pytorch 加载数据集
pytorch初学者,想加载自己的数据,了解了一下数据类型、维度等信息,方便以后加载其他数据。
1 torchvision.transforms实现数据预处理
transforms.Totensor()操作必须要有,将数据转为张量格式。
2 torch.utils.data.Dataset实现数据读取
要使用自己的数据集,需要构建Dataset子类,定义子类为MyDataset,在MyDataset的init函数中定义path_dict变量,来获取不同类型的数据的路径。
定义子类MyDataset时,必须要重载两个函数 getitem 和 len,
__getitem__:实现数据集的下标索引,返回对应的数据及标签;
__len__:返回数据集的大小。
设加载的数据集大小为L;
定义MyDataset实例:my_datasets = MyDataset(data_dir, transform = data_transform) 。
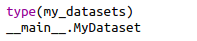
my_datasets 由L个tuple组成,len(my_datasets) = L;
每个tuple长度为2:0:tensor 样本(Channel,Height,Width)
1:int 标签




3 torch.utils.data.DataLoader实现数据集加载
torch.utils.data.DataLoader()合成数据并提供迭代访问,由两部分组成:
—dataset(Dataset):输入要加载的数据,就是上面的my_datasets;
—batch_size,shuffle,sampler,batch_sampler,num_workers,collate_fn, drop_last,timeout,worker_init_fn等参数。
其中:batch_size:批尺寸,默认为1;
shuffle:是否在每个epoch开始随机打乱数据,默认为False;
设data_loader长度为 l ;
加载数据:data_loader = DataLoader(my_datasets, batch_size = BATCH_SIZE, shuffle = True)
data_loader 由 l 个 tuple组成,l = len(data_loader) = len(my_datasets) / batch_size;
迭代访问:


e 长度为2:0:int step 表示第几个batch
1:list(长度为2)表示一个batch包含的所有样本和标签
0:tensor 样本(Batch_size,Channel,Height,Width)
1:tensor 标签 Batch_size
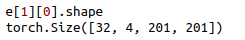

pytorch 加载数据集的更多相关文章
- pytorch 加载mnist数据集报错not gzip file
利用pytorch加载mnist数据集的代码如下 import torchvision import torchvision.transforms as transforms from torch.u ...
- SciKit-Learn 加载数据集
章节 SciKit-Learn 加载数据集 SciKit-Learn 数据集基本信息 SciKit-Learn 使用matplotlib可视化数据 SciKit-Learn 可视化数据:主成分分析(P ...
- pytorch加载语音类自定义数据集
pytorch对一下常用的公开数据集有很方便的API接口,但是当我们需要使用自己的数据集训练神经网络时,就需要自定义数据集,在pytorch中,提供了一些类,方便我们定义自己的数据集合 torch.u ...
- Pytorch加载并可视化FashionMNIST指定层(Udacity)
加载并可视化FashionMNIST 在这个notebook中,我们要加载并查看 Fashion-MNIST 数据库中的图像. 任何分类问题的第一步,都是查看你正在使用的数据集.这样你可以了解有关图像 ...
- [Pytorch]Pytorch加载预训练模型(转)
转自:https://blog.csdn.net/Vivianyzw/article/details/81061765 东风的地方 1. 直接加载预训练模型 在训练的时候可能需要中断一下,然后继续训练 ...
- [Python]-sklearn模块-机器学习Python入门《Python机器学习手册》-02-加载数据:加载数据集
<Python机器学习手册--从数据预处理到深度学习> 这本书类似于工具书或者字典,对于python具体代码的调用和使用场景写的很清楚,感觉虽然是工具书,但是对照着做一遍应该可以对机器学习 ...
- pytorch加载预训练模型参数的方式
1.直接使用默认程序里的下载方式,往往比较慢: 2.通过修改源代码,使得模型加载已经下载好的参数,修改地方如下: 通过查找自己代码里所调用网络的类,使用pycharm自带的函数查找功能(ctrl+鼠标 ...
- pytorch加载数据的方法-没弄,打算弄
参考:https://www.jianshu.com/p/aee6a3d72014 # 网络,netg为生成器,netd为判别器 netg, netd = NetG(opt), NetD(opt) # ...
- pytorch 加载训练好的模型做inference
前提: 模型参数和结构是分别保存的 1. 构建模型(# load model graph) model = MODEL() 2.加载模型参数(# load model state_dict) mode ...
随机推荐
- Maximum Control (medium) Codeforces - 958B2
https://codeforces.com/contest/958/problem/B2 题解:https://www.cnblogs.com/Cool-Angel/p/8862649.html u ...
- JetSpeed2因dom4j包冲突导致PSML页面文件数据丢失
使用JetSpeed2进行二次开发时突然出现在保存Portlet配置信息时出现PSML页面文件数据丢失的情况,几经测试,最终发现是因为Portlet中的dom4j.jar与jetspeed应用中的do ...
- python 多继承(新式类) 三
深入super 一下内容引用自:http://www.cnblogs.com/lovemo1314/archive/2011/05/03/2035005.html,写的挺好的. 代码段3 class ...
- elastcisearch中文分词器各个版本
地址 https://github.com/medcl/elasticsearch-analysis-ik/releases?after=v6.0.1
- JS中函数与事件
一.函数: 1.函数就是一个工具,通过一小段代码,完成某个功能: 2.函数的定义: function 函数名(){ ..... } 或者 : var 函数名 = function(){ ...... ...
- linux安装redis官方教程
官方链接:http://redis.io/download Download, extract and compile Redis with: $ wget http://download.redis ...
- git与GitHub(一)
相信,很多初入前端者都会对git以及GitHub不太了解,而我当时也经历过各种面试大关,也都会问:你了解git和GitHub吗?那么今天先来说一说git. 那么什么是git? (以下转载自廖雪峰老师的 ...
- 6、旋转数组的最小位置------------>剑指offer系列
题目 把一个数组最开始的若干个元素搬到数组的末尾,我们称之为数组的旋转. 输入一个非减排序的数组的一个旋转,输出旋转数组的最小元素. 例如数组{3,4,5,1,2}为{1,2,3,4,5}的一个旋转, ...
- 洛谷 P1873 砍树
砍树 二分答案,难度较低. #include <iostream> #include <cstdio> #include <algorithm> using nam ...
- CF1059B Forgery
思路: 若某个位置是‘.’,说明不能在周围的8个位置下笔.在所有可以下笔的位置填充一次,看能否“包含”需要的图案即可. 实现: #include <iostream> using name ...