如何用 pycharm 调试 airflow
airflow 和 pycharm 相关基础知识请看其他博客
我们在使用 airflow的 dag时。 每次写完不知道对不对的,总不能到页面环境中跑一下,等到报错再调试吧。这是很让人恼火的事情
这里我想分享 如何用 pycharm 对 airflow 进行调试
airflow的运行环境,依赖于 airflow.cfg和 airflow_home,
pycharm 的项目目录应该和 airflow_home 相同目录。
1. airflow的配置
详细配置看请看其他博客,这里只是表名我的 airflow_home = /data/airflow
[core]
dags_folder = /data/airflow/dags
# The folder where airflow should store its log files
# This path must be absolute
base_log_folder = /data/airflow/logs
plugins_folder = /data/airflow/plugins
sql_alchemy_conn = mysql://airflow:airflow@IP:3306/airflowtest
broker_url = sqla+mysql://airflow:airflow@IP:3306/airflowtest
2. 启动webserver 模式下airflow
airflow webserver -D
airflow scheduler -D
airflow workder -D
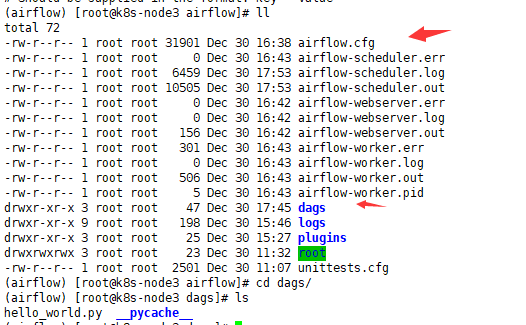
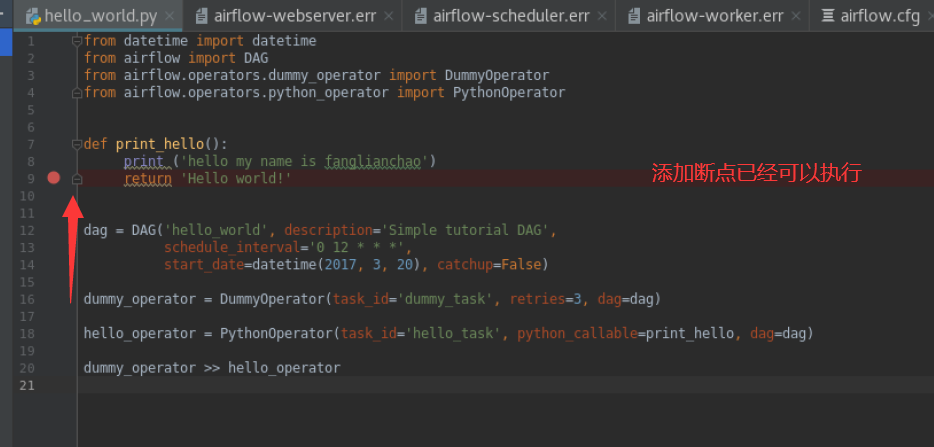
3. 在/data/airflow/dags 下新建范例 dag
vim hello_world.py
from datetime import datetime
from airflow import DAG
from airflow.operators.dummy_operator import DummyOperator
from airflow.operators.python_operator import PythonOperator def print_hello():
print ('hello my name is fanglianchao')
return 'Hello world!' dag = DAG('hello_world', description='Simple tutorial DAG',
schedule_interval='0 12 * * *',
start_date=datetime(2017, 3, 20), catchup=False) dummy_operator = DummyOperator(task_id='dummy_task', retries=3, dag=dag) hello_operator = PythonOperator(task_id='hello_task', python_callable=print_hello, dag=dag) dummy_operator >> hello_operator
~
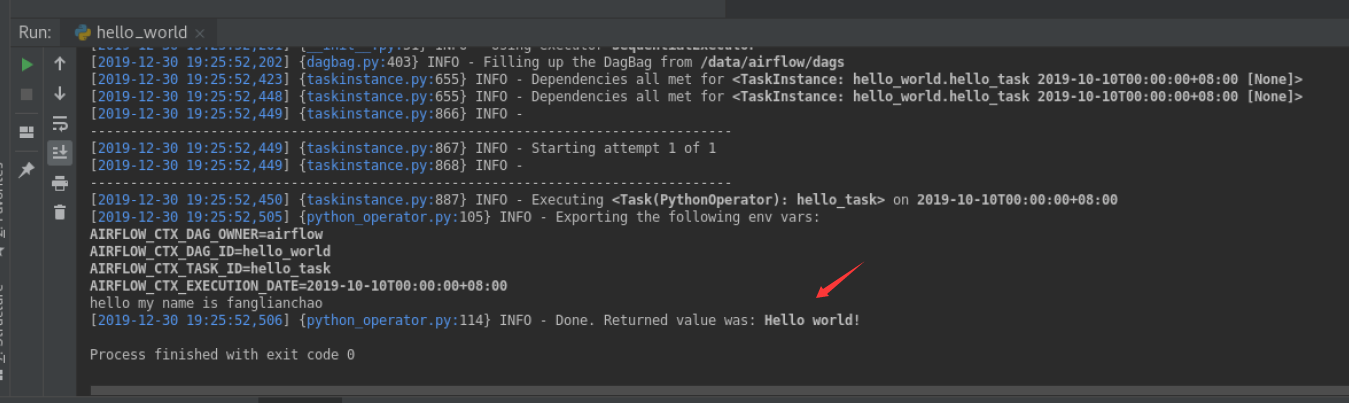
4.执行测试:
如果以下测试成功,就代表安装成功了, 可以到 web 里面 触发执行看看
airflow test hello_world hello_task 2019-10-10
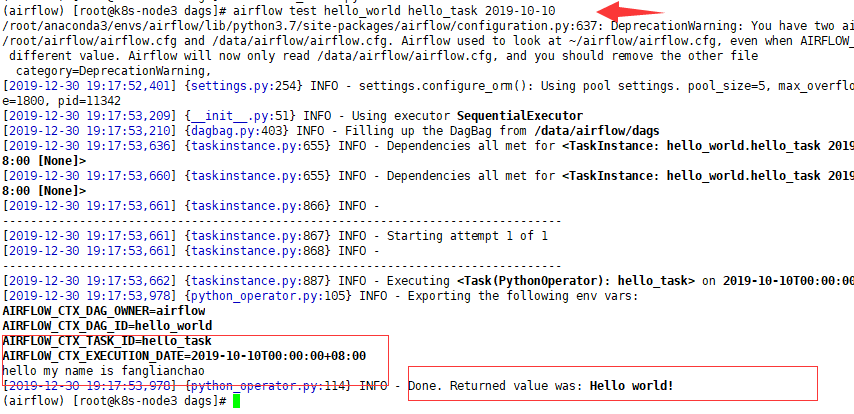

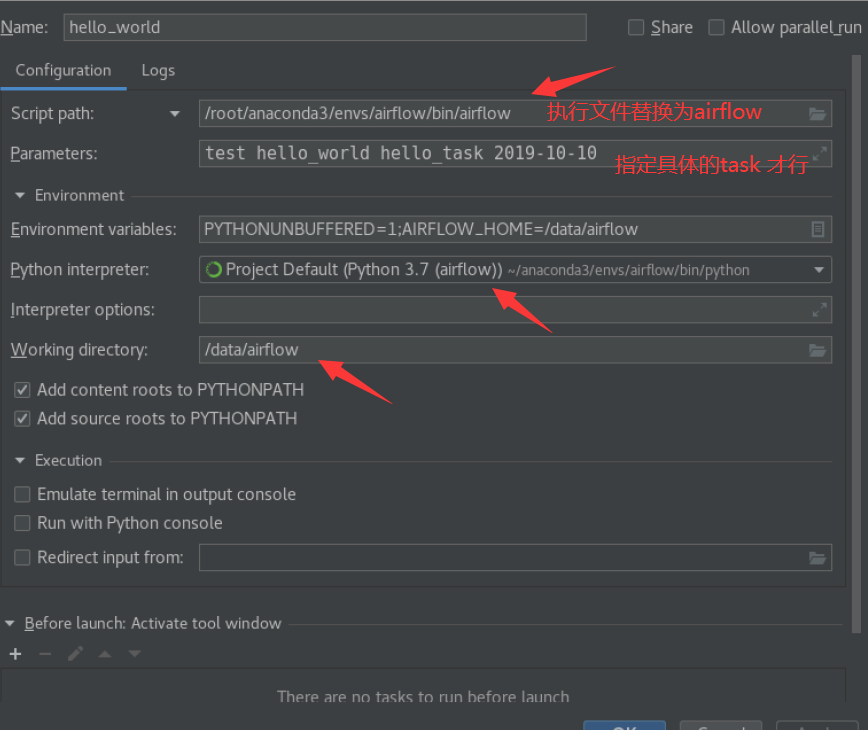
5. pycharm 项目配置
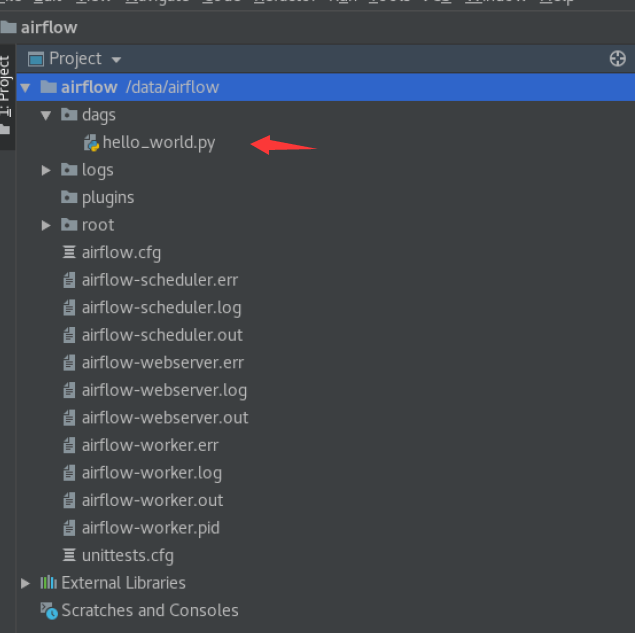
执行这个dag
编辑这个dag 配置文件
如何用 pycharm 调试 airflow的更多相关文章
- 如何用 PyCharm 调试 scrapy 项目
原理: 首先 scrapy 命令其实就是一个python脚本,你可以使用 which scrapy 查看该脚本的内容: from scrapy.cmdline import execute sys.a ...
- 如何用VS调试不属于解决方案的EXE和DLL程序
如果你手里有一个现成的EXE, 以及EXE相关联PDB文件, 还有相关联的CPP文件和H文件. 你如何用VS调试? (当然你可以选择WinDbg.不过这里就讨论VS) 你或许想问我干嘛不从一开始就用V ...
- 使用pycharm调试django项目
要使用pycharm调试django 打断点调试后台代码,首先要进行一下配置: 1.debug 配置 打开debug界面 2.选择python点+加号,然后选择python 3.名字debug,这个看 ...
- 最全Pycharm教程(11)——Pycharm调试器之断点篇
最全Pycharm教程(1)--定制外观 最全Pycharm教程(2)--代码风格 最全Pycharm教程(3)--代码的调试.执行 最全Pycharm教程(4)--有关Python解释器的相关配置 ...
- pycharm调试
pycharm调试 flask app调试: 1.打开edit configurations面板 run===>edit configurations(图一或图二处都可以) 2.配置项目信息 点 ...
- pycharm调试scrapy
pycharm调试scrapy 创建一个run.py文件作为调试入口 run.py中,name是要调试的爬虫的名字(注意,是爬虫类中的name,而不是爬虫类所在文件的名字) 拼接爬虫运行的命令,然后用 ...
- python 基础 1.3 使用pycharm给python传递参数及pycharm调试模式
一.通过pycharm 给python传递函数 1. 在pycharm终端中写入要获取的参数,进行获取 1>启动pycharm 中Terminal(终端) 窗口 点击pycharm左下角的图标, ...
- 9.scrapy pycharm调试小技巧,请求一次,下次直接调试,不必每次都启动整个爬虫,重新请求一整遍
pycharm调试技巧:调试时,请求一次,下次直接调试,不必每次都启动整个爬虫,重新请求一整遍 [用法]cmd命令运行:scrapy shell 网址 第一步,cmd进行一次请求: scrapy sh ...
- 【转载】Pycharm调试高效,还是pdb调试高效? (在服务端)
https://segmentfault.com/q/1010000005067119 Pycharm调试高效,还是pdb调试高效? (在服务端) python 3.9k 次浏览 问题对人有帮助, ...
随机推荐
- jmeter+influxdb+granfana+collectd监控cpu+mem+TPS
1.安装grafana #####gafana过期安装包安装报错 Error unpacking rpm package grafana-5.1.4-1.x86_64error: unpacking ...
- 错误记录(一):VSCode
VS Code莫名其妙突然变卡. 后来重新安装,下载以前版本,设置防止循环,都不太管用. 最后想添加VS Code目录到windows扫描白名单,但因为系统之前是英文不太好看懂,所以又调回了中文. 这 ...
- js中map和filter方法,以及search方法
链接:https://blog.51cto.com/11871779/2126561 search方法: 介绍: search() 方法用于检索字符串中指定的子字符串,或检索与正则表达式相匹配的子字符 ...
- TCP和UDP的一些注意事项
TCP的一些注意事项 1. tcp服务器一般情况下都需要绑定,否则客户端找不到这个服务器,更无法链接到服务器 2. tcp客户端一般不绑定,因为是主动链接服务器,所以只要确定好服务器的ip.port等 ...
- 如何通过Docker搭建一个swoft开发环境
本篇文章给大家分享的内容是关于如何通过Docker搭建一个swoft开发环境 ,内容很详细,有需要的朋友可以参考一下,希望可以帮助到你们. Swoft首个基于 Swoole 原生协程的新时代 PHP ...
- java8下 枚举 通用方法
在项目中经常用到枚举作为数据字典值和描述的相互转化. 用法如下: public enum CommunicationParamsCom { COM_1(1, "COM1"), CO ...
- 03-Spring的IOC示例程序(通过类型获取对象)
根据bean类型从IOC容器中获取bean的实例 ①test测试类 @Test public void Test02() { //获取spring容器对象 ApplicationContext app ...
- 对DensePose: Dense Human Pose Estimation In The Wild的理解
研究方法 通过完全卷积学习从图像像素到密集模板网格的映射.将此任务作为一个回归问题,并利用手动注释的面部标注来训练我们的网络.使用这样的标注,在三维对象模板和输入图像之间,建立密集的对应领域,然后作为 ...
- svn怎么修改用户名和密码
链接:https://blog.csdn.net/qq_36826506/article/details/80915431
- Jekyll+Github个人博客构建之路
请参考: http://robotkang.cc/2017/03/HowToCreateBlog/