SequenceFile和MapFile
HDFS和MR主要针对大数据文件来设计,在小文件处理上效率低.解决方法是选择一个容器,将这些小文件包装起来,将整个文件作为一条记录,可以获取更高效率的储存和处理,避免多次打开关闭流耗费计算资源.hdfs提供了两种类型的容器 SequenceFile和MapFile。
小文件问题解决方案 在原有HDFS基础上添加一个小文件处理模块,具体操作流程如下: 当用户上传文件时,判断该文件是否属于小文件,如果是,则交给小文件处理模块处理,否则,交给通用文件处理模块处理。在小文件模块中开启一定时任务,其主要功能是当模块中文件总size大于HDFS上block大小的文件时,则通过SequenceFile组件以文件名做key,相应的文件内容为value将这些小文件一次性写入hdfs模块。 同时删除已处理的文件,并将结果写入数据库。 当用户进行读取操作时,可根据数据库中的结果标志来读取文件。
Sequence file
Sequence file由一系列的二进制key/value组成,如果key为小文件名,value为文件内容,则可以将大批小文件合并成一个大文件。Hadoop-0.21.0版本开始中提供了SequenceFile,包括Writer,Reader和SequenceFileSorter类进行写,读和排序操作。该方案对于小文件的存取都比较自由,不限制用户和文件的多少,支持Append追加写入,支持三级文档压缩(不压缩、文件级、块级别)。其存储结构如下图所示:

SequenceFile储存
文件中每条记录是可序列化,可持久化的键值对,提供相应的读写器和排序器,写操作根据压缩的类型分为3种 :
Write 无压缩写数据。
RecordCompressWriter记录级压缩文件,只压缩值。
BlockCompressWrite块级压缩文件,键值采用独立压缩方式。
在储存结构上,sequenceFile主要由一个Header后跟多条Record组成,如图:
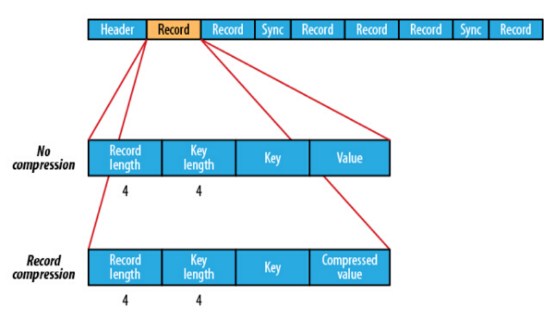
前三个字节是一个Bytes SEQ代表着版本号,同时header也包括key的名称,value class , 压缩细节,metadata,以及Sync markers。Sync markers的作用在于可以读取任意位置的数据。 在records中,又分为是否压缩格式。当没有被压缩时,key与value使用Serialization序列化写入SequenceFile。当选择压缩格式时,record的压缩格式与没有压缩其实不尽相同,除了value的bytes被压缩,key是不被压缩的。 当保存的记录很多时候,可以把一串记录组织到一起同一压缩成一块。 在Block中,它使所有的信息进行压缩,压缩的最小大小由配置文件中,io.seqfile.compress.blocksize配置项决定。
SequenceFile写操作:
通过createWrite创建SequenceFile对象,返回Write实例,指定待写入的数据流如FSDataOutputStream或FileSystem对象和Path对象。还需指定Configuration对象和键值类型(都需要能序列化)。 SequenceFile通过API来完成新记录的添加操作 fileWriter.append(key,value);
fileWriter.append(key,value);
private static void writeTest(FileSystem fs, int count, int seed, Path file,
CompressionType compressionType, CompressionCodec codec)
throws IOException {
fs.delete(file, true);
LOG.info("creating " + count + " records with " + compressionType +
" compression");
//指明压缩方式
SequenceFile.Writer writer = SequenceFile.createWriter(fs, conf, file,
RandomDatum.class, RandomDatum.class, compressionType, codec);
RandomDatum.Generator generator = new RandomDatum.Generator(seed);
for (int i = 0; i < count; i++) {
generator.next();
//keyh
RandomDatum key = generator.getKey();
//value
RandomDatum value = generator.getValue();
//追加写入
writer.append(key, value);
}
writer.close();
}
public class SequenceFileWriteDemo {
private static final String[] DATA = { "One, two, buckle my shoe", "Three, four, shut the door", "Five, six, pick up sticks", "Seven, eight, lay them straight", "Nine, ten, a big fat hen" };
public static void main(String[] args) throws IOException {
String uri = =“hdfs://master:8020/number.seq";
Configuration conf = new Configuration();
FileSystem fs = FileSystem.get(URI.create(uri), conf);
Path path = new Path(uri);
IntWritable key = new IntWritable();
Text value = new Text();
SequenceFile.Writer writer = null;
try {
writer = SequenceFile.createWriter(fs, conf, path, key.getClass(), value.getClass());
for (int i = 0; i < 100; i++) {
key.set(100 - i);
value.set(DATA[i % DATA.length]); System.out.printf("[%s]\t%s\t%s\n", writer.getLength(), key, value);
writer.append(key, value);
} }
finally { IOUtils.closeStream(writer); }
}
}
读取SequenceFile:
public class SequenceFileReadDemo {
public static void main(String[] args) throws IOException {
String uri = =“hdfs://master:8020/number.seq";
Configuration conf = new Configuration();
FileSystem fs = FileSystem.get(URI.create(uri), conf);
Path path = new Path(uri);
SequenceFile.Reader reader = null;
try {
reader = new SequenceFile.Reader(fs, path, conf);
Writable key = (Writable)
ReflectionUtils.newInstance(reader.getKeyClass(), conf);
Writable value = (Writable)
ReflectionUtils.newInstance(reader.getValueClass(), conf);
long position = reader.getPosition();
while (reader.next(key, value)) {
//同步记录的边界
String syncSeen = reader.syncSeen() ? "*" : "";
System.out.printf("[%s%s]\t%s\t%s\n", position, syncSeen, key, value);
position = reader.getPosition(); // beginning of next record
}
} finally {
IOUtils.closeStream(reader);
}
}
}

MapFile:
一个MapFile可以通过SequenceFile的地址,进行分类查找的格式。使用这个格式的优点在于,首先会将SequenceFile中的地址都加载入内存,并且进行了key值排序,从而提供更快的数据查找。 与SequenceFile只生成一个文件不同,MapFile生成一个文件夹。 索引模型按128个键建立的,可以通过io.map.index.interval来修改 缺点
1.文件不支持复写操作,不能向已存在的SequenceFile(MapFile)追加存储记录。
2.当write流不关闭的时候,没有办法构造read流。也就是在执行文件写操作的时候,该文件是不可读取的。
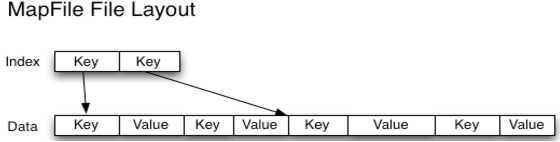
排序后的SequeneceFile,并且它会额外生成一个索引文件提供按键的查找.读写mapFile与读写SequenceFile 非常类似,只需要换成MapFile.Reader和MapFile.Writer就可以了。 在命令行显示mapFile的文件内容同样要用 -text。
MapFile写操作:
public class MapFileWriteFile
{
private static final String[] myValue={"hello world","bye world","hello hadoop","bye hadoop"};
public static void main(String[] args)
{
String uri=“hdfs://master:8020/number.map";
Configuration conf=new Configuration();
FileSystem fs=FileSystem.get(URI.create(uri),conf);
IntWritable key=new IntWritable();
Text value=new Text();
MapFile.Writer writer=null;
try
{
writer=new MapFile.Writer(conf,fs,uri,key.getClass(),value.getClass());
for(int i=0;i<500;i )
{
key.set(i);
value.set(myValue[i%myValue.length]);
writer.append(key,value);
}
finally {IOUtils.closeStream(writer);}
}
}
}
MapFile会生成2个文件 1个名data,1个名index
查看前10条data+index $ hdfs –fs –text /number.map/data | head
读取MapFile:
public class MapFileReadFile
{
public static void main(String[] args)
{
String uri=“hdfs://master:8020/number.map";
Configuration conf=new Configuration();
FileSystem fs=FileSystem.get(URI.create(uri),conf);
MapFile.Reader reader=null;
try
{
reader=new MapFile.Reader(fs,uri,conf);
WritableComparable key=(WritableComparable)ReflectionUtils.newInstance(reader.getValueClass(),conf);
while(reader.next(key,value))
{
System.out.printf("%s\t%s\n",key,value);
}
reader.get(new IntWritable(7),value);
System.out.printf("%s\n",value);
}
finally
{ IOUtils.closeStream(reader); }
}
}
SequenceFile文件是用来存储key-value数据的,但它并不保证这些存储的key-value是有序的, 而MapFile文件则可以看做是存储有序key-value的SequenceFile文件。 MapFile文件保证key-value的有序(基于key)是通过每一次写入key-value时的检查机制,这种检查机制其实很简单,就是保证当前正要写入的key-value与上一个刚写入的key-value符合设定的顺序, 但是,这种有序是由用户来保证的,一旦写入的key-value不符合key的非递减顺序,则会直接报错而不是自动的去对输入的key-value排序。
SequenceFile转换为MapFile mapFile既然是排序和索引后的SequenceFile那么自然可以把SequenceFile转换为MapFile使用mapFile.fix()方法把一个SequenceFile文件转换成MapFile
SequenceFile和MapFile的更多相关文章
- HDFS之SequenceFile和MapFile
http://blog.csdn.net/javaman_chen/article/details/7241087 Hadoop的HDFS和MapReduce子框架主要是针对大数据文件来设计的,在小文 ...
- Hadoop SequenceFile数据结构介绍及读写
在一些应用中,我们需要一种特殊的数据结构来存储数据,并进行读取,这里就分析下为什么用SequenceFile格式文件. Hadoop SequenceFile Hadoop提供的SequenceFil ...
- MapReduce中使用SequenceFile的方式上传文件到集群中
如果有很多的小文件,上传到HDFS集群,每个文件都会对应一个block块,一个block块的大小默认是128M,对于很多的小文件来说占用了非常多的block数量,就会影响到内存的消耗, MapRedu ...
- [SequenceFile_3] MapFile
0. 说明 MapFile 介绍 && 测试 1. 介绍 对 MapFile 的介绍如下: MapFile 是带有索引的 SequenceFile MapFile 是排序的 Seque ...
- 5.4.2 mapFile读写和索引
5.4.2 mapFile (1)定义 MapFile即为排序后的SequeneceFile,将sequenceFile文件按照键值进行排序,并且提供索引实现快速检索. (2)索引 索 ...
- HDFS简介【全面讲解】
http://www.cnblogs.com/chinacloud/archive/2010/12/03/1895369.html [一]HDFS简介HDFS的基本概念1.1.数据块(block)HD ...
- Hadoop集群(第8期)_HDFS初探之旅
1.HDFS简介 HDFS(Hadoop Distributed File System)是Hadoop项目的核心子项目,是分布式计算中数据存储管理的基础,是基于流数据模式访问和处理超大文件的需求而开 ...
- hadoop优点和缺点
l扩容能力(Scalable):能可靠地(reliably)存储和处理千兆字节(PB)数据. l成本低(Economical):可以通过普通机器组成的服务器群来分发以及处理数据.这些服务器群总计可达数 ...
- 非常不错 Hadoop 的HDFS (Hadoop集群(第8期)_HDFS初探之旅)
1.HDFS简介 HDFS(Hadoop Distributed File System)是Hadoop项目的核心子项目,是分布式计算中数据存储管理的基础,是基于流数据模式访问和处理超大文件的需求而开 ...
随机推荐
- Python中正则匹配使用findall时的注意事项
在使用正则搜索内容时遇到一个小坑,百度搜了一下,遇到这个坑的还不少,特此记录一下. 比如说有一个字符串 "123@qq.comaaa@163.combbb@126.comasdf111@a ...
- CodeForces 1109F. Sasha and Algorithm of Silence's Sounds
题目简述:给定一个$n \times m$的二维矩阵$a[i][j]$,其中$1 \leq nm \leq 2 \times 10^5$,矩阵元素$1 \leq a[i][j] \leq nm$且互不 ...
- 使用Spring的jdbcTemplate进一步简…
先看applicationContext.xml配置文件: 版权声明:本文为博主原创文章,未经博主允许不得转载.
- 干货:SEO长尾关键词优化方法和技巧
在网站SEO优化上,优化比较成功的网站,根据SEO界前辈的经验结论,网站的总流量主要来源于长尾关键词,占网站总流量的80%.长尾关键词主要分布在网站的文章页,其次就是栏目页title.标签页.专题页等 ...
- eos管理页面
调用此方法删除需要在po_module_processdef添加数据如下 默认情况下申请页面是有权限的 但是在此表加过之后 管理页面要打开拟稿页面还必须在 系统管理页面(xtgl.jsp ) 分 ...
- ACM-ICPC2018徐州网络赛 Hard to prepare(dp)
Hard to prepare 28.63% 1000ms 262144K After Incident, a feast is usually held in Hakurei Shrine. T ...
- 求斐波那契数列第n位的几种实现方式及性能对比(c#语言)
在每一种编程语言里,斐波那契数列的计算方式都是一个经典的话题.它可能有很多种计算方式,例如:递归.迭代.数学公式.哪种算法最容易理解,哪种算法是性能最好的呢? 这里给大家分享一下我对它的研究和总结:下 ...
- 通俗易懂,什么是.NET Core以及.NET Core能做什么
作者:依乐祝 原文地址:https://www.cnblogs.com/yilezhu/p/10880884.html 我们都知道.NET Core是一个可以用来构建现代.可伸缩和高性能的跨平台软件应 ...
- 你需要了解的有关.NET日期时间的必要信息
引言 DateTime数据类型是一个复杂的问题,复杂到足以让你在编写[将日期从Web服务器返回到浏览器]简单代码时感到困惑. ASP.NET MVC 5和 Web API 2/ASP.NETCo ...
- int **指针问题
转自:http://blog.csdn.net/u012501459/article/details/45395571 在打印二维数组时遇到了问题,二维数组可以这样定义int matrix[ROWS] ...