基于物品过滤的Slope One 算法
Slope One 算法是由 Daniel Lemire 教授在 2005 年提出的一个 Item-Based 推荐算法。 他的主要优点是简单,易于扩展。实际上有多个Slope One算法,在此主要学习加权的Slope One算法。它将分为两步,第一步 为计算所有物品间的偏差,第二步利用偏差进行预测。下面分两步介绍该算法,并给出python实现的程序。
第一步 : 计算偏差
基于下面用户对乐队的评分例子:
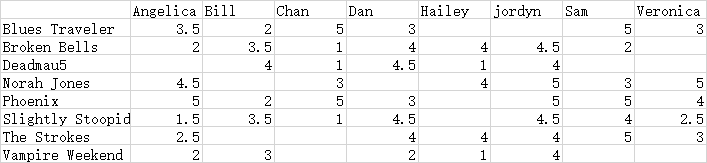
先计算偏差,物品 i 到物品 j 的平均偏差为:
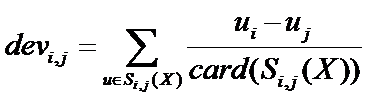
其中card(S)表示S中元素的个数,X是整个评分集合。因此card(Si,j(X))是所有同时对 i 和 j 进行评分的用户集合。从公式容易可以看出:
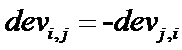
然后是维护问题,考虑如下问题:倘若又有新用户对其中的10个物品进行了评分,我们是否有必要重新计算dev矩阵。显然如果重新计算,性能问题将成为瓶颈,计算量会大的惊人。然而只要我们事先记录了两个物品的偏差同时,还记录下同时对两个物品评分的用户数目即可。这样可以在旧数据基础上更新了,大大减少了运算量,这也是Slope one算法的一个优点,易于维护。
第二步,利用加权Slope One 算法进行预测
Slope One的预测公式如下:
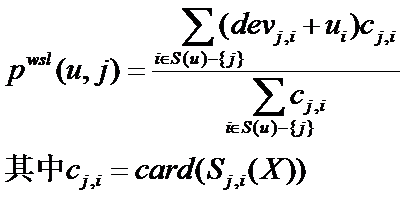
Pwsl(u,j)指的是利用加权Slope One算法给出用户 u 对物品 j 的评分预测值。S(u)表示所有u评级过的物品的集合。实际上这个加权的权重根据评分用户数得出的。
基于python的实现:
#!/usr/bin/env python
# -*- coding: utf-8 -*-
# __author__ : '小糖果' import json
import sys
from math import sqrt
from pprint import pprint class Recommender(object):
def __init__(self,data):
'''
frequencies用来记录共同评价i,j物品的用户数目
deviations用来记录物品i与j的评分差值
'''
self.frequencies = {}
self.deviations = {}
self.data = data def computeDeviations(self):
"""
计算dev(i,j)以及同时评级i,j物品的用户数,data数据为
json格式的字典
""" '''遍历每一个人的评分记录'''
for ratings in self.data.values():
for (item,rating) in ratings.items():
self.frequencies.setdefault(item,{})
self.deviations.setdefault(item,{})
''' item和item2是该用户评分记录中的两个物品'''
for (item2,rating2) in ratings.items():
if item != item2:
self.frequencies[item].setdefault(item2,0)
self.deviations[item].setdefault(item2,0.)
self.frequencies[item][item2] += 1
self.deviations[item][item2] += rating - rating2
# 接下来计算dev
for (item,ratings) in self.deviations.items():
for item2 in ratings:
self.deviations[item][item2] /= self.frequencies[item][item2] def slopeOneRecommendations(self,username):
userRatings = self.data[username]
recommendtions = {}
frequencies = {}
for (userItem,userRating) in userRatings.items():
for (diffItem,diffRatings) in self.deviations.items():
if diffItem not in userRatings and \
userItem in diffRatings:
freq = self.frequencies[diffItem][userItem]
recommendtions.setdefault(diffItem,0.)
frequencies.setdefault(diffItem,0)
recommendtions[diffItem] += \
(self.deviations[diffItem][userItem] + userRating)*freq
frequencies[diffItem] += freq
recommendtions = [(item,rating/frequencies[item])\
for (item,rating) in recommendtions.items()]
recommendtions.sort(key = lambda ele:ele[1],reverse = True)
return recommendtions def test():
with open('records.json','r') as f:
users = json.load(f)
instance = Recommender(users)
instance.computeDeviations()
print instance.slopeOneRecommendations('Bill') if __name__ == '__main__':
test()
基于物品过滤的Slope One 算法的更多相关文章
- 基于物品的协同过滤推荐算法——读“Item-Based Collaborative Filtering Recommendation Algorithms” .
ligh@local-host$ ssh-copy-id -i ~/.ssh/id_rsa.pub root@192.168.0.3 基于物品的协同过滤推荐算法--读"Item-Based ...
- Spark 基于物品的协同过滤算法实现
J由于 Spark MLlib 中协同过滤算法只提供了基于模型的协同过滤算法,在网上也没有找到有很好的实现,所以尝试自己实现基于物品的协同过滤算法(使用余弦相似度距离) 算法介绍 基于物品的协同过滤算 ...
- 基于物品的协同过滤算法(ItemCF)
最近在学习使用阿里云的推荐引擎时,在使用的过程中用到很多推荐算法,所以就研究了一下,这里主要介绍一种推荐算法—基于物品的协同过滤算法.ItemCF算法不是根据物品内容的属性计算物品之间的相似度,而是通 ...
- 【笔记6】用pandas实现条目数据格式的推荐算法 (基于物品的协同)
''' 基于物品的协同推荐 矩阵数据 说明: 1.修正的余弦相似度是一种基于模型的协同过滤算法.我们前面提过,这种算法的优势之 一是扩展性好,对于大数据量而言,运算速度快.占用内存少. 2.用户的评价 ...
- 【笔记5】用pandas实现矩阵数据格式的推荐算法 (基于物品的协同)
''' 基于物品的协同推荐 矩阵数据 说明: 1.修正的余弦相似度是一种基于模型的协同过滤算法.我们前面提过,这种算法的优势之 一是扩展性好,对于大数据量而言,运算速度快.占用内存少. 2.用户的评价 ...
- 推荐召回--基于物品的协同过滤:ItemCF
目录 1. 前言 2. 原理&计算&改进 3. 总结 1. 前言 说完基于用户的协同过滤后,趁热打铁,我们来说说基于物品的协同过滤:"看了又看","买了又 ...
- 转】Mahout分步式程序开发 基于物品的协同过滤ItemCF
原博文出自于: http://blog.fens.me/hadoop-mahout-mapreduce-itemcf/ 感谢! Posted: Oct 14, 2013 Tags: Hadoopite ...
- 基于物品的协同过滤item-CF 之电影推荐 python
推荐算法有基于协同的Collaboration Filtering:包括 user Based和item Based:基于内容 : Content Based 协同过滤包括基于物品的协同过滤和基于用户 ...
- Music Recommendation System with User-based and Item-based Collaborative Filtering Technique(使用基于用户及基于物品的协同过滤技术的音乐推荐系统)【更新】
摘要: 大数据催生了互联网,电子商务,也导致了信息过载.信息过载的问题可以由推荐系统来解决.推荐系统可以提供选择新产品(电影,音乐等)的建议.这篇论文介绍了一个音乐推荐系统,它会根据用户的历史行为和口 ...
随机推荐
- openssl unicode编译以及VC++2015环境下的问题
这几天需要使用openssl,前期本机上保存的目录不知道哪天整理的时候删除了,索性下载最新的自己编译一下: 在最新版的openssl(openssl-1.0.2e),编译过程中出现了很多问题,这里主要 ...
- jquery radio 行选中 操作
想实现点击一行中任意位置 此行的 radio 选中. function rowClick(t) { var id = $(t).attr("id").substr(3, 1); / ...
- 【bzoj2770】YY的Treap 权值线段树
题目描述 志向远大的YY小朋友在学完快速排序之后决定学习平衡树,左思右想再加上SY的教唆,YY决定学习Treap.友爱教教父SY如砍瓜切菜般教会了YY小朋友Treap(一种平衡树,通过对每个节点随机分 ...
- 关于CPU位数,OS位数以及内存大小关系的一点总结
(这个学期做助教,说来好惭愧啊,虽然我也是考研进来的,但是就在两年前复习的资料居然全部都忘光了.对大二的孩子们提问的问题多半都解决不了!!!越来越觉得自己的学习方法有问题了,总是想着一些知识能够根据自 ...
- (转)myeclipse工程 junit不能运行 ClassNotFoundException
博文转自:http://www.cnblogs.com/java-zone/articles/2730722.html myeclipse工程 junit不能运行 1 2 3 4 5 6 7 8 ...
- js得到时间戳(10位数)
//从1970年开始的毫秒数然后截取10位变成 从1970年开始的秒数 function timest() { var tmp = Date.parse( new Date() ).toString( ...
- nutch 2.1安装问题集锦
参照官方文档http://nlp.solutions.asia/?p=180 中间碰到的问题,解决方法参考 http://blog.javachen.com/2014/05/20/nutch-intr ...
- (原创)Linux下MySQL 5.5/5.6的修改字符集编码为UTF8(彻底解决中文乱码问题)
« CloudStack+XenServer详细部署方案(10):高级网络功能应用 (总结)CentOS Linux 5.x在GPT分区不能引导的解决方法 » 2013-1 11 (原创)Linux下 ...
- DotNETCore 学习笔记 路由
Route ------------------------------------------constraint------------------------------------------ ...
- 杭电oj2072
因为一直不能ac先发这里,希望有看到的大佬能指点一二. 先讲一下我的基本思路,首先将一整行数据保存在数组中,接着遍历数组,根据空格将每个单词存入二维数组中,最后遍历二维数组,找出其中不同的单词并计数. ...