据
*/
public static void getBinlog() throws IOException{
SshClient client=new SshClient();
client.connect("xxxxxxxx"); //此处是fastdfs 所在的 Linux服务器IP
//设置用户名和密码
PasswordAuthenticationClient pwd = new PasswordAuthenticationClient();
pwd.setUsername("root");
pwd.setPassword("xxxxx");
int result=client.authenticate(pwd);
if(result==AuthenticationProtocolState.COMPLETE){ //如果连接完成
File file = new File("D:\\text.txt");
OutputStream os = new FileOutputStream(file);
try{
client.openSftpClient().get("binlog.000文件所在的服务器路径", os);
}catch (Exception e) {
e.printStackTrace();
System.out.println("获取binlog.000数据失败");
}
}
}
由于生产环境数据库无法连接,无法获取对应表中的字段来比对进行验证,所以这个任务暂时先完成到这一步。以后再说。
上述代码我还有两个疑问:
我是用分批次的事务和批出理 来吧数据填入本地mysql的。后来我把每次事务的提交改为50万,六百多万条数据大概15min左右。①这个addbatch有没有一个容量限制?合理容量是多大?
②每一个批次的事务提交后,我都把stmt关闭了,然后开启下一轮事务,在开新的stmt。从优化上讲,要不要这样,每一次关还是不关?不过connection我是最后关的,就一次。
stmt.executeBatch();
coon.commit();
stmt.close();
coon.setAutoCommit(false);// 开始新的批次的事务
stmt = coon.prepareStatement(sql);
这两个疑问有困惑,真心期待大佬赐教。若有错误欢迎指出,我一定认真接受。
-------------------------------------------------------分割线--------------------------------------------------------------
小总结:自己还是缺乏大量实战编程经验,踩过才知道有坑。因为很多地方并不是说很难,但是自己经验不足,总是犯一些低级错误,感觉路还很长很长。
对fastdfs 文件清单进行检查,打印无效的文件的更多相关文章
- window 删除文件提示指定的文件名无效或太长
方法0: 使用 chkdsk 磁盘修复工具 .单击“开始”,点击“运行”,输入cmd并回车打开命令提示符窗口: .在此窗口输入以下命令: 例如:检查并修复D分区 chkdsk D: /f 回车,输入 ...
- ajax上传文件,并检查文件类型、检查文件大小
1.使用ajaxfileupload.js的插件,但是对插件做了一处修改,才能够正常使用 修改的部分如下: uploadHttpData: function (r, type) { var data ...
- Mac下关于——你不能拷贝项目“”,因为它的名称太长或包括的字符在目的宗卷上无效。文件的删除
内容是google的,测试有效,因为用revel打包的东西删除以后有这个循环bug Mac下关于——你不能拷贝项目“”,因为它的名称太长或包括的字符在目的宗卷上无效.文件的删除 关于这个问题我找到的一 ...
- C++里面方便的打印日志到文件
ofstream write; //write只是个名字 你可以定义为任何其他的名字 write.open("D:\prj\Robot\dev\face\facerecog\facereco ...
- winds引导配置数据文件包含的os项目无效
我装了winds7与linux双系统,用easyBcd程序时,删除了一个winds7,之后winds7就进不去了, 进入winds7时显示winds未能启动,原因可能是最近更改了硬件或软件.解决此问题 ...
- Excel无法打开文件xxx.xlsx,因为文件格式或文件扩展名无效。请确定文件未损坏,并且文件扩展名与文件的格式匹配
office版本:2016 系统版本:win10 问题描述: 1.桌面新建excel表格后,打开时,提示“Excel无法打开文件xxx.xlsx,因为文件格式或文件扩展名无效.请确定文件未损坏,并且文 ...
- 打印信息,通过.jasper工具将集合输出到PDF文件 然后利用打印机打印文件
我们上一次成功的利用iReport工具制作了一张报表,并且预览了报表最后的效果,也生成了格式为“jrpxml”.“jrxml”与“jasper”的文件.这次,我们使用jasper提供的java的api ...
- Azure DevOps Server: 使用Rest Api获取拉取请求Pull Request中的变更文件清单
需求: Azure DevOps Server 的拉取请求模块,为开发团队提供了强大而且灵活的代码评审功能.拉取请求中变更文件清单,对质量管理人员,是一个宝贵的材料.质量保障人员可以从代码清单中分析不 ...
- 编程检查d:\test.txt文件是否存在,若在则显示该文件的名称和内容。
下面放两种方法 老师写的: import java.io.File; import java.io.FileInputStream; import java.io.FileNotFoundExcept ...
随机推荐
- 洛谷 P3806 【模板】点分治1
P3806 [模板]点分治1 题目背景 感谢hzwer的点分治互测. 题目描述 给定一棵有n个点的树 询问树上距离为k的点对是否存在. 输入输出格式 输入格式: n,m 接下来n-1条边a,b,c描述 ...
- CI框架源码学习笔记6——Config.php
接着上一节往下,我们这一节来看看配置类Config.php,对应手册内容http://codeigniter.org.cn/user_guide/libraries/config.html. clas ...
- 牛客寒假算法基础集训营4 E applese 涂颜色
链接:https://ac.nowcoder.com/acm/contest/330/E 精通程序设计的 Applese 叕写了一个游戏. 在这个游戏中,有一个 n 行 m 列的方阵.现在它要为这个方 ...
- 小程序渲染问题:ios显示安卓不显示
问题描述: 测试库转到正式库后添加数据,小程序数据渲染不出来,但是测试库没问题,ios数据能显示,没问题,但是安卓显示没数据. 排除是服务器https证书问题,如果是证书问题,小程序会直接调不了接口. ...
- Jira的安装使用
1.什么是JIRA JIRA是目前比较流行的基于Java架构的管理系统,由于Atlassian公司对很多开源项目实行免费提供缺陷跟踪服务,因此在开源领域,其认知度比其他的产品要高得多,而且易用性也好一 ...
- Luogu P2107 小Z的AK计划 堆贪心
好久不做这种题了... 存一下每个点的位置和时间,由于达到某个位置跟之前去哪里AK的无关,所以在时间超限后,可以用大根堆弹掉之前消耗时间最大的,来更新答案,相当于去掉之前花费最大的,直到时间不在超限. ...
- Linux内核硬件访问技术
① 驱动程序控制设备,主要是通过访问设备内的寄存器来达到控制目的.因此我们讨论如何访问硬件,就成了如何访问这些寄存器. ② 在Linux系统中,无论是内核程序还是应用程序,都只能使用虚拟地址,而芯片手 ...
- SQL server数据库端口访问法
最近数据库连接,也是无意中发现了这个问题,数据库可根据端口来连接 我用的是sql2014测试的,在安装其他程序是默认安装了sql(sql的tcp/ip端口为xxx),服务也不相同,但是由于比较不全,我 ...
- python模块之HTMLParser简介
html.parser是一个非常简单和实用的库,它的核心是HTMLParser类. 工作的流程是:当你feed给它一个类似HTML格式的字符串时,它会调用goahead方法向前迭代各个标签,并调用对应 ...
- my28_mysql内存占用过高降低的方法
对mysql做压力测试,测试完之后,mysql的内存一直不下降 $ free -m total used free shared buff/cache available Mem: Swap: # t ...