基于物品过滤的Slope One 算法
Slope One 算法是由 Daniel Lemire 教授在 2005 年提出的一个 Item-Based 推荐算法。 他的主要优点是简单,易于扩展。实际上有多个Slope One算法,在此主要学习加权的Slope One算法。它将分为两步,第一步 为计算所有物品间的偏差,第二步利用偏差进行预测。下面分两步介绍该算法,并给出python实现的程序。
第一步 : 计算偏差
基于下面用户对乐队的评分例子:
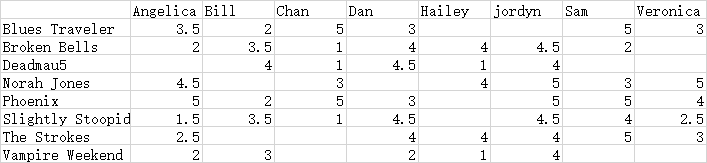
先计算偏差,物品 i 到物品 j 的平均偏差为:
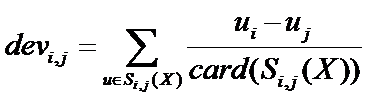
其中card(S)表示S中元素的个数,X是整个评分集合。因此card(Si,j(X))是所有同时对 i 和 j 进行评分的用户集合。从公式容易可以看出:
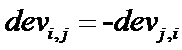
然后是维护问题,考虑如下问题:倘若又有新用户对其中的10个物品进行了评分,我们是否有必要重新计算dev矩阵。显然如果重新计算,性能问题将成为瓶颈,计算量会大的惊人。然而只要我们事先记录了两个物品的偏差同时,还记录下同时对两个物品评分的用户数目即可。这样可以在旧数据基础上更新了,大大减少了运算量,这也是Slope one算法的一个优点,易于维护。
第二步,利用加权Slope One 算法进行预测
Slope One的预测公式如下:
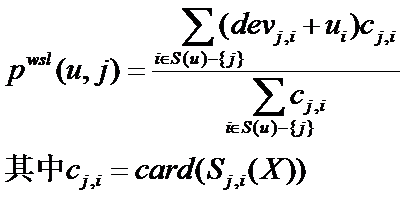
Pwsl(u,j)指的是利用加权Slope One算法给出用户 u 对物品 j 的评分预测值。S(u)表示所有u评级过的物品的集合。实际上这个加权的权重根据评分用户数得出的。
基于python的实现:
#!/usr/bin/env python
# -*- coding: utf-8 -*-
# __author__ : '小糖果' import json
import sys
from math import sqrt
from pprint import pprint class Recommender(object):
def __init__(self,data):
'''
frequencies用来记录共同评价i,j物品的用户数目
deviations用来记录物品i与j的评分差值
'''
self.frequencies = {}
self.deviations = {}
self.data = data def computeDeviations(self):
"""
计算dev(i,j)以及同时评级i,j物品的用户数,data数据为
json格式的字典
""" '''遍历每一个人的评分记录'''
for ratings in self.data.values():
for (item,rating) in ratings.items():
self.frequencies.setdefault(item,{})
self.deviations.setdefault(item,{})
''' item和item2是该用户评分记录中的两个物品'''
for (item2,rating2) in ratings.items():
if item != item2:
self.frequencies[item].setdefault(item2,0)
self.deviations[item].setdefault(item2,0.)
self.frequencies[item][item2] += 1
self.deviations[item][item2] += rating - rating2
# 接下来计算dev
for (item,ratings) in self.deviations.items():
for item2 in ratings:
self.deviations[item][item2] /= self.frequencies[item][item2] def slopeOneRecommendations(self,username):
userRatings = self.data[username]
recommendtions = {}
frequencies = {}
for (userItem,userRating) in userRatings.items():
for (diffItem,diffRatings) in self.deviations.items():
if diffItem not in userRatings and \
userItem in diffRatings:
freq = self.frequencies[diffItem][userItem]
recommendtions.setdefault(diffItem,0.)
frequencies.setdefault(diffItem,0)
recommendtions[diffItem] += \
(self.deviations[diffItem][userItem] + userRating)*freq
frequencies[diffItem] += freq
recommendtions = [(item,rating/frequencies[item])\
for (item,rating) in recommendtions.items()]
recommendtions.sort(key = lambda ele:ele[1],reverse = True)
return recommendtions def test():
with open('records.json','r') as f:
users = json.load(f)
instance = Recommender(users)
instance.computeDeviations()
print instance.slopeOneRecommendations('Bill') if __name__ == '__main__':
test()
基于物品过滤的Slope One 算法的更多相关文章
- 基于物品的协同过滤推荐算法——读“Item-Based Collaborative Filtering Recommendation Algorithms” .
ligh@local-host$ ssh-copy-id -i ~/.ssh/id_rsa.pub root@192.168.0.3 基于物品的协同过滤推荐算法--读"Item-Based ...
- Spark 基于物品的协同过滤算法实现
J由于 Spark MLlib 中协同过滤算法只提供了基于模型的协同过滤算法,在网上也没有找到有很好的实现,所以尝试自己实现基于物品的协同过滤算法(使用余弦相似度距离) 算法介绍 基于物品的协同过滤算 ...
- 基于物品的协同过滤算法(ItemCF)
最近在学习使用阿里云的推荐引擎时,在使用的过程中用到很多推荐算法,所以就研究了一下,这里主要介绍一种推荐算法—基于物品的协同过滤算法.ItemCF算法不是根据物品内容的属性计算物品之间的相似度,而是通 ...
- 【笔记6】用pandas实现条目数据格式的推荐算法 (基于物品的协同)
''' 基于物品的协同推荐 矩阵数据 说明: 1.修正的余弦相似度是一种基于模型的协同过滤算法.我们前面提过,这种算法的优势之 一是扩展性好,对于大数据量而言,运算速度快.占用内存少. 2.用户的评价 ...
- 【笔记5】用pandas实现矩阵数据格式的推荐算法 (基于物品的协同)
''' 基于物品的协同推荐 矩阵数据 说明: 1.修正的余弦相似度是一种基于模型的协同过滤算法.我们前面提过,这种算法的优势之 一是扩展性好,对于大数据量而言,运算速度快.占用内存少. 2.用户的评价 ...
- 推荐召回--基于物品的协同过滤:ItemCF
目录 1. 前言 2. 原理&计算&改进 3. 总结 1. 前言 说完基于用户的协同过滤后,趁热打铁,我们来说说基于物品的协同过滤:"看了又看","买了又 ...
- 转】Mahout分步式程序开发 基于物品的协同过滤ItemCF
原博文出自于: http://blog.fens.me/hadoop-mahout-mapreduce-itemcf/ 感谢! Posted: Oct 14, 2013 Tags: Hadoopite ...
- 基于物品的协同过滤item-CF 之电影推荐 python
推荐算法有基于协同的Collaboration Filtering:包括 user Based和item Based:基于内容 : Content Based 协同过滤包括基于物品的协同过滤和基于用户 ...
- Music Recommendation System with User-based and Item-based Collaborative Filtering Technique(使用基于用户及基于物品的协同过滤技术的音乐推荐系统)【更新】
摘要: 大数据催生了互联网,电子商务,也导致了信息过载.信息过载的问题可以由推荐系统来解决.推荐系统可以提供选择新产品(电影,音乐等)的建议.这篇论文介绍了一个音乐推荐系统,它会根据用户的历史行为和口 ...
随机推荐
- lombok 去除麻烦的实体类get和set,toString书写
首先在pom.xml中添加 <dependency> <groupId>org.projectlombok</groupId> <artifactId> ...
- free、vmstat监视内存使用情况
9. free 查询可用内存 free工具用来查看系统可用内存: /opt/app/tdev1$free total used free shared buffers cached Mem: 8175 ...
- P4305 [JLOI2011]不重复数字
题目描述 给出N个数,要求把其中重复的去掉,只保留第一次出现的数. 例如,给出的数为1 2 18 3 3 19 2 3 6 5 4,其中2和3有重复,去除后的结果为1 2 18 3 19 6 5 4. ...
- [洛谷P2613]【模板】有理数取余
题目大意:给你$a,b(a,b\leqslant10^{10001})$,求出$\dfrac a b\equiv1\pmod{19260817}$,无解输出 Angry! 题解:在读入的时候取模,若$ ...
- 2013年 ACMICPC 杭州赛区H题
思路:树状数组统计.待验证,不知道是否对. #include<cstdio> #include<cstring> #include<cmath> #include& ...
- BZOJ3597 [Scoi2014]方伯伯运椰子 【二分 + 判负环】
题目链接 BZOJ3597 题解 orz一眼过去一点思路都没有 既然是流量网络,就要借鉴网络流的思想了 我们先处理一下那个比值,显然是一个分数规划,我们二分一个\(\lambda = \frac{X ...
- centos 7 firewall无法启动
报错信息: [root@localhost bin]# systemctl status firewalld● firewalld.service - firewalld - dynamic fire ...
- 平衡二叉树DSW算法
#include<iostream> #include<stdlib.h> #include<math.h> using namespace std; class ...
- .net framework 2.0使用扩展方法
.net framework中使用扩展方法,由网摘上看到,是因为编译器将扩展方法带上了ExtensionAttribute特性 要在.net framework 2.0中使用的话,可以自定义一个特性: ...
- mysql server5.7 找不到my.ini,只有my-default.ini【mysql全局配置文件】
起因是在尝试将csv文件导入mysql的table时,出现如下错误: “The MySQL server is running with the --secure-file-priv option s ...