SciTech-Mathmatics-Probability+Statistics: Statistical Inference统计推断- Estimation估计 + Testing Hypotheses假设检验
Stat 345(April 11, 2019)
Chapter 7: Sampling Distributions and Point Estimation ofParameters
Topics:
- General concepts of
estimatingthe parameters of a population or a probability distribution Understandthe CLT(Central Limit Theorem)Explainimportant properties of point estimators,includingbias,variance, and mean square error
Overview
Identifya population of interest — for example, UNM freshmen female students' weight, height or entrance GPA.- Population parameters — unknown quantities of the population that are of interest, say,
population mean µ and population variance σ2 etc. - Random sample —- Select a random or representative sample from the population.
— A sample consists random variables Y1, · · · , Yn, that follows aspecified distribution, say N(µ, σ2) - Statistic: a function of radom variables Y1, . . . , Yn, which does not depend on any unknown parameters
- Observed sample: y1, y2, · · · , yn are observed sample values after data collection
- We cannot see much of the population —- but would like to know what is typical in the population
— The only information we have is that in the sample.
- We cannot see much of the population —- but would like to know what is typical in the population
Goal: want to use the sample information to make inferences about the population and its parameters.
- Statistical inference is concerned with making decisions about apopulation based on the information contained in a random sample from that population.
![]()
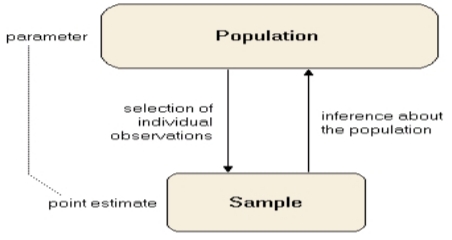
Suppose our goal is to obtain a point estimate of a population parameter,i.e. mean, variance, based a sample x1, . . . , xn.
- Before we collected the data, we consider each observation as arandom variable, i.e. X1, . . . , Xn.
- We assume X1, . . . , Xn are mutually independent random variables.
Point estimator: a point estimator is a function of X1, . . . , Xn.
Point estimate: a point estimate is a single numerical value of the point estimator based on an observed sample.
- Population mean: µ
- Sample mean: ¯ Y=Pni=1 Yi/n
- Estimate of sample mean: the value of ¯ Y computed from data y=Pni=1 yi/n¯
- Population variance: σ2I Sample variance: S2 =1n−1Pni=1(Yi − ¯ Y)2
- Estimate of sample variance: the value of S2 computed from data s2 =1y)2n−1Pni=1(yi − ¯
- Population standard deviation: σ
- I Sample standard deviation (Standard error): S
- Estimate of standard error: s, the value of S computed from data

北京大学工学院 的 统计概率课件PPT
http://www2.coe.pku.edu.cn/tpic/file/20150430/201504300248004545.pdf
![]()
![]()
![]()
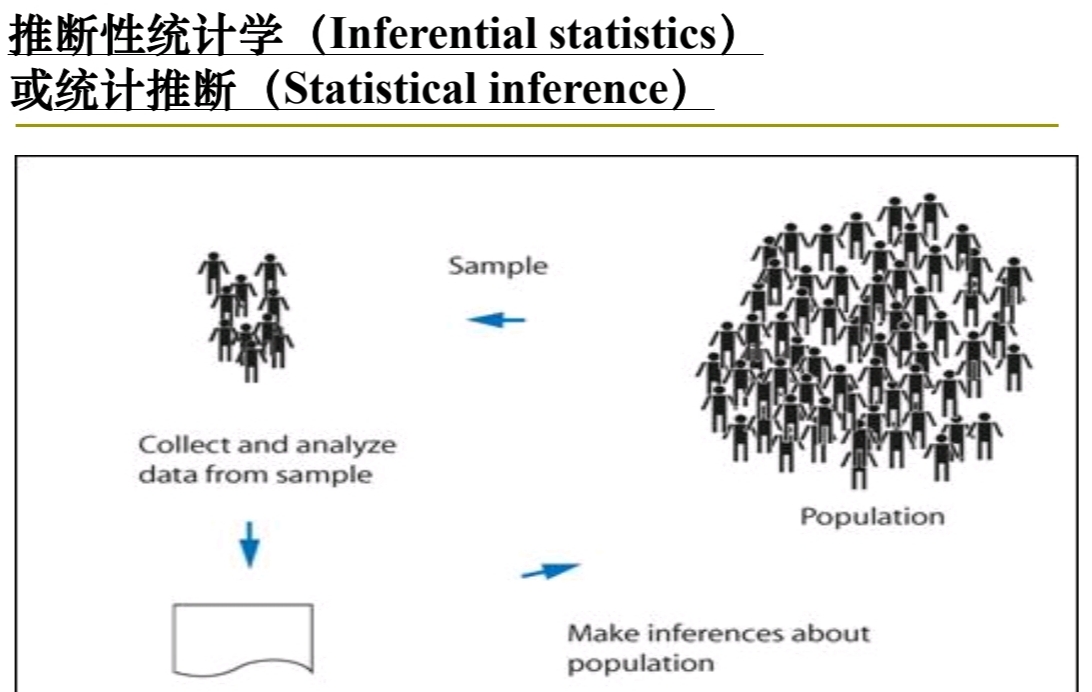

Statistical Inference: \(\large Sample\ \leftrightarrow\ Population\)
What is SI(统计推断)
SI(统计推断) 是统计学、数据分析和数据科学领域的一个基本概念,
是 样本推导出的数据与 更广大总体的参数之间的桥梁。
它涉及使用由样本推导出的数据 对 更大的群(总)体 进行 概括或预测。
因为它能得出有意义的结论,而无需分析整个总体(这通常是不可能的)。
SI(统计推断) 依赖于 Probability Theory(概率论的原理),
使从业者能够quantify uncertainty(量化不确定性)**并根据 经验与证据 做出 理智的决策.
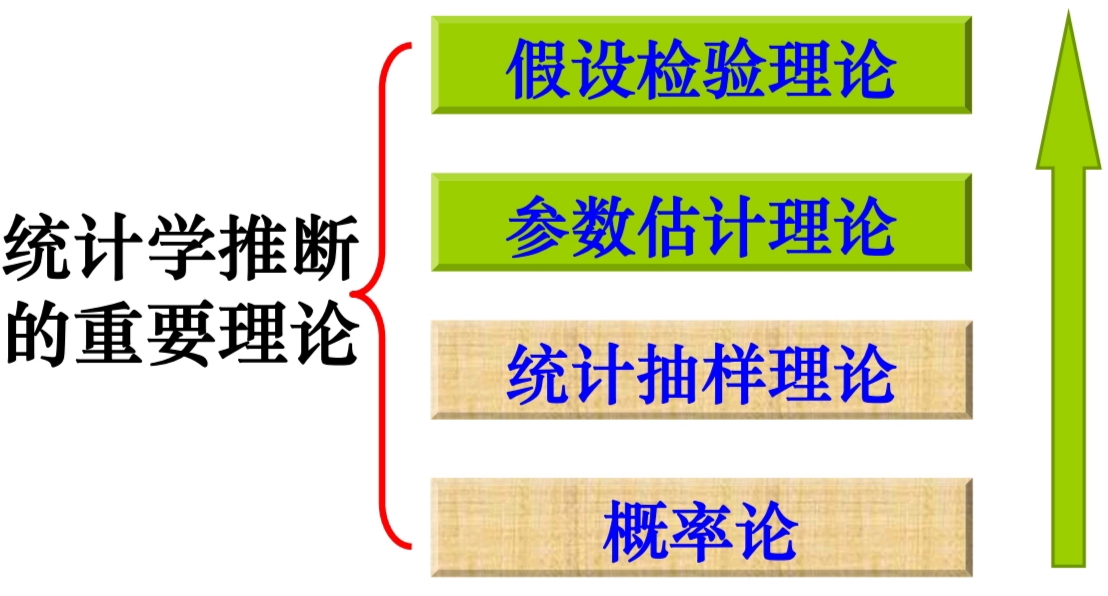
SI(统计推断)的类型
SI(统计推断) 主要有两种类型:
Estimation: 根据样本数据确定总体的特征;
- Point Estimation: 提供 总体的参数 的 单一值估计;
- Confidence Interval: 提供 可能包含该参数 的 一系列值(包括区间),
反映抽样固有的不确定性。
Testing Hypothesis: 一种用于检验 有关总体参数 的 假设或主张 的方法。
- H0: Null Hypothesis
- HA: Alternative Hypothesis
然后** 使用样本数据** 确定 是否有足够的证据 能 拒绝H0(零假设) 而 支持HA(备择假设)。
统计推断的应用
统计推断在各个领域都有广泛的应用,包括医疗保健、社会科学、营销和金融。例如,在医疗保健领域,研究人员使用统计推断根据临床试验数据确定新疗法的有效性。在营销领域,企业通过调查和实验分析消费者行为,以根据数据做出有关产品发布和广告策略的决策。从样本数据中得出有效结论的能力对于在这些领域和许多其他领域做出明智的决策至关重要。
统计推断的局限性
虽然统计推断是一种强大的工具,但它并非没有局限性。一个显著的局限性是依赖于样本代表总体的假设。如果样本有偏差或不是随机选择的,则得出的推断可能无效。此外,统计推断通常假设数据遵循特定分布,例如正态分布,但在实践中可能并不总是成立。研究人员必须谨慎解释并考虑其分析的背景,以避免得出误导性结论。
结论
统计推断是数据分析和科学研究的基石,使从业者能够根据样本数据做出明智的决策。通过理解估计、假设检验的原理以及 p 值和置信区间的相关概念,研究人员可以从有限的数据中有效地得出有关总体的结论。尽管统计推断存在局限性,但它仍然是提取见解和指导各个领域决策的重要工具。
Estimation
点估计
点估计是一种基于样本数据提供对总体参数的最佳猜测的技术。例如,如果研究人员想要估计某个城市成年男性的平均身高,他们可能会抽取一些男性样本并计算平均身高。这个平均值可作为人口平均身高的点估计值。但是,如果点估计不考虑数据中的变异性,则可能会产生误导。因此,它通常伴随着置信区间,从而更全面地反映出估计的可靠性。
置信区间
置信区间是统计推断的重要组成部分,它提供了人口参数可能落入的一系列值。例如,如果成年男性平均身高的 95% 置信区间计算为 (175 cm, 180 cm),则表明真实平均身高在此范围内的概率为 95%。置信区间的宽度受样本大小和数据变异性的影响;样本越大,区间越窄,表明估计值越精确。了解置信区间对于解释统计分析结果和做出明智决策至关重要。
Testing Hypothesis
假设检验
假设检验是一种系统方法,用于评估有关总体参数的主张。它首先要制定两个相互竞争的假设:零假设 (H0),表示没有影响或没有差异的陈述,以及备择假设 (H1),表示存在影响或差异。研究人员收集样本数据并进行统计测试,以确定证据是否足以拒绝零假设。常见的测试包括 t 检验、卡方检验和方差分析,每种方法都适用于不同类型的数据和研究问题。
P 值和显著性水平
在假设检验中,p 值在确定结果的显著性方面起着至关重要的作用。p 值表示假设零假设为真,获得至少与观察到的结果一样极端的结果的概率。p 值越小,反对零假设的证据就越强。研究人员通常将 p 值与预定的显著性水平 (alpha) 进行比较,该水平通常设置为 0.05。如果 p 值小于 alpha,则拒绝零假设,表明观察到的效应具有统计显著性。了解 p 值对于解释假设检验的结果和得出数据驱动的结论至关重要。
假设检验中的错误类型
统计推断并非没有缺陷,特别是在假设检验中,可能会出现两种类型的错误:第一类错误和第二类错误。当错误地拒绝零假设时,就会发生第一类错误,从而得出假阳性结论。相反,当零假设实际上是错误的,但未被拒绝时,就会发生第二类错误,从而错失识别真实效应的机会。在实验设计和统计结果解释中,平衡这些错误的风险是一个关键的考虑因素。
SciTech-Mathmatics-Probability+Statistics: Statistical Inference统计推断- Estimation估计 + Testing Hypotheses假设检验的更多相关文章
- 加州大学伯克利分校Stat2.3x Inference 统计推断学习笔记: Section 2 Testing Statistical Hypotheses
Stat2.3x Inference(统计推断)课程由加州大学伯克利分校(University of California, Berkeley)于2014年在edX平台讲授. PDF笔记下载(Acad ...
- 统计推断(statistical inference)
样本是统计推断的依据: 统计推断的基本问题可以分为两大类: 估计问题 点估计, 区间估计 假设检验 1. 点估计 设总体 X 的分布函数 F(x;θ) 的形式已知,θ 是待估参数.X1,X2,-,Xn ...
- 读书笔记 1 of Statistics :Moments and Moment Generating Functions (c.f. Statistical Inference by George Casella and Roger L. Berger)
Part 1: Moments Definition 1 For each integer $n$, the nth moment of $X$, $\mu_n^{'}$ is \[\mu_{n}^{ ...
- 《统计推断(Statistical Inference)》读书笔记——第6章 数据简化原理
在外行眼里统计学家经常做的一件事就是把一大堆杂七杂八的数据放在一起,算出几个莫名其妙的数字,然后再通过这些数字推理出貌似很靠谱的结论,简直就像是炼金术士用“贤者之石”把一堆石头炼成了金矿.第六章,应该 ...
- 《统计推断(Statistical Inference)》读书笔记——第5章 随机样本的性质
有了前四章知识的铺垫,第五章进入了统计研究的正题——样本的研究.样本可以说是统计学研究中最基本的对象,样本的数学性质也是最重要的研究课题,统计学的一大任务就是从一大堆样本中提取出有价值的知识,正如对原 ...
- 《统计推断(Statistical Inference)》读书笔记——第4章 统计分布族
数据分析工作中最常和多维随机变量打交道,第四章介绍了多维随机变量的基本知识,其中核心概念是条件分布和条件概率.条件分布和条件概率可以抽象出条件期望的概念,在随机分析的研究中,理解随机积分和鞅理论和关键 ...
- 《统计推断(Statistical Inference)》读书笔记——第3章 统计分布族
在科学研究中最重要的两种思维范式是“简化”和“还原”,所谓“简化”是指人依据不太复杂的,可理解的规律认识世界:所谓“还原”是指任何复杂的现象归根结底可以由若干简单的机制解释.各种统计分布族就是统计学中 ...
- 《统计推断(Statistical Inference)》读书笔记——第2章 变换与期望
第二章引入了两个重要问题,随机变量的期望和随机变量的变换.期望又引申出“矩”的概念,矩是统计学理论分析的一个重要关键词,而随机变量的变换是研究复杂统计现象的重要工具.下面是这一章的思维导图
- 《统计推断(Statistical Inference)》读书笔记——第1章 概率论
第一章介绍了基本的概率论知识,以下是这一章的思维导图
- 加州大学伯克利分校Stat2.3x Inference 统计推断学习笔记: Section 3 One-sample and two-sample tests
Stat2.3x Inference(统计推断)课程由加州大学伯克利分校(University of California, Berkeley)于2014年在edX平台讲授. PDF笔记下载(Acad ...
随机推荐
- qwen3 惊喜发布,用 ollama + solon ai (java) 尝个鲜
qwen3 惊喜发布了,帅!我们用 ollama 和 solon ai (java) 也来尝个鲜. 1.先用 ollama 拉取模型 听说,在个人电脑上用 4b 的参数,效果就很好了. ollama ...
- Spring基于注解的CRUD
目录 Spring基于注解的CRUD 代码实现 测试 方式一:使用Junit方式测试 方式二:使用@RunWith(SpringJUnit4ClassRunner.class)注解测试 Spring基 ...
- 基于ThinkPHP5知识付费系统AntPayCMS
历时6个月开发基于ThinkPHP5.1知识付费系统AntPayCMS,自己作IT开发已经10年,一直想自己开发自己的系统,虽然看网上也有很多知识付费类的网站的,但基于TP基本很少,而且自己也一直想做 ...
- Excel工具类之“参数汇总”
一.SXSSFWorkbook技术 1.冻结行数 代码 SXSSFWorkbook wb = new SXSSFWorkbook(); SXSSFSheet sheet = wb.createShee ...
- K8s 部署一套 MySQL 集群
一般情况下 Kubernetes 可以通过 ReplicaSet 以一个 Pod 模板创建多个 pod 副本,但是它们都是无状态的,任何时候它们都可以被一个全新的 pod 替换.然而有状态的 pod ...
- 使用php的openssl_encrypt和python的pycrypt进行跨语言的对称加密和解密问题
最近有一个业务需求,需要前端传递一个密码到后端,期间要对传递的密码通过进行对称加密,我们约定使用成熟的AES加密方法. 前端使用php,后端用python,但是发现前端兄弟加密后的字符串,在pytho ...
- C#正则之获取命名组所有捕获的数据
static void ParseTest(string str) { Regex reg = new Regex(@"(?<num>\d+)(?<sg>[_!$#] ...
- PyYaml简单学习
YAML是一种轻型的配置文件的语言,远比JSON格式方便,方便人类读写,它通过缩进来表示结构,很具有Python风格. 安装:pip insall pyyaml YAML语法 文档 YAML数据流是0 ...
- AI智能体策略FunctionCalling和ReAct有什么区别?
Dify 内置了两种 Agent 策略:Function Calling 和 ReAct,但二者有什么区别呢?在使用时又该如何选择呢?接下来我们一起来看. 1.Function Calling Fun ...
- 第6讲、全面拆解Encoder、Decoder内部模块
全面拆解 Transformer 架构:Encoder.Decoder 内部模块解析(附流程图小测验) 关键词:Transformer.Encoder.Decoder.Self-Attention.M ...