Python+selenium之测试报告(3)
较测试报告(2),该文章将测试报告和测试截图存放在随机变动的文件夹下面,去除了要存放在指定文件夹下面的限制。
注:遇到问题有:
1.创建由时间自动拼接的多级文件夹
2.
import os
import time current_time = time.strftime("%Y-%m-%d-%H_%M", time.localtime(time.time()))
current_time1 = time.strftime("%H_%M_%S", time.localtime(time.time()))
pic_path1 = '.\\' + current_time + "\\result\\"
pic_path = pic_path1 + "image"+"\\" + current_time1 + '.png'
os.makedirs(pic_path)
print(pic_path)
拼接好的路径要使用os.makedirs()创建对应的文件夹目录
path = pic_path1 + current_time1 + '.png'
创建好的文件夹无法再使用该路径继续创建下级路径,只能存放对应的内容
3.测试报告必须得放在测图文件的外层目录下,否者在测试报告中查找图片会报如下的错误
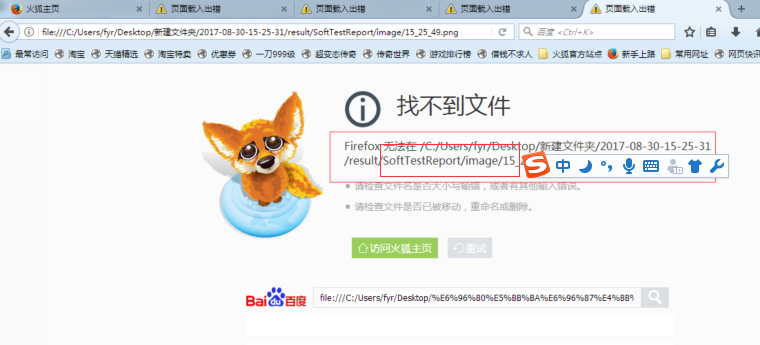
整个代码如下:
# -*- coding: utf-8 -*-
import HTMLTestReport
import HTMLTestRunner
import os
import sys
import time
import unittest
from selenium import webdriver current_time = time.strftime("%Y-%m-%d-%H-%M-%S", time.localtime(time.time()))
pic_path = '.\\' + current_time + "\\result\\"
pic_path1 = '.\\' + current_time + "\\result\\image\\"
os.makedirs(pic_path)
os.makedirs(pic_path1) class Baidu(unittest.TestCase):
def setUp(self):
self.driver = webdriver.Firefox()
self.driver.implicitly_wait(30)
self.driver.maximize_window()
self.driver.get("https://www.baidu.com")
time.sleep(5) def test_case1(self):
"""设计测试case""" # *****效果是在测试报告中显示显示出测试名称*****
print("========【case_0001】打开百度搜索 =============")
# "."表示创建的路径为当.py文件所处的地址,\\是用\将“\”转义
current_time1 = time.strftime("%H_%M_%S", time.localtime(time.time()))
path = pic_path1 + current_time1 + '.png'
print(path) # 打印图片的地址
time.sleep(5)
self.driver.save_screenshot(path) # 截图,获取测试结果
time.sleep(2)
self.assertEqual('百度一下,你就知道', self.driver.title) # 断言判断测试是否成功,判断标题是否为百度(设计失败的case) def test_case2(self):
"""设计测试过程中报错的case"""
global pic_path
print("========【case_0002】搜索selenium =============")
self.driver.find_element_by_id("kw").clear()
self.driver.find_element_by_id("kw").send_keys(u"selenium")
self.driver.find_element_by_id('su').click()
time.sleep(2)
# "."表示创建的路径为当.py文件所处的地址,\\是用\将“\”转义
current_time1 = time.strftime("%H_%M_%S", time.localtime(time.time()))
path = pic_path1 + current_time1 + '.png'
print(path) # 打印图片的地址
time.sleep(5)
self.driver.save_screenshot(path) # 截图,获取测试结果
time.sleep(2)
self.assertIn('selenium', self.driver.title) # 断言书写错误,导致case出错 def test_case3(self):
"""设计测试成功的case"""
print("========【case_0003】 搜索梦雨情殇博客=============")
self.driver.find_element_by_id("kw").clear()
self.driver.find_element_by_id("kw").send_keys(u"明道")
self.driver.find_element_by_id('su').click()
# "."表示创建的路径为当.py文件所处的地址,\\是用\将“\”转义
current_time1 = time.strftime("%H_%M_%S", time.localtime(time.time()))
path = pic_path1 + current_time1 + '.png'
print(path) # 打印图片的地址
time.sleep(5)
self.driver.save_screenshot(path) # 截图,获取测试结果
time.sleep(3)
print(self.driver.title) self.assertIn('明道', self.driver.title) def tearDown(self):
self.driver.quit() if __name__ == "__main__":
'''生成测试报告'''
current_time1 = time.strftime("%H_%M_%S", time.localtime(time.time()))
testunit = unittest.TestSuite()
testunit.addTest(Baidu("test_case1"))
testunit.addTest(Baidu("test_case2"))
testunit.addTest(Baidu("test_case3"))
report_path = pic_path + "SoftTestReport_" + current_time1 + '.html' # 生成测试报告的路径
fp = open(report_path, "wb")
runner = HTMLTestReport.HTMLTestRunner(stream=fp, title=u"自动化测试报告", description='自动化测试演示报告', tester='fyr')
# runner = HTMLTestRunner.HTMLTestRunner(stream=fp, title=u"自动化测试报告", description='自动化测试演示报告')
runner.run(testunit)
fp.close()
Python+selenium之测试报告(3)的更多相关文章
- Python+selenium之测试报告(1)
一.下载HTMLTestRunner.py HTMLTestRunner 是 Python 标准库的 unittest 模块的一个扩展.它生成易于使用的 HTML 测试报告.HTMLTestRunne ...
- Python+selenium之测试报告(2)
# -*- coding: utf-8 -*- import HTMLTestReport import HTMLTestRunner import os import sys import time ...
- python+selenium生成测试报告后自动发送邮件
标签(空格分隔): 自动化测试 运行自动化脚本后,会产生测试报告,而将测试报告自动发送给相关人员,能够让对方及时的了解测试情况,查看测试结果. 整个脚本包括三个部分: 生成测试报告 获取最新的测试报告 ...
- python selenium自动化测试报告
先记录一下,后续继续更新. 首先:HTMLTestRunner的下载地址:http://tungwaiyip.info/software/HTMLTestRunner.html 选中后单击右键,在弹出 ...
- 【转】【Python + selenium】linux和mac环境,驱动器chromedriver和测试报告HTMLTestRunner放置的位置
感谢: 作者:gz_tester,文章:<linux和mac环境,chromedriver和HTMLTestRunner放置的位置> 使用场景 配置python selenium 环境 使 ...
- python+selenium +unittest生成HTML测试报告
python+selenium+HTMLTestRunner+unittest生成HTML测试报告 首先要准备HTMLTestRunner文件,官网的HTMLTestRunner是python2语法写 ...
- 使用python selenium进行自动化functional test
Why Automation Testing 现在似乎大家都一致认同一个项目应该有足够多的测试来保证功能的正常运作,而且这些此处的‘测试’特指自动化测试:并且大多数人会认为如果还有哪个项目依然采用人工 ...
- Python Selenium设计模式-POM
前言 本文就python selenium自动化测试实践中所需要的POM设计模式进行分享,以便大家在实践中对POM的特点.应用场景和核心思想有一定的理解和掌握. 为什么要用POM 基于python s ...
- Jenkins持续集成项目搭建与实践——基于Python Selenium自动化测试(自由风格)
Jenkins简介 Jenkins是Java编写的非常流行的持续集成(CI)服务,起源于Hudson项目.所以Jenkins和Hudson功能相似. Jenkins支持各种版本的控制工具,如CVS.S ...
随机推荐
- SpringMVC前置控制器SimpleUrlHandlerMapping配置
1. <?xml version="1.0" encoding="UTF-8"?> <web-app version="2.5&qu ...
- 使用BIND安装智能DNS服务器(二)---配置rndc远程控制
首先两个BIND DNS服务器要正常运行. 主DNS服务器IP:192.168.1.100 客户机DNS服务器IP:192.168.1.101 1 主DNS端配置: cd /etc/ 生成 ...
- 手机端处理布局rem
方法一 if (document.documentElement.clientWidth > 600) {//页面宽度大于600px让其宽度等于600px,字体大小等于60px,居中 docum ...
- Java Servlet图片上传至指定文件夹并显示图片
在学习Servlet过程中,针对图片上传做了一个Demo,实现的功能是:在a页面上传图片,点击提交后,将图片保存到服务器指定路径(D:/image):跳转到b页面,b页面读取展示绝对路径(D:/ima ...
- jQuery EasyUI/TopJUI创建日期时间输入框
jQuery EasyUI/TopJUI创建日期时间输入框 日期时间输入框组件 HTML 和日期输入框类似,日期时间输入框允许用户选择日期和指定的时间并按照指定的输出格式显示.相比日期输入框,它在下拉 ...
- js 对象深拷贝
/* *p需要拷贝的对象 * */ var deepCopy=function(p, c) { var c = c || {}; for (var i in p) { if (typeof p[i] ...
- redis之使用
redis之使用 redis ================================= 1.自动分配.你在什么时候用到了自动分配? 答:市场部或运营部招来的新的客户,单条(批量)录入数据的 ...
- Vuex+axios
Vuex+axios Vuex简介 vuex是一个专门为Vue.js设计的集中式状态管理架构. 状态? 我们把它理解为在data中需要共享给其他组件使用的部分. Vuex和单纯的全局对象有以下不同 ...
- Educational Codeforces Round 65 (Rated for Div. 2) C. News Distribution
链接:https://codeforces.com/contest/1167/problem/C 题意: In some social network, there are nn users comm ...
- NET Core + Angular 2
ASP.NET Core + Angular 2 Template for Visual Studio 2017-01-11 08:45 by 小白哥哥, 2069 阅读, 19 评论, 收藏, 编辑 ...