如何在本地调试你的 Spark Job
生产环境的 Spark Job 都是跑在集群上的,毕竟 Spark 为大数据而生,海量的数据处理必须依靠集群。但是在开发Spark的的时候,不可避免我们要在本地进行一些开发和测试工作,所以如何在本地用好Spark也十分重要,下面给大家分享一些经验。
首先你需要在本机上安装好了Java,Scala和Spark,并配置好了环境变量。详情请参考官方文档或其他教程。
spark-shell
本地运行Spark最直接的方式就是在命令行里面运行spark-shell,成功后你将看到如下信息:
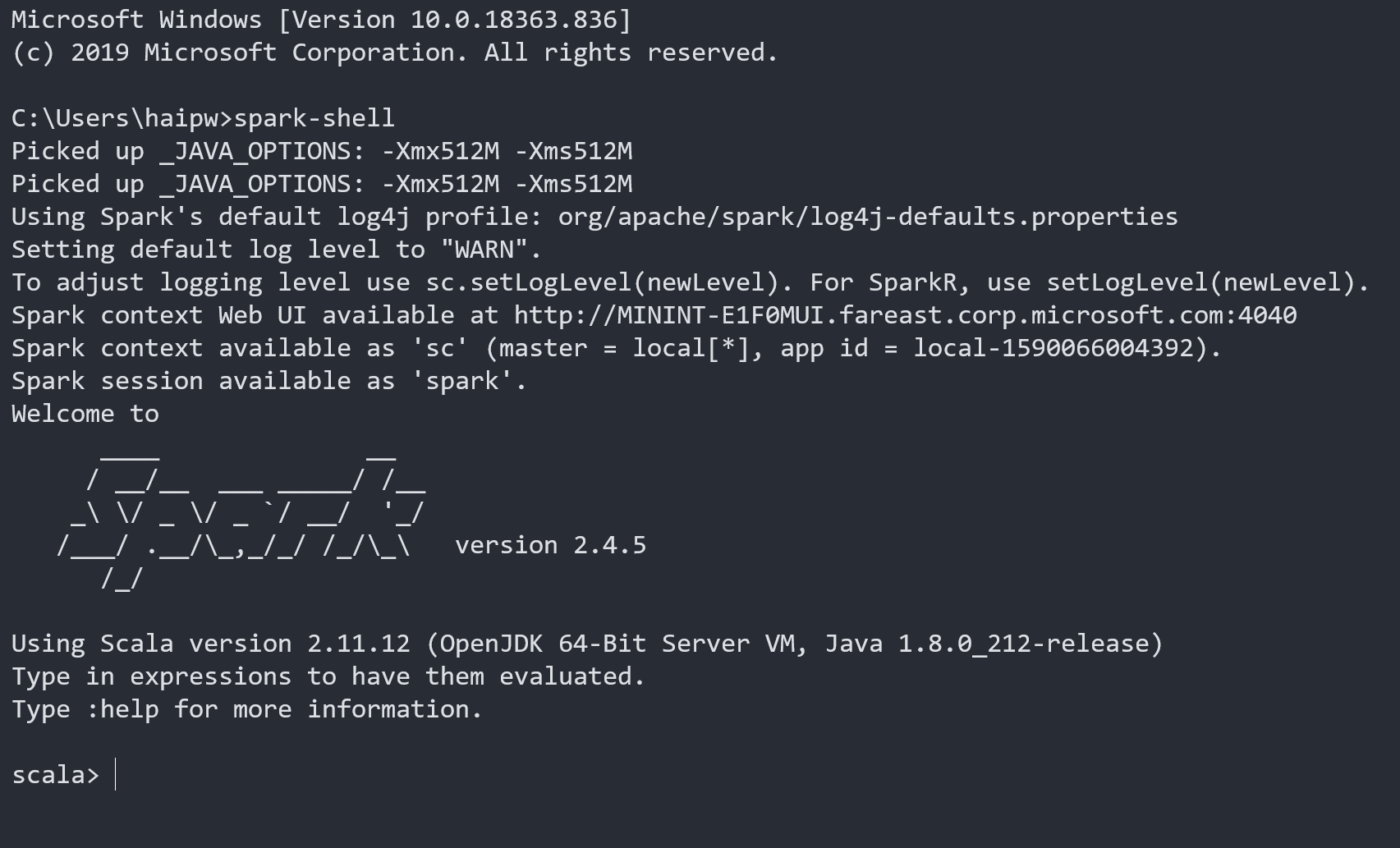
首先可以仔细阅读一下命令行的提示信息,
Picked up _JAVA_OPTIONS: -Xmx512M -Xms512M // _JAVA_OPTIONS是我在系统环境变量里面设置的值
Using Spark's default log4j profile: org/apache/spark/log4j-defaults.properties // 告诉你log4j使用配置
Setting default log level to "WARN". // log级别
To adjust logging level use sc.setLogLevel(newLevel). For SparkR, use setLogLevel(newLevel). // 如何调整log级别
Spark context Web UI available at http://localhost:4040 // 本地访问Web UI的地方,很重要
Spark context available as 'sc' (master = local[*], app id = local-1590066004392). // master配置和 sc变量
Spark session available as 'spark'. // spark变量
可以发现必要的信息都已经给我们提示好了,不过不知道哪里养成的坏习惯,程序的提示信息我通常都是跳过不看的,其实这样很不好,希望你没有这种坏习惯。
我们再仔细看一下 master = local[*] 这个配置,它告诉Spark在运行中可以使用多少个核,详细如下:
- local: 所有计算都运行在一个线程当中,没有任何并行计算。
- local[n]: 指定使用n个线程来运行计算。
- local[*]: 这种模式直接帮你按照cpu最多cores来设置线程数了。
你可以在这个命令行像使用python解释器一样写scala代码,可以及时看到程序的运行结果,这种模式通常在最初学习spark的时候使用,或者你想要验证一些临时、简短的spark代码,可以使用这种方式。
Spark Web UI
在你使用Spark 期间,可以通过 http://localhost:4040 来访问Web UI.
这是Spark提供的非常强大的一个工具,它可以看到运行过程中的丰富细节,网上有很多资料可以参考,这里不详细介绍。Spark Web UI
值得一提的是,Web UI 只在你SparkSession活跃期间可以访问,当你的job完成时这个地址就关闭了。当你打开一个spark-shell的时候,你的spark session会一直活跃,所以可以随时访问Web UI;当你关闭命令行的时候就不可以了。 当然你也可以通过修改配置保存这些信息,可以让你在程序退出后依然有办法从Web UI查看,但操作起来有点复杂,并且一般用的频率小,就不推荐了。
Jupyter Notebook
比spark-shell更好的一种方式是使用Notebook,Notebook。 首先你可以在本机安装Anaconda,安装完之后自带Jupyter Notebook,但是它默认只支持python 的kernel,也就是说只能写python,为了能写spark job(实际上是Scala脚本)需要再安装一些插件,插件其实很多,我找到了一种非常简便的方法,推荐给大家:
按照上面的教程安装完之后,你打开Notebook,再new 下面可以看到一个新的kernel选项
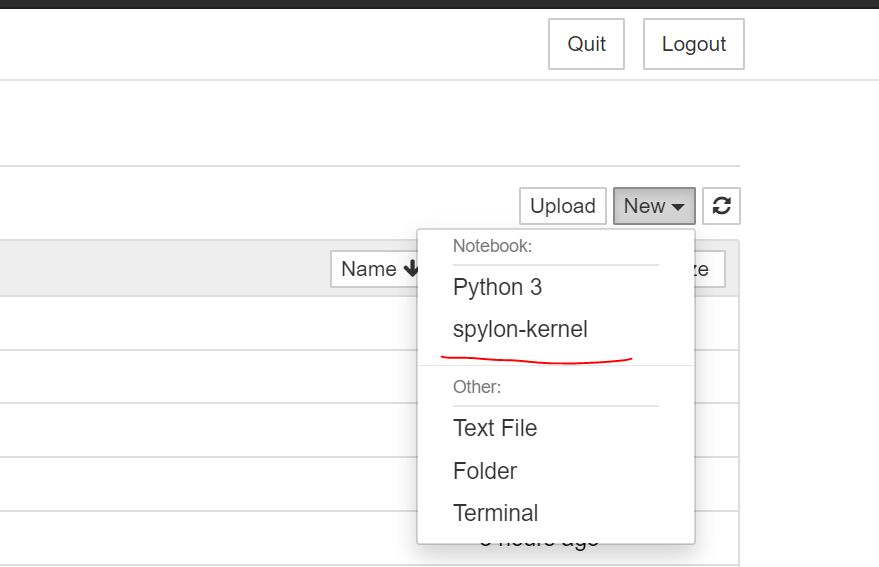
新建之后就可以写spark job了。
显然Notebook比命令行的方式好的多,不但可以执行代码,还可以修改、保存、分享,本地调试一些小的程序时候或者演示、验证一些新功能的时候首选这种方式。
第一次启动scala解释器的时候时间会比较久,请耐心等待。查看你的notebook命令行输出,是否忘了配置 SPARK_HOME 环境变量?
成功运行之后你将看到如下信息:
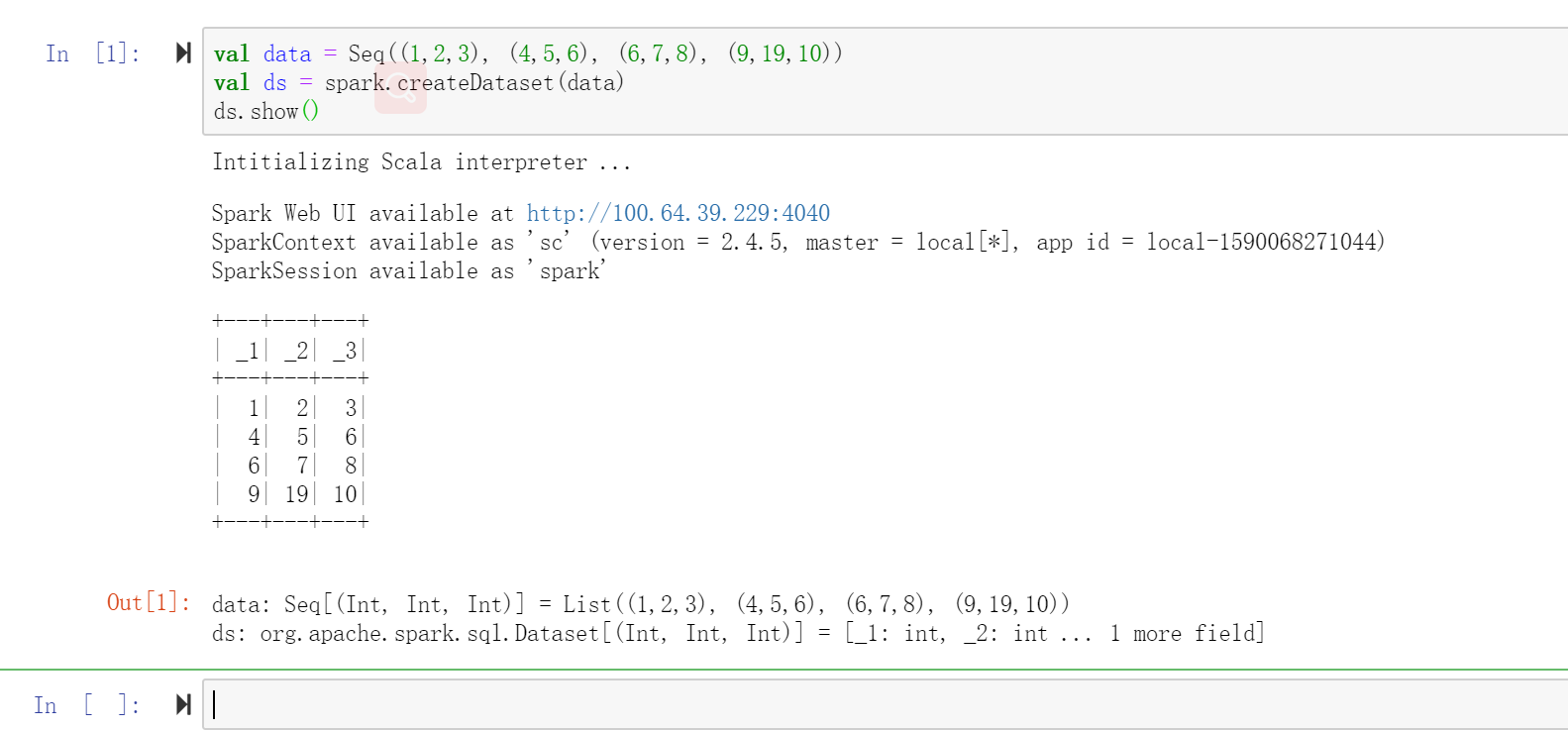
同样,在你的Notebook运行期间你也可以到 http://localhost:4040 页面查看Spark Web UI.
IDEA
当然,你也可以在IDEA 中写代码并测试,这个更接近生产环境的工作,一般最后都要使用它写好完整的代码,编译并打包为jar. IDEA的介绍请参考 IDEA中运行Java/Scala/Spark程序.
写代码的过程不再做介绍,在IDEA里运行的时候同样需要指定master为本机,你有两种方式可以使用:一是在程序的代码里直接设置,另外一种是在VM参数中添加。建议选择后者。
Run -> Edit Configurations -> VM Options: -Dspark.master=local[6]
另外你还可以增加一个命令行参数,例如: --local, 这样你可以在脚本中方便地输出一些只有你在本地想看的信息。
// 检查命令行参数,赋值给local变量,方便测试一些本地信息
if(arg.startsWith("--local"))
{
local = true
}
最后,当你在IDEA里面运行Spark Job的时候,运行结束之后Web UI的端口会自动关闭,所以如果你想要在程序运行完的一段时间内还可以看到这些信息(通常都是需要的),你需要在程序结束的位置加上如下语句:
if(local)
{
System.in.read
spark.stop()
}
如果你喜欢我的文章,欢迎到我的个人网站关注我,非常感谢!
如何在本地调试你的 Spark Job的更多相关文章
- windows下Idea结合maven开发spark和本地调试
本人的开发环境: 1.虚拟机centos 6.5 2.jdk 1.8 3.spark2.2.0 4.scala 2.11.8 5.maven 3.5.2 在开发和搭环境时必须注意版本兼容的问题 ...
- spark 2.x在windows环境使用idea本地调试启动了kerberos认证的hive
1 概述 开发调试spark程序时,因为要访问开启kerberos认证的hive/hbase/hdfs等组件,每次调试都需要打jar包,上传到服务器执行特别影响工作效率,所以调研了下如何在window ...
- 利用Pycharm本地调试spark-streaming(包含kafka和zookeeper等操作)
环境准备就不说了! 第一步:打开Pycharm,在File->Setting->Project Structure中点击Add Content Root 添加本地python调用java和 ...
- mapreduce 本地调试需要注意的问题
1.写好的程序直接在hadoop集群里面执行 2.如果需要在本地调试,需要注释掉mapred-site.xml <configuration> <!-- <property&g ...
- 开源分布式实时计算引擎 Iveely Computing 之 本地调试Topology(4)
当我们写完一个比较复杂的Topology之后,倘若直接提交到服务器上运行,难免会有很多问题,如何进行本地的调试Topology,是我们非常关心的问题.我们依然以WordCount作为代码示例. 首先, ...
- OpenCart本地调试环境搭建
OpenCart简介: 免费开源网络版电子商务系统,是建立在线商务网站首选之一.有众多用户和开发基础,结合其丰富特性与模板插件,可最大化定制在线商店.(也就是用来方便开网店的) 本地调试准备: Fir ...
- 在本地调试微信项目(C#)
之前一人负责微信的项目,那时2014年LZ还没毕业..啥都不懂,为此特别感谢@SZW,没有你的框架,我可能都无从下手 当时做项目最麻烦的就是调试,因为很多页面都要使用 网页授权获取用户信息 在电脑上打 ...
- Oracle在本地调试成功读取数据,但是把代码放到服务器读不出数据的解决方法。
用MVC EF框架开发项目,数据库用的是Oracle,本地调试的时候一切正常,但是把代码编译之后放到服务器就会读不出数据. 原因:本地调试环境与服务器环境不一致. 办法:在服务器上装ODT.NET组件 ...
- C#微信公众号——本地调试
测试微信,因为要与微信服务器进行交互,所以必须要是外网地址,实现本地调试首先需要解决的问题就是外网问题,这个我前面的文章有介绍,这里就不再详细介绍了,网址http://www.cnblogs.com/ ...
随机推荐
- 监控MySQL服务及httpd服务
一:监控MySQL服务 [root@server ~]# vim /usr/local/zabbix/etc/zabbix_agentd.conf PidFile=/tmp/zabbix_agentd ...
- JNI与NDK简析(一)
1 JNI 简介 在Android Framework中,需要提供一种媒介或 桥梁,将Java层(上层)与C/C++层(下层)有机的联系起来,使得他们互相协调完成某些任务.而充当这种媒介的就是Java ...
- SpringCloud系列之集成Dubbo应用篇
目录 前言 项目版本 项目说明 集成Dubbo 2.6.x 新项目模块 老项目模块 集成Dubbo 2.7.x 新项目模块 老项目模块 参考资料 系列文章 前言 SpringCloud系列开篇文章就说 ...
- 【JAVA基础】10 Object类
1. Object类概述 是类层次结构的根类 每个类都使用 Object 作为超类 所有类都直接或者间接的继承自该类 所有对象(包括数组)都实现这个类的方法. 2. Object的构造方法 publi ...
- 题解 bzoj 4398福慧双修(二进制分组)
二进制分组,算个小技巧 bzoj 4398福慧双修 给一张图,同一条边不同方向权值不同,一条边只能走一次,求从1号点出发再回到1号点的最短路 一开始没注意一条边只能走一次这个限制,打了个从一号点相邻节 ...
- 一只简单的网络爬虫(基于linux C/C++)————支持动态模块加载
插件在软件设计中有很大的好处,可以方便地扩展各种功能,使用插件技术能够在分析.设计.开发.项目计划.协作生产和产品扩展等很多方面带来好处: (1)结构清晰.易于理解.由于借鉴了硬件总线的结构,而且各个 ...
- python 中open文件路径的选择
一.问题描述 python 中使用open打开某个文件写入时,往往会发现需要写入的文件不在同级目录下.这样就需要根据文件的路径来找到并打开. 但往往有时绝对路径和相对路径,写入不正确就会打开失败. 二 ...
- libevent(十)bufferevent 2
接上文libevent(九)bufferevent 上文主要讲了bufferevent如何监听读事件,那么bufferevent如何监听写事件呢? 对于一个fd,只要它的写缓冲区没有满,就会触发写事件 ...
- Go中的数组切片的使用总结
代码示例 package main import "fmt" func main(){ fmt.Println("Hello, world") // 定义数组的 ...
- 2019国防科大校赛 B Escape LouvreⅡ
https://ac.nowcoder.com/acm/contest/878/B 这个题目是一个网络流,但是建图却没有那么好建,首先我们都会把每一个人与源点相连,每一个洞口和汇点相连. 然后人和洞口 ...