马士兵hadoop第四课:Yarn和Map/Reduce配置启动和原理讲解(转)
马士兵hadoop第一课:虚拟机搭建和安装hadoop及启动
马士兵hadoop第二课:hdfs集群集中管理和hadoop文件操作
马士兵hadoop第四课:Yarn和Map/Reduce配置启动和原理讲解
前三节课主要讲了hdfs,hdfs就是一个分鱼展的大硬盘
分:分块
鱼:冗余
展:动态扩展
接下来讲云计算,也可以理解为分布式计算,其设计原则:
移动计算,而不是移动数据
前面说过,hadoop由hdfs,yarn,map/reduce组成,
而yarn(Yet Another Resource Negotiator)是资源调度系统,yarn调配的是内存和cpu,不参入计算。
map/reduce是计算引擎。
(1)配置yarn
yarn由一台resourceManager和n台dataManager组成,resourceManager管理着n台dataManager,
resourceManager原则上应该和namenode分开,单独在一个节点上,现在是在做实验,为了演示方便,
才放在一起的,而dataManager可以和datanode放在一起,这样dataManager和数据离的近一点,
当然也可以不放在一起。
要启动yarn系统,需要先配置一些参数:
a)配置yarn-size.xml
resourceManager和dataManager每一个节点都需要配置yarn-size.xml,配置如下:

<?xml version="1.0"?>
<configuration>
<property>
<name>yarn.resourcemanager.hostname</name>
<value>master</value>
</property> <property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property> <property>
<name>yarn.nodemanager.auxservices.mapreduce.shuffle.class</name>
<value>org.apache.hadoop.mapred.ShuffleHandler</value>
</property>
</configuration>
b) 配置mapred-site.xml
只需要在master的/usr/local/hadoop/etc/hadoop目录下,
复制mapred-site.xml.template,即执行命令
[root@master hadoop]# cp mapred-site.xml.template mapred-site.xml
编辑mapred-site.xml,vim mapred-site.xml:
<?xml version="1.0"?>
<?xml-stylesheet type="text/xsl" href="configuration.xsl"?>
<configuration>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
</configuration>
这是配置map/reduce在哪个系统上运行,这里配置的yarn,也可以配置其他的。
(2)启动yarn
[root@master hadoop]# start-yarn.sh
使用jps查看启动情况
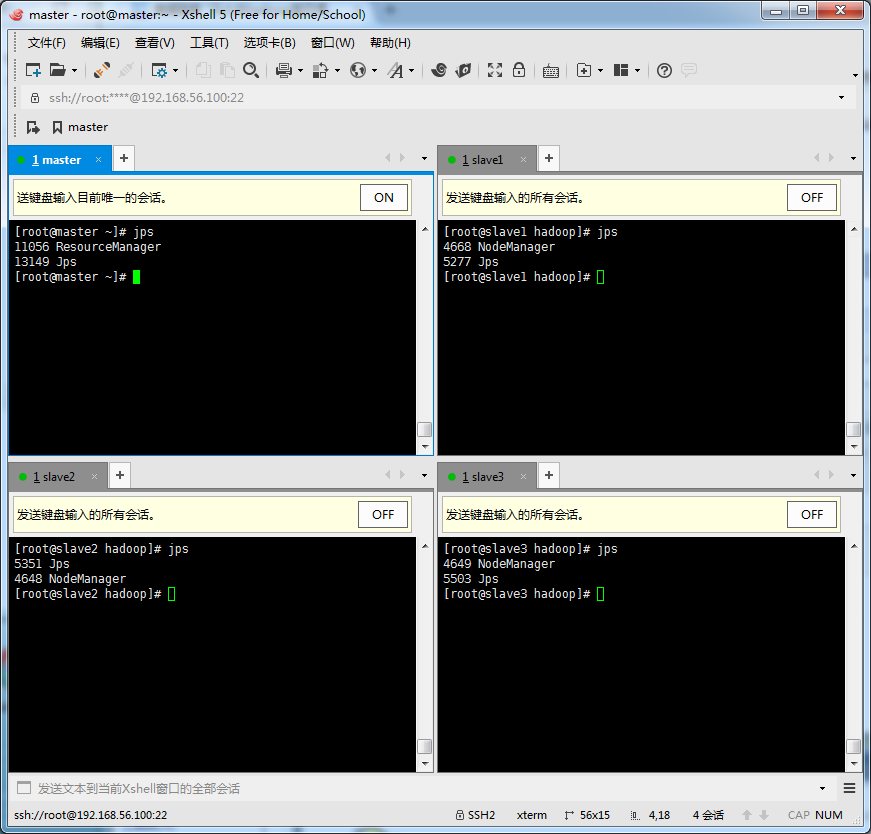
启动成功后,可在浏览器上查看web界面

(3)运行一个map/reduce示例程序
要先把hdfs也启动起来:
[root@master hadoop]# start-dfs.sh
上传一个文件到hdfs的/input目录上
#在namenode的根目录上创建input目录
[root@master hadoop]# hadoop fs -mkdir /input
#上传一个测试文件到hadoop的/input目录上
[root@master hadoop]# hadoop fs -put /root/input.txt /input
input.txt的内容如下:

find /usr/local/hadoop -name *example*.jar 查找示例程序文件
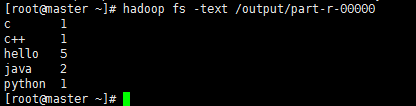
通过hadoop jar xxx.jar wordcount /input /output来运行示例程序
执行结果为:
原文地址:http://www.cnblogs.com/yucongblog/p/6650861.html
马士兵hadoop第四课:Yarn和Map/Reduce配置启动和原理讲解(转)的更多相关文章
- 马士兵hadoop第四课:Yarn和Map/Reduce配置启动和原理讲解
马士兵hadoop第一课:虚拟机搭建和安装hadoop及启动 马士兵hadoop第二课:hdfs集群集中管理和hadoop文件操作 马士兵hadoop第三课:java开发hdfs 马士兵hadoop第 ...
- 马士兵hadoop第三课:java开发hdfs
马士兵hadoop第一课:虚拟机搭建和安装hadoop及启动 马士兵hadoop第二课:hdfs集群集中管理和hadoop文件操作 马士兵hadoop第三课:java开发hdfs 马士兵hadoop第 ...
- 马士兵hadoop第五课:java开发Map/Reduce
马士兵hadoop第一课:虚拟机搭建和安装hadoop及启动 马士兵hadoop第二课:hdfs集群集中管理和hadoop文件操作 马士兵hadoop第三课:java开发hdfs 马士兵hadoop第 ...
- 马士兵hadoop第三课:java开发hdfs(转)
马士兵hadoop第一课:虚拟机搭建和安装hadoop及启动 马士兵hadoop第二课:hdfs集群集中管理和hadoop文件操作 马士兵hadoop第三课:java开发hdfs 马士兵hadoop第 ...
- 马士兵hadoop第五课:java开发Map/Reduce(转)
马士兵hadoop第一课:虚拟机搭建和安装hadoop及启动 马士兵hadoop第二课:hdfs集群集中管理和hadoop文件操作 马士兵hadoop第三课:java开发hdfs 马士兵hadoop第 ...
- 马士兵hadoop第二课:hdfs集群集中管理和hadoop文件操作
马士兵hadoop第一课:虚拟机搭建和安装hadoop及启动 马士兵hadoop第二课:hdfs集群集中管理和hadoop文件操作 马士兵hadoop第三课:java开发hdfs 马士兵hadoop第 ...
- 马士兵hadoop第二课:hdfs集群集中管理和hadoop文件操作(转)
马士兵hadoop第一课:虚拟机搭建和安装hadoop及启动 马士兵hadoop第二课:hdfs集群集中管理和hadoop文件操作 马士兵hadoop第三课:java开发hdfs 马士兵hadoop第 ...
- 马士兵hadoop第一课:虚拟机搭建和安装hadoop及启动(转)
马士兵hadoop第一课:虚拟机搭建和安装hadoop及启动 马士兵hadoop第二课:hdfs集群集中管理和hadoop文件操作 马士兵hadoop第三课:java开发hdfs 马士兵hadoop第 ...
- hadoop学习WordCount+Block+Split+Shuffle+Map+Reduce技术详解
转自:http://blog.csdn.net/yczws1/article/details/21899007 纯干货:通过WourdCount程序示例:详细讲解MapReduce之Block+Spl ...
随机推荐
- 通过存储过程批量生成spool语句
过存储过程批量生成spool语句 CREATE OR REPLACE PROCEDURE pro_yx_full_txt IS export_handle UTL_FILE.file_type; v_ ...
- C08 C语言预处理命令
目录 宏定义 文件包含 条件编译 预处理命令 C语言的预处理:在编译之前进行的处理,不进行编译. C语言的预处理功能有: 宏定义 文件包含 条件编译 预处理命令以符号“#”开头.. 宏定义 不带参数的 ...
- Java删除开头和末尾字符串
//扩展2个String方法 /* * 删除开头字符串 */ public static String trimstart(String inStr, String prefix) { if (inS ...
- iOS 解决ipv6问题
解决ipv6的方法有很多种,由于现在国内的网络运营商还在使用ipv4的网络环境,所以appstore应用不可能大范围去修改自己的服务器, 而且国内的云服务器几乎没有ipv6地址. 这里附上苹果开发平台 ...
- Your Ride Is Here
纯粹的水题= = /* ID:yk652321 LANG:C++ TASK:ride */ #include<iostream> #include<cstring> #incl ...
- Python自学笔记_
1. if语句 判断语句. 1 a=2 2 b=3 3 if a>b: 4 print("a>b") 5 else: 6 print("a<b" ...
- LeetCode(303)Range Sum Query - Immutable
题目 Given an integer array nums, find the sum of the elements between indices i and j (i ≤ j), inclus ...
- HDU - 4027 Can you answer these queries?(线段树)
给定一个长度为n的序列,m次操作. 每次操作 可以将一个区间内的所有数字变为它的根号. 可以查询一个区间内所有元素的和. 线段树的初级应用. 如果把一个区间内的元素都改为它的根号的话,是需要每个数字都 ...
- linux学习-CentOS 7 环境下大量建置账号的方法
一些账号相关的检查工具 pwck pwck 这个指令在检查 /etc/passwd 这个账号配置文件内的信息,与实际的家目录是否存在等信息, 还可以比对 /etc/passwd /etc/shadow ...
- Python之code对象与pyc文件(二)
上一节:Python之code对象与pyc文件(一) 创建pyc文件的具体过程 前面我们提到,Python在通过import或from xxx import xxx时会对module进行动态加载,如果 ...