pyspark mongodb yarn
from pyspark.sql import SparkSession my_spark = SparkSession \
.builder \
.appName("myApp") \
.config("spark.mongodb.input.uri", "mongodb://pyspark_admin:admin123@192.168.2.51/pyspark.testpy") \
.config("spark.mongodb.output.uri", "mongodb://pyspark_admin:admin123@192.168.2.51/pyspark.testpy") \
.getOrCreate()
db_rows = my_spark.read.format("com.mongodb.spark.sql.DefaultSource").load().collect()
from pyspark.sql import SparkSession my_spark = SparkSession \
.builder \
.appName("myAppYarn") \
.master('yarn') \
.config("spark.mongodb.input.uri", "mongodb://pyspark_admin:admin123@192.168.2.51/pyspark.testpy") \
.config("spark.mongodb.output.uri", "mongodb://pyspark_admin:admin123@192.168.2.51/pyspark.testpy") \
.getOrCreate()
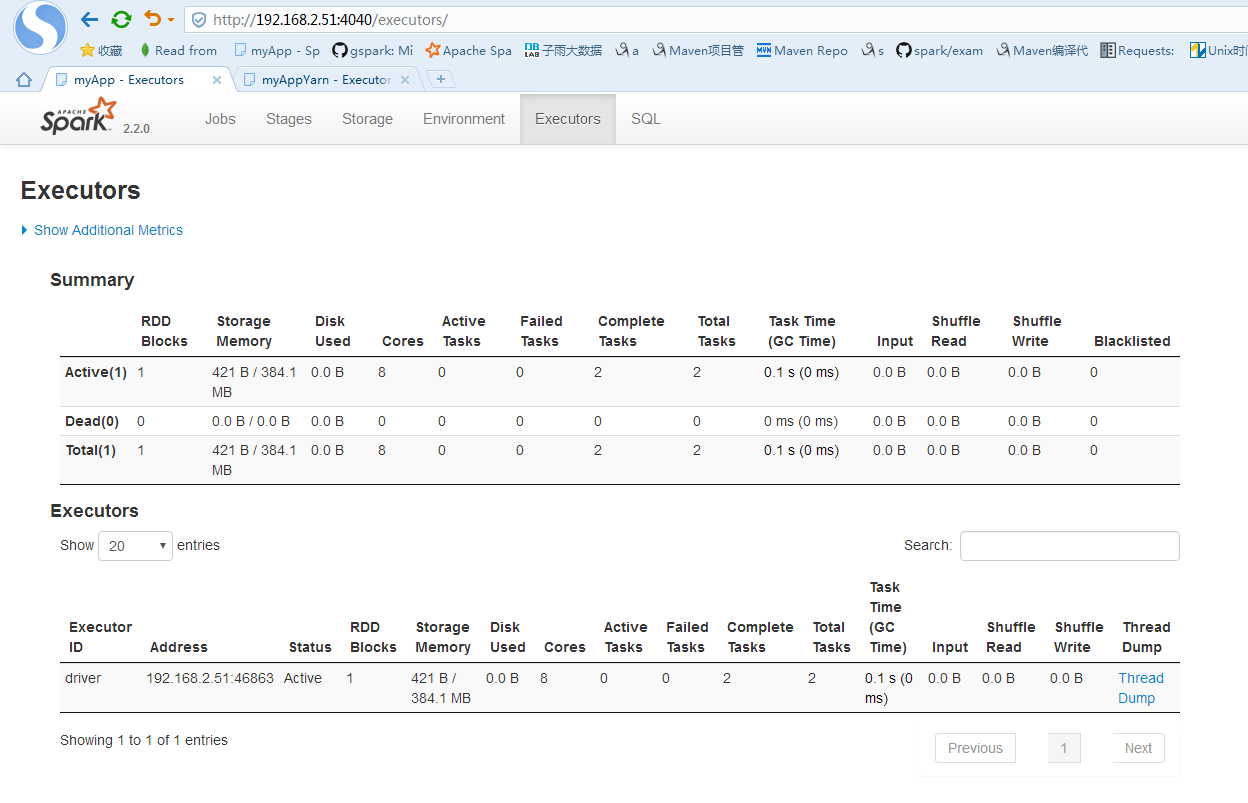
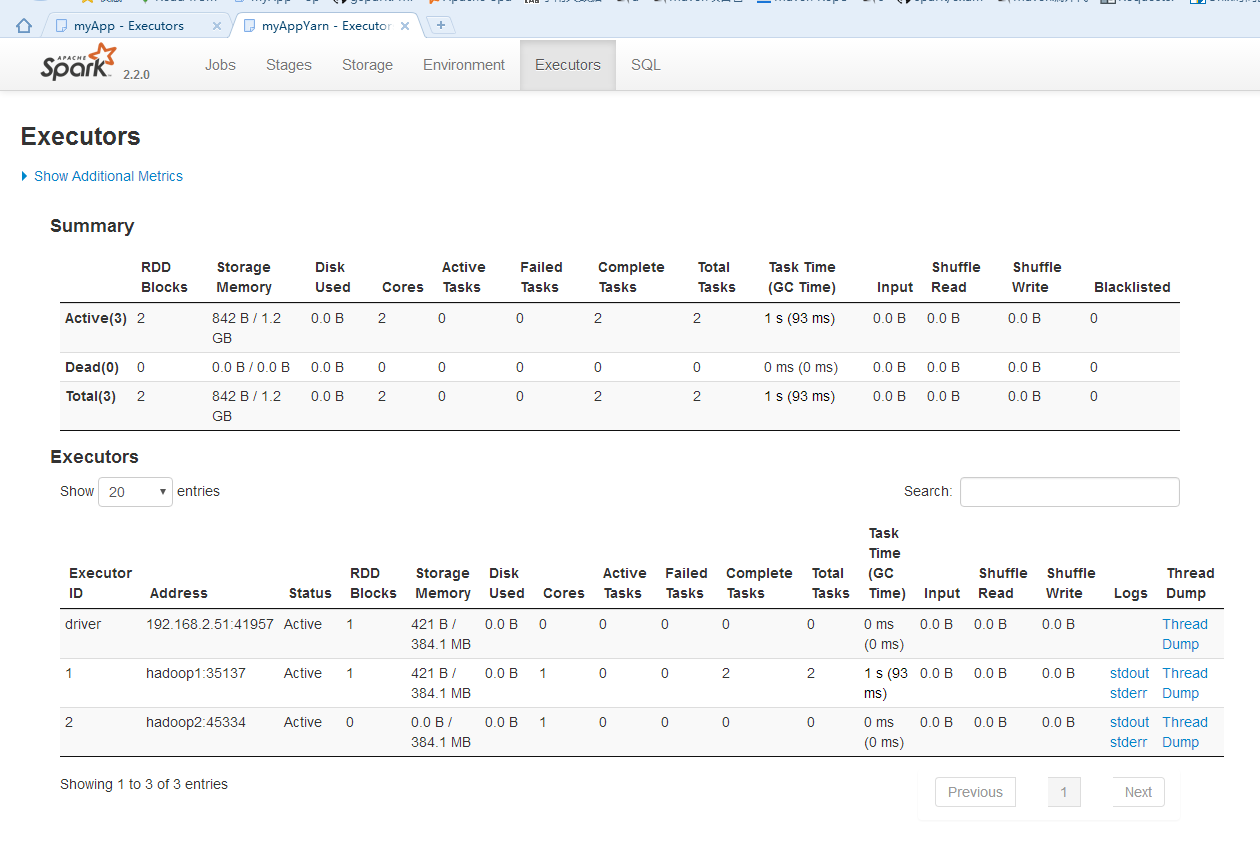
db_rows = my_spark.read.format("com.mongodb.spark.sql.DefaultSource").load().collect() http://192.168.2.51:4041/executors/
ssh://root@192.168.2.51:22/usr/bin/python -u /root/.pycharm_helpers/pydev/pydevd.py --multiproc --qt-support=auto --client '0.0.0.0' --port 47232 --file /home/data/crontab_chk_url/pyspark/pyspark_yarn_test.py
pydev debugger: process 9892 is connecting
Connected to pydev debugger (build 172.4343.24)
Setting default log level to "WARN".
To adjust logging level use sc.setLogLevel(newLevel). For SparkR, use setLogLevel(newLevel).
17/12/03 21:40:24 WARN util.NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicable
17/12/03 21:40:24 WARN util.Utils: Service 'SparkUI' could not bind on port 4040. Attempting port 4041.
17/12/03 21:40:26 WARN yarn.Client: Neither spark.yarn.jars nor spark.yarn.archive is set, falling back to uploading libraries under SPARK_HOME.
pyspark mongodb yarn的更多相关文章
- Nestjs 使用mongodb
Docs: https://docs.nestjs.com/techniques/mongodb yarn add @nestjs/mongoose mongoose 链接 // sec/app.mo ...
- centos7 hdfs yarn spark 搭建笔记
1.搭建3台虚拟机 2.建立账户及信任关系 3.安装java wget jdk-xxx rpm -i jdk-xxx 4.添加环境变量(全部) export JAVA_HOME=/usr/java/j ...
- AAS代码运行-第11章-1
启动PySpark export IPYTHON= # PySpark也可使用IPython shell pyspark --master yarn --num-executors 发生如下错误: / ...
- Spark大数据平台安装教程
一.Spark介绍 Apache Spark 是专为大规模数据处理而设计的快速通用的计算引擎.Spark是开源的类Hadoop MapReduce的通用并行框架,Spark拥有Hadoop MapRe ...
- Spark安装与介绍
1. Scala的安装 注意点:版本匹配的问题, Spark 1.6.2 -- Scala2.10 Spark 2.0.0 -- Scala2.11 https://www.scala-lang.or ...
- 编译安装spark 1.5.x(Building Spark)
原文连接:http://spark.apache.org/docs/1.5.0/building-spark.html · Building with build/mvn · Building a R ...
- Spark python集成
Spark python集成 1.介绍 Spark支持python语言,对于大量的SQL类型的操作,不需要编译,可以直接提交python文件给spark来运行,因此非常简单方便,但是性能要比scala ...
- spark集群安装并集成到hadoop集群
前言 最近在搞hadoop+spark+python,所以就搭建了一个本地的hadoop环境,基础环境搭建地址hadoop2.7.7 分布式集群安装与配置 本篇博客主要说明,如果搭建spark集群并集 ...
- 有关python numpy pandas scipy 等 能在YARN集群上 运行PySpark
有关这个问题,似乎这个在某些时候,用python写好,且spark没有响应的算法支持, 能否能在YARN集群上 运行PySpark方式, 将python分析程序提交上去? Spark Applicat ...
随机推荐
- RocketMQ VS kafka
转自:https://github.com/alibaba/RocketMQ/wiki/rmq_vs_kafka 淘宝内部的交易系统使用了淘宝自主研发的Notify消息中间件,使用MySQL作为消息存 ...
- 【bzoj2989】数列 KD-tree+旋转坐标系
题目描述 给定一个长度为n的正整数数列a[i]. 定义2个位置的graze值为两者位置差与数值差的和,即graze(x,y)=|x-y|+|a[x]-a[y]|. 2种操作(k都是正整数): 1.Mo ...
- 使用Jackson在Java中处理JSON
在工作中实际使用到Java处理JSON的情况,且有很大部分都使用的是开源工具Jackson实现的. 一.入门 Jackson中有个ObjectMapper类很是实用,用于Java对象与JSON的互换. ...
- 能量项链(codevs 1154)
题目描述 Description 在Mars星球上,每个Mars人都随身佩带着一串能量项链.在项链上有N颗能量珠.能量珠是一颗有头标记与尾标记的珠子,这些标记对应着某个正整数.并且,对于相邻的两颗珠子 ...
- 修路 BZOJ 4774
修路 [问题描述] 村子间的小路年久失修,为了保障村子之间的往来,法珞决定带领大家修路.对于边带权的无向图 G = (V, E),请选择一些边,使得1 <= i <= d, i号节点和 n ...
- 【Git】Git 本地的撤销修改和删除操作
一:撤销操作 比如我现在在readme.txt文件里面增加一行 内容为555555555555,我们先通过命令查看如下: 在我未提交之前,我发现添加5555555555555内容有误,所以我得马上恢复 ...
- Scrapy学习-7-数据存储至数据库
使用MySQL数据库存储 安装mysql模块包 pip install mysqlclient 相关库文件 sudo apt-get install libmysqlclient-devel sudo ...
- Iass、Pass、SasS三种云服务区别?
Iass.Pass.SasS三种云服务区别 我们可以把云计算理解成一栋大楼,而这栋楼又可以分为顶楼.中间.低层三大块.那么我们就可以把Iass(基础设施).Pass(平台).Sass(软件)理解成这栋 ...
- Spring基于Setter函数的依赖注入(DI)
以下内容引用自http://wiki.jikexueyuan.com/project/spring/dependency-injection/spring-setter-based-dependenc ...
- android开发教程之使用线程实现视图平滑滚动示例
最近一直想做下拉刷新的效果,琢磨了好久,才走到通过onTouch方法把整个视图往下拉的步骤,接下来就是能拉下来,松开手要能滑回去啊.网上看了好久,没有找到详细的下拉刷新的例子,只有自己慢慢琢磨了.昨天 ...