Hbase的基本架构以及对应的读写流程
一、HBase简介
1,定义:
HBase 是一种分布式、可扩展、支持海量数据存储的 NoSQL 数据库。
2,HBase的架构图:

架构角色:
1)Master
Master是所有Region Server的管理者,其实现为HRegionServer,主要作用有:
a>对于表的DDL操作:create,delete,alter b>对于RegionServer的操作:分配regions到每个RegionServer,监控每个RegionServer的状态,负载均衡和故障转移。
2)Zookeeper:
HBase通过Zookeeper来做Master的高可用、RegionServer的监控、元数据的入口以及集群配置的维护等工作。
3)WAL:
由于数据要经MemStore排序后才能刷写到HFile,但把数据保存在内存中会有很高的概率导致数据丢失,为了解决这个问题,数据会先写入Write-Ahead logfile的文件中,然后再写入到Memstore中。所以在系统出现故障的时候,数据可以通过这个日志文件重建。
4)MemStore:
写缓存,由于HFile中的数据要求是有序的,所以数据是先存储在MemStore中,排好序后,等到达刷写时机才会刷写到HFile,每次刷写都会形成一个新的HFile。
5)StoreFile:
保存实际数据的物理文件,StoreFile以HFile的形式存储在HDFS上。每个Store会有一个或多个StoreFile(HFile),数据在StoreFile上是有序的。
3,数据模型:
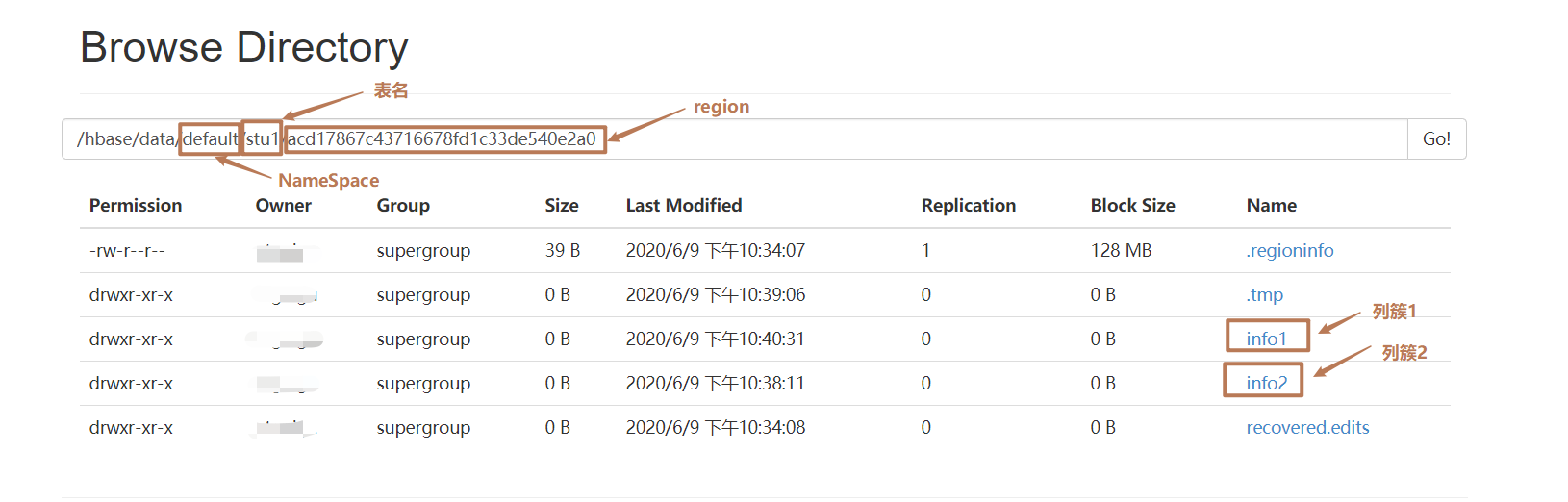
1)Name Space
命名空间,类似于关系型数据库的DataBase概念,每个命名空间下有多个表。HBase有两个自带的命名空间,分别是hbase和default,hbase中存放的是HBase的内置表,default表示用户默认使用的命名空间。
2)Region
类似于关系型数据库的表概念。不同的是,HBase定义表时只需要生命列簇即可,不需要声明具体的列。这意味着,往HBase写入数据时,字段可以动态、按需指定。
3)Row
HBase表中的每行数据都由一个RowKey和多个Column(列)组成,数据是按照RowKey的字典顺序存储的,并且查询时智能根据RowKey进行检索,所以RowKey的书籍十分重要。
4)Cloumn
HBase中的每个列都由Cloumn Family(列簇)和Cloumn Qualifier(列限定符)进行限定,例如info:name,info:age。建表时,只需指明列簇,而列限定符无需预先定义。
5)Time Stamp
用于标识数据的不同版本(version),每条数据写入时,如果不指定时间戳,系统会自动为其加上该字段,其值为写入HBase的时间。
6)Cell
由{rowkey, column Family:column Qualifier, time Stamp} 唯一确定的单元。cell 中的数据是没有类型的,全部是字节码形式存贮。
二、HBase写数据流程
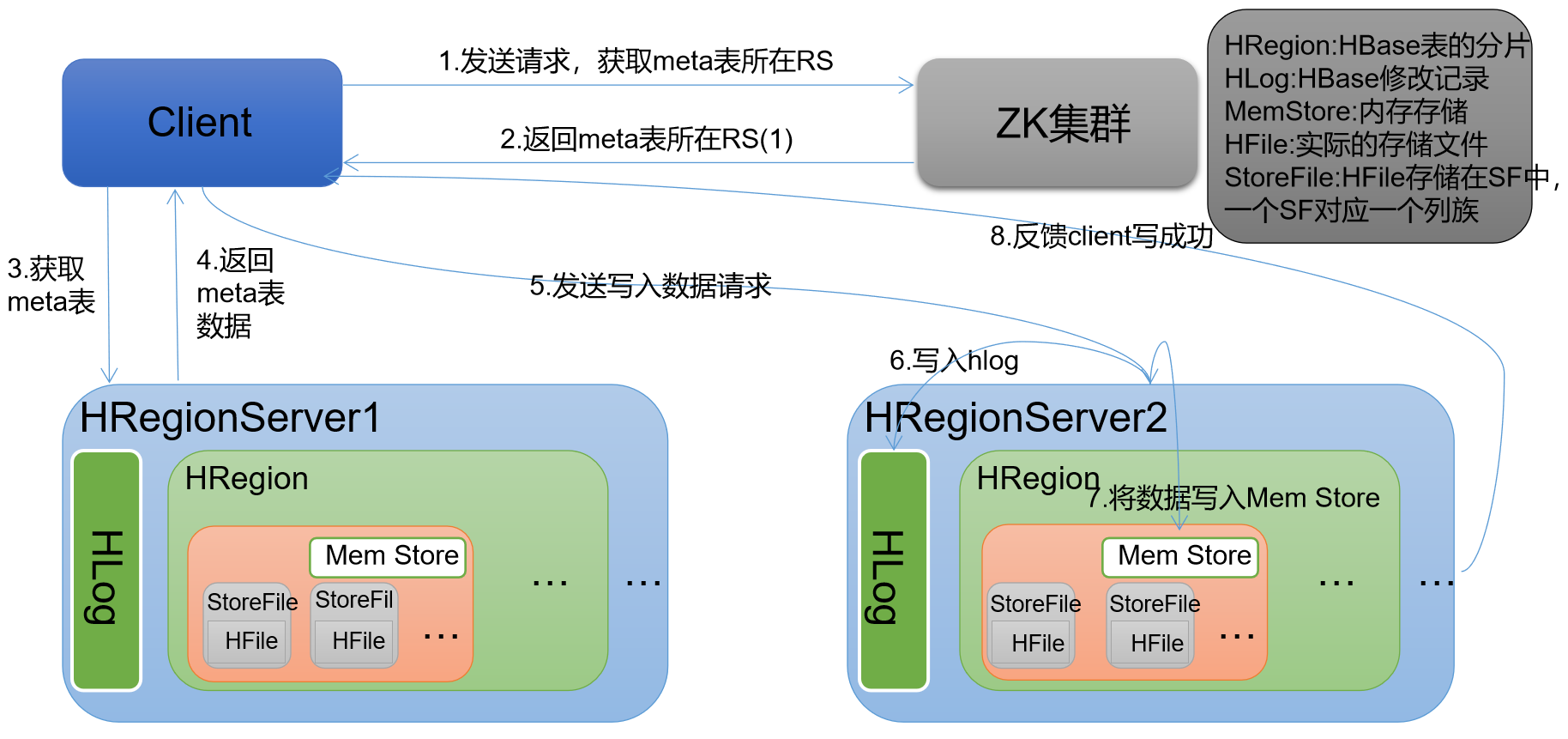
)Client 先访问 zookeeper,获取 hbase:meta 表位于哪个 Region Server。 #zk get /hbase/meta-region-server
)访问对应的 Region Server,获取 hbase:meta 表,根据读请求的 namespace:table/rowkey,查询出目标数据位于哪个 Region Server 中的哪个 Region 中。
并将该 table 的 region 信息以及 meta 表的位置信息缓存在客户端的 meta cache,方便下次访问。 #hbase scan 'hbase:meta' 查询到具体哪张表由哪个Region Server维护
)与目标 Region Server 进行通讯;
)将数据顺序写入(追加)到 WAL;
)将数据写入对应的 MemStore,数据会在 MemStore 进行排序;
)向客户端发送 ack;
)等达到 MemStore 的刷写时机后,将数据刷写到 HFile。
三、HBase读数据流程
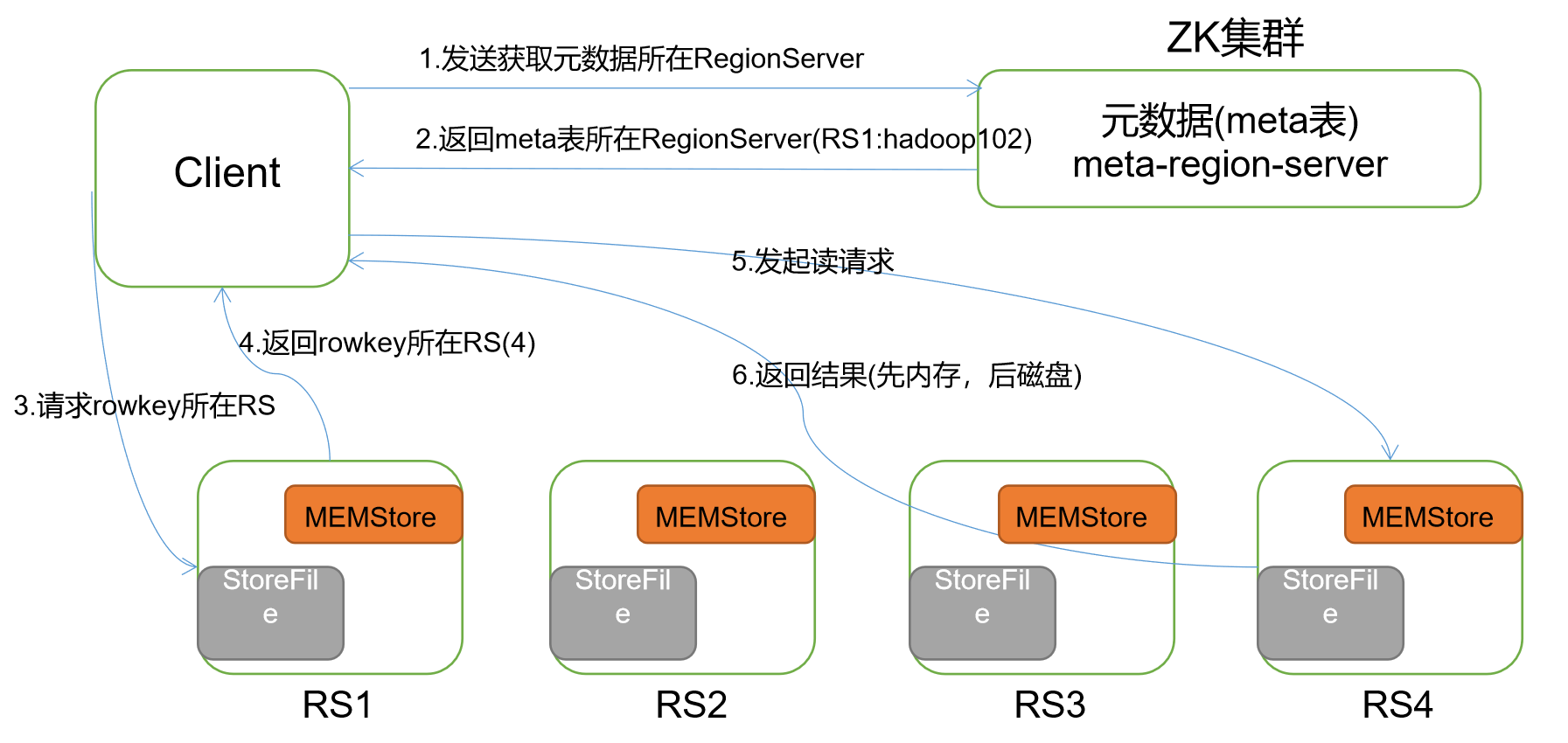
)Client 先访问 zookeeper,获取 hbase:meta 表位于哪个 Region Server。
)访问对应的 Region Server,获取 hbase:meta 表,根据读请求的 namespace:table/rowkey,查询出目标数据位于哪个 Region Server 中的哪个 Region 中。并将该 table 的 region 信息以及 meta 表的位置信息缓存在客户端的 meta cache,方便下次访问。
)与目标 Region Server 进行通讯;
)分别在 Block Cache(读缓存),MemStore 和 Store File(HFile)中查询目标数据,并将查到的所有数据进行合并。此处所有数据是指同一条数据的不同版本(time stamp)或者不同的类型(Put/Delete)。
)将从文件中查询到的数据块(Block,HFile 数据存储单元,默认大小为 64KB)缓存到Block Cache。
)将合并后的最终结果返回给客户端。
Hbase的基本架构以及对应的读写流程的更多相关文章
- HBase的基本架构及其原理介绍
1.概述:最近,有一些工程师问我有关HBase的基本架构的问题,其实这个问题仅仅说架构是非常简单,但是需要理解.在这里,我觉得可以用HDFS的架构作为借鉴.(其实像Hadoop生态系统中的大部分组建的 ...
- HBase 数据读写流程
HBase 数据读写流程 2016-10-18 杜亦舒 读数据 HBase的表是按行拆分为一个个 region 块儿,这些块儿被放置在各个 regionserver 中 假设现在想在用户表中获取 ro ...
- Mycat分布式数据库架构解决方案--Mycat实现读写分离
echo编辑整理,欢迎转载,转载请声明文章来源.欢迎添加echo微信(微信号:t2421499075)交流学习. 百战不败,依不自称常胜,百败不颓,依能奋力前行.--这才是真正的堪称强大!!! 安装完 ...
- Hbase的读写流程
HBase读写流程 1.HBase读数据流程 HRegionServer保存着meta表以及表数据,要访问表数据,首先Client先去访问zookeeper,从zookeeper里面获取meta表所在 ...
- HBase二级索引、读写流程
HBase二级索引.读写流程 一.HBse二级索引方案 1.1 基于Coprocessor方案 1.2 Phoenix二级索引特点 1.3 Phoenix 二级索引方案 二.HBase读写流程 2.1 ...
- zookeeper的读写流程
zookeeper的读写流程 基本架构 节点数要求是奇数. 常用的接口是 get/set/create/getChildren. 读写流程 写流程 客户端连接到集群中某一个节点 客户端发送写请求 服务 ...
- hbase之createTable完整的netty实现执行流程
hbase的客户端代码并不想hive一样用java编写,shell调用,而是使用ruby编写. 在admin.rb文件中方法create,其中接受两个参数,其中第二个参数类型为变长参数. 而在crea ...
- Hadoop---HDFS读写流程
Hadoop---HDFS HDFS 性能详解 HDFS 天生是为大规模数据存储与计算服务的,而对大规模数据的处理目前还有没比较稳妥的解决方案. HDFS 将将要存储的大文件进行分割,分割到既定的存储 ...
- HDFS文件读写流程
一.HDFS HDFS全称是Hadoop Distributed System.HDFS是为以流的方式存取大文件而设计的.适用于几百MB,GB以及TB,并写一次读多次的场合.而对于低延时数据访问.大量 ...
随机推荐
- HBase Filter 过滤器之 ValueFilter 详解
前言:本文详细介绍了 HBase ValueFilter 过滤器 Java&Shell API 的使用,并贴出了相关示例代码以供参考.ValueFilter 基于列值进行过滤,在工作中涉及到需 ...
- git:error: Your local changes to the following files would be overwritten by merge:
最近用git在服务器.github.本地更新代码的时候,因为频繁修改偶尔出现这个错误 覆盖本地的代码: git stash git pull git stash pop 保留对服务器上的修改: git ...
- 11.2Go gin
11.1 Go gin 框架一直是敏捷开发中的利器,能让开发者很快的上手并做出应用. 成长总不会一蹴而就,从写出程序获取成就感,再到精通框架,快速构造应用. Gin是一个golang的微框架,封装比较 ...
- 9.1 Go 反射
9.1 Go 反射 反射:可以在运行时,动态获取变量的信息,比如变量的类型,类别 1.对于结构体变量,还可以获取到结构体的字段,方法 2.实现这个功能的是 reflect包 reflect.TypeO ...
- Django之forms.Form
django中的form组件提供了普通表单提交及验证数据的主要功能: 1. 生成页面可用的HTML标签 2. 对用户提交的数据进行验证 3. 可保留用户上次提交的数据 django中 ...
- apache slowloris mod_antiloris for Apache httpd 2.2 / 2.4
http://www.apachelounge.com/viewtopic.php?t=4222
- MySQL 8.0用户及安全管理
用户的功能 登录数据库 管理数据库对象 用户的组成 用户名@'白名单' 白名单: % 10.0.0.10 .% 10.0.0.5% 10.0.0.0/255.255.254.0 oldguo.com ...
- 阿里云ECS封25端口导致wordpress无法发送邮件的解决
在有人评论你的文章,wordpress默认会尝试向博主发送邮件,而如果你用的是阿里云ECS,你会发现评论已经成功了,但是由于邮件发送失败会导致用户评论后页面就卡住了,原因就在于阿里云的ECS目前已经全 ...
- C#网络编程入门之UDP
目录: C#网络编程入门系列包括三篇文章: (一)C#网络编程入门之UDP (二)C#网络编程入门之TCP (三)C#网络编程入门之HTTP 一.概述 UDP和TCP是网络通讯常用的两个传输协议,C# ...
- 2.Linux系统之硬盘与分区基础知识
我们是在虚拟机上安装的Linux系统.在安装的过程中,可能会遇到磁盘分区的问题,我们下面简单介绍一下分区的原理. 1.硬盘的基础知识 下面是一块空白的硬盘: 这是一块格式化后的硬盘: 格式化就是,在空 ...